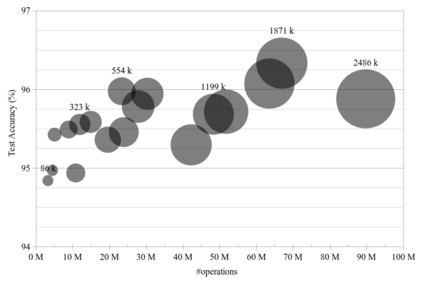
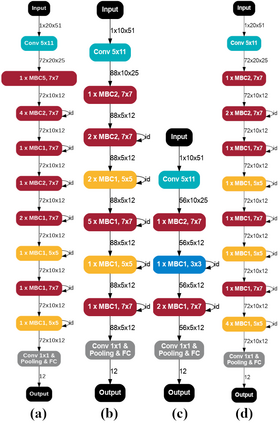
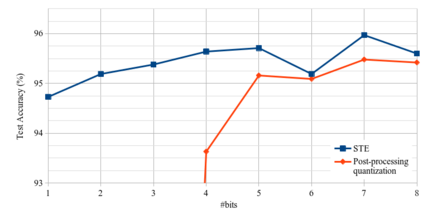
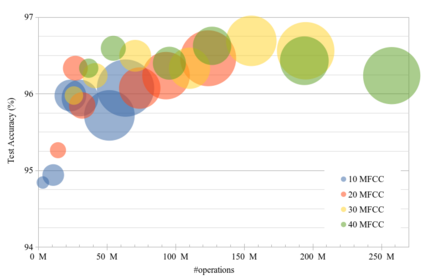
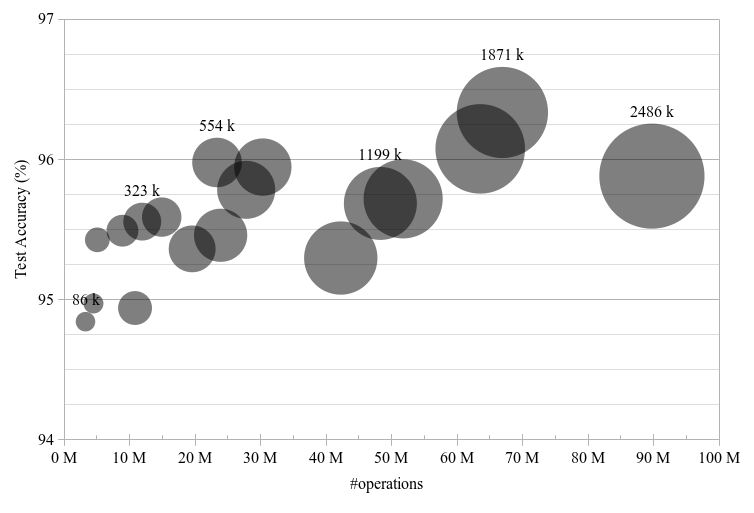
This paper introduces neural architecture search (NAS) for the automatic discovery of small models for keyword spotting (KWS) in limited resource environments. We employ a differentiable NAS approach to optimize the structure of convolutional neural networks (CNNs) to maximize the classification accuracy while minimizing the number of operations per inference. Using NAS only, we were able to obtain a highly efficient model with 95.4% accuracy on the Google speech commands dataset with 494.8 kB of memory usage and 19.6 million operations. Additionally, weight quantization is used to reduce the memory consumption even further. We show that weight quantization to low bit-widths (e.g. 1 bit) can be used without substantial loss in accuracy. By increasing the number of input features from 10 MFCC to 20 MFCC we were able to increase the accuracy to 96.3% at 340.1 kB of memory usage and 27.1 million operations.
翻译:本文引入了神经结构搜索(NAS),用于在有限的资源环境中自动发现用于识别关键词的小模型(KWS),我们采用了不同的NAS方法优化进化神经网络的结构(CNNs),以最大限度地提高分类准确性,同时最大限度地减少每次推断的操作数量。我们仅使用NAS,就能在谷歌语音指令数据集上获得一个高度高效的模型,精确率为95.4%,存储用量为494.8千B和1 960万个操作。此外,重量量化还用来进一步减少内存消耗。我们表明,可以使用低位微宽度的重量定量(例如1位),而不会大大降低准确性。通过将输入特性从10个MFCC增加到20个MFCC,我们得以在记忆用量的340.1千B和2 710万个操作中将精度提高到96.3%。