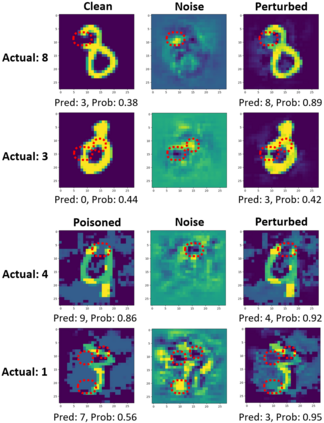
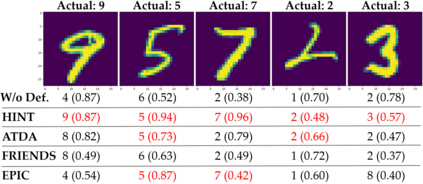
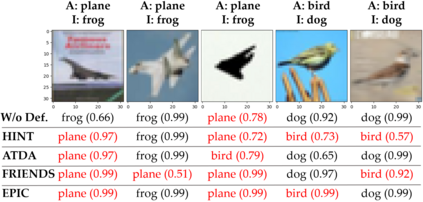
