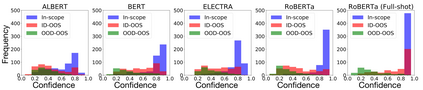
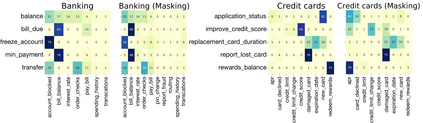
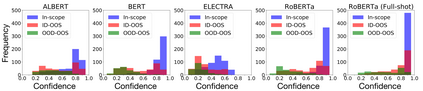
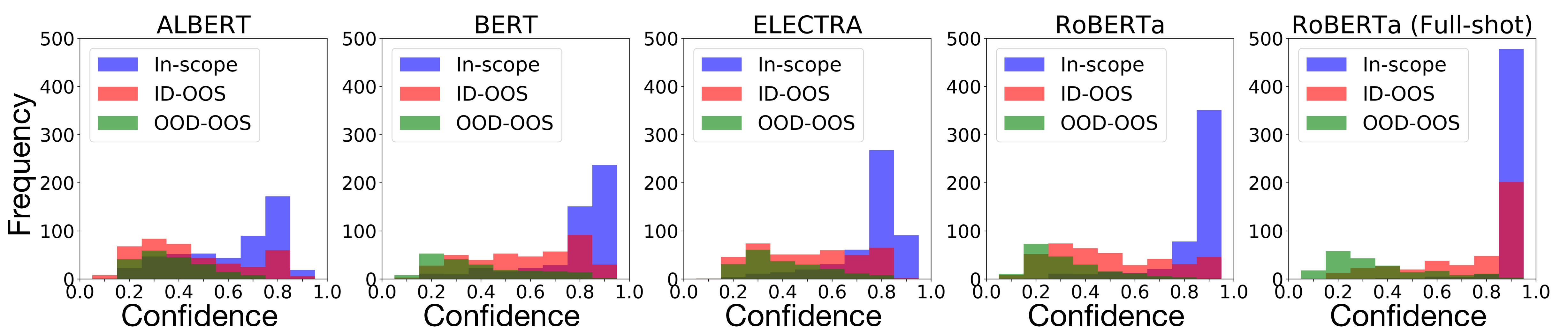
Pretrained Transformer-based models were reported to be robust in intent classification. In this work, we first point out the importance of in-domain out-of-scope detection in few-shot intent recognition tasks and then illustrate the vulnerability of pretrained Transformer-based models against samples that are in-domain but out-of-scope (ID-OOS). We empirically show that pretrained models do not perform well on both ID-OOS examples and general out-of-scope examples, especially on fine-grained few-shot intent detection tasks. To figure out how the models mistakenly classify ID-OOS intents as in-scope intents, we further conduct analysis on confidence scores and the overlapping keywords and provide several prospective directions for future work. We release the relevant resources to facilitate future research.
翻译:在这项工作中,我们首先指出在几发目标识别任务中进行内部外探测的重要性,然后说明预先培训的变异模型对内部但外部(ID-OOS)样本的脆弱性。我们从经验上表明,预先培训的模型在ID-OOS实例和一般外部实例,特别是细微微微微微粒目标检测任务方面效果不佳。为了查明这些模型如何错误地将ID-OOS意图归类为内部意图,我们进一步分析信任分数和重叠关键字,并为未来工作提供若干未来方向。我们释放了相关资源,以促进未来的研究。