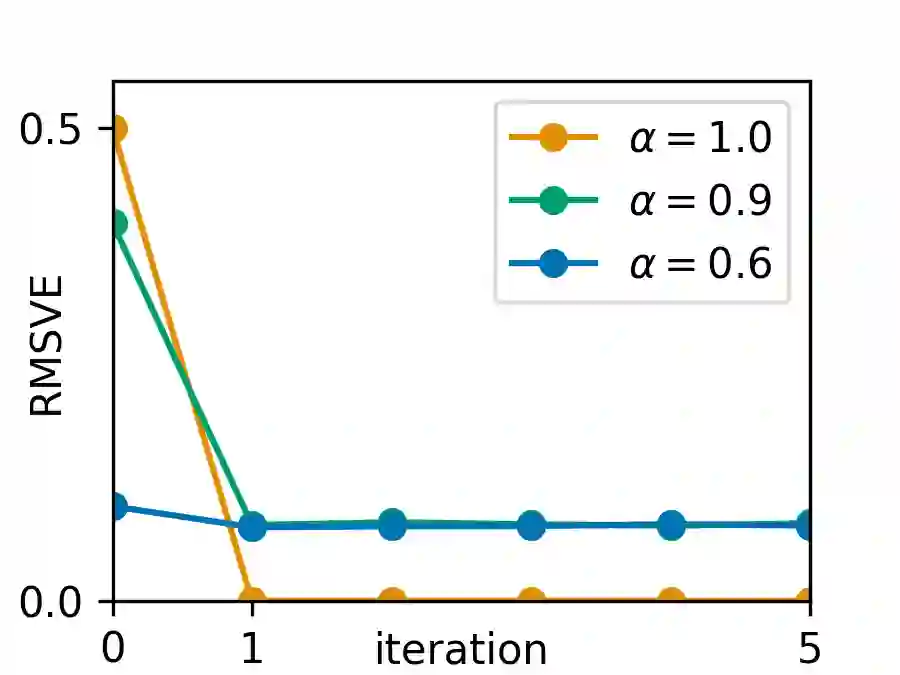
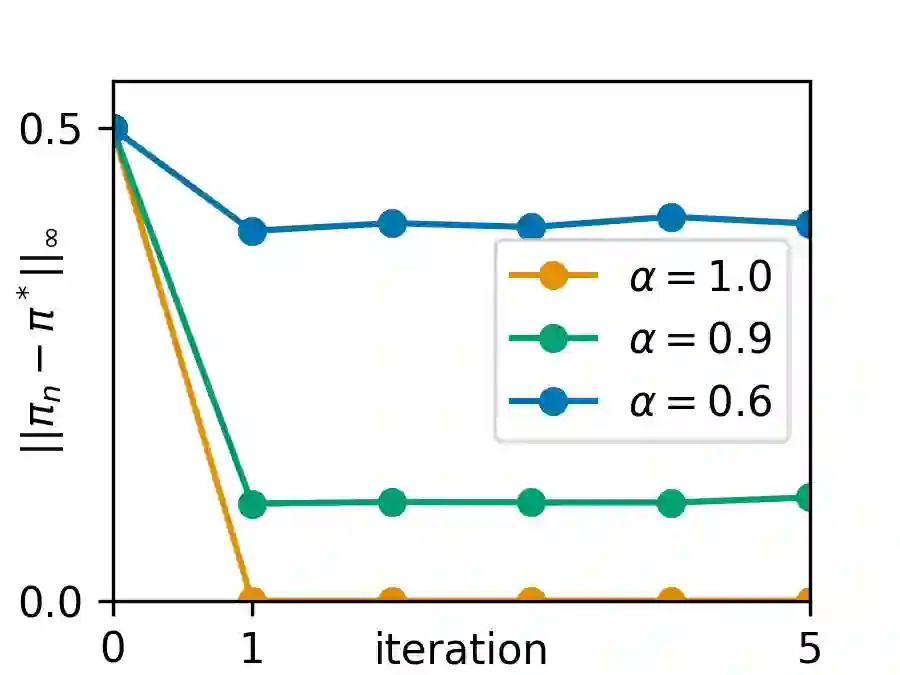
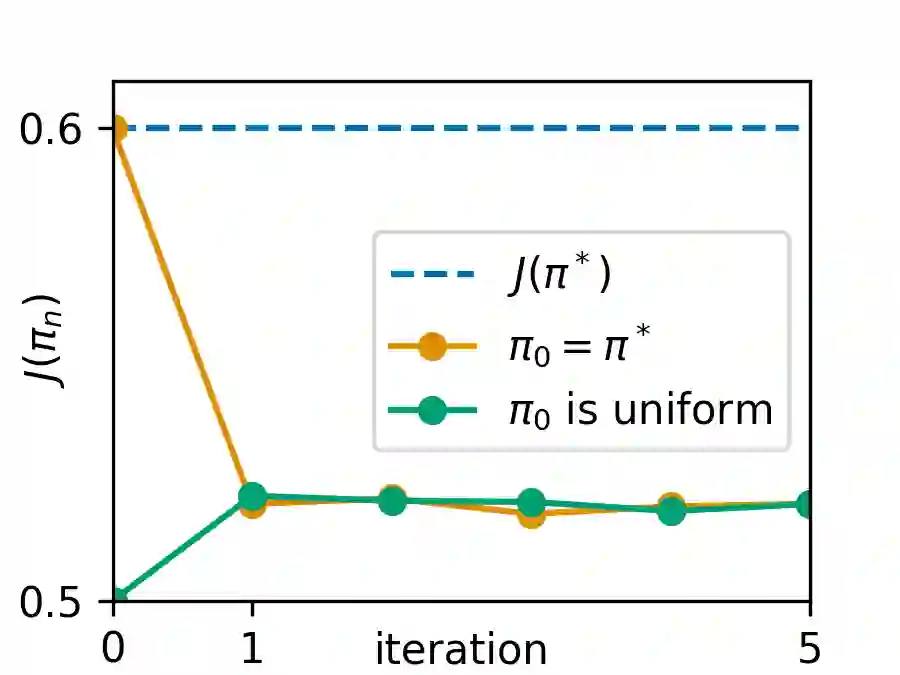
Upside-Down Reinforcement Learning (UDRL) is an approach for solving RL problems that does not require value functions and uses only supervised learning, where the targets for given inputs in a dataset do not change over time. Ghosh et al. proved that Goal-Conditional Supervised Learning (GCSL) -- which can be viewed as a simplified version of UDRL -- optimizes a lower bound on goal-reaching performance. This raises expectations that such algorithms may enjoy guaranteed convergence to the optimal policy in arbitrary environments, similar to certain well-known traditional RL algorithms. Here we show that for a specific episodic UDRL algorithm (eUDRL, including GCSL), this is not the case, and give the causes of this limitation. To do so, we first introduce a helpful rewrite