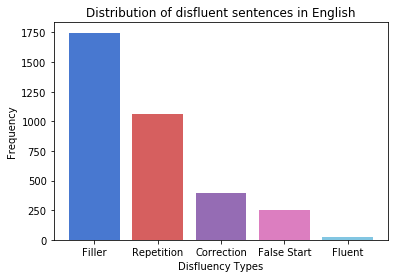
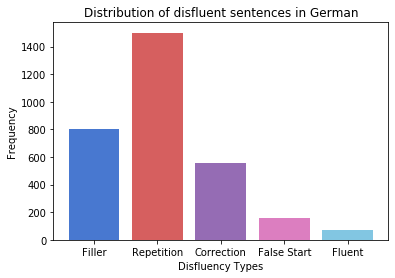
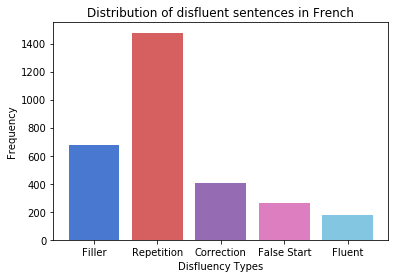
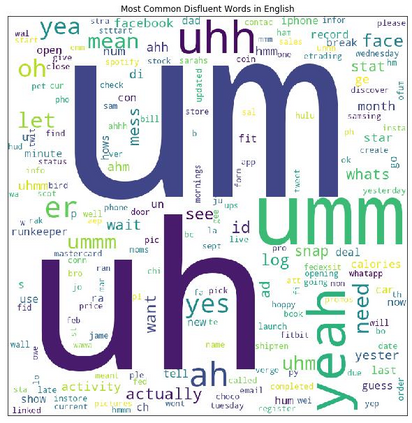
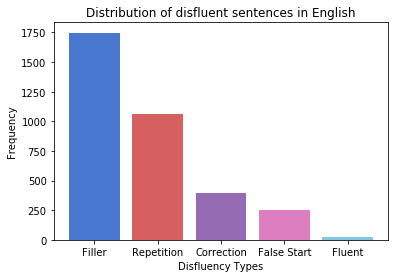
Disfluency correction (DC) is the process of removing disfluent elements like fillers, repetitions and corrections from spoken utterances to create readable and interpretable text. DC is a vital post-processing step applied to Automatic Speech Recognition (ASR) outputs, before subsequent processing by downstream language understanding tasks. Existing DC research has primarily focused on English due to the unavailability of large-scale open-source datasets. Towards the goal of multilingual disfluency correction, we present a high-quality human-annotated DC corpus covering four important Indo-European languages: English, Hindi, German and French. We provide extensive analysis of results of state-of-the-art DC models across all four languages obtaining F1 scores of 97.55 (English), 94.29 (Hindi), 95.89 (German) and 92.97 (French). To demonstrate the benefits of DC on downstream tasks, we show that DC leads to 5.65 points increase in BLEU scores on average when used in conjunction with a state-of-the-art Machine Translation (MT) system. We release code to run our experiments along with our annotated dataset here.
翻译:暂无翻译