of eUDRL as a recursive policy update. This formulation helps to disprove its convergence to the optimal policy for a wide class of stochastic environments. Finally, we provide a concrete example of a very simple environment where eUDRL diverges. Since the primary aim of this paper is to present a negative result, and the best counterexamples are the simplest ones, we restrict all discussions to finite (discrete) environments, ignoring issues of function approximation and limited sample size.
翻译:位于上方的强化学习(UDRL)是解决RL问题的一种方法,它不需要价值功能,只使用监督学习,而数据集中特定投入的具体目标不会随时间而改变。Ghosh等人证明,目标有条件监督学习(GCSL) -- -- 可以被视为UDRL的简化版本 -- -- 优化了目标影响性能的较低约束。这提高了这种算法在任意环境中与最佳政策之间的趋同程度的预期,类似于某些众所周知的传统RL算法。我们在这里展示了一种非常简单的环境,其中的eDRL算法(eUDL,包括GCSL)有差异,但情况并非如此,并给出了这一限制的原因。为了做到这一点,我们首先将eUDRL改写成一个有用的缩略图,作为循环性政策更新。这一提法有助于使其与广泛种类的干扰性环境的最佳政策脱钩。最后,我们提供了一个非常简单的环境,即eUDRL最简单的环境是不同的环境。由于本文的首要目的就是将一个有限的试样,因此,我们所要限制的是,我们所要选择的极小的极小的排序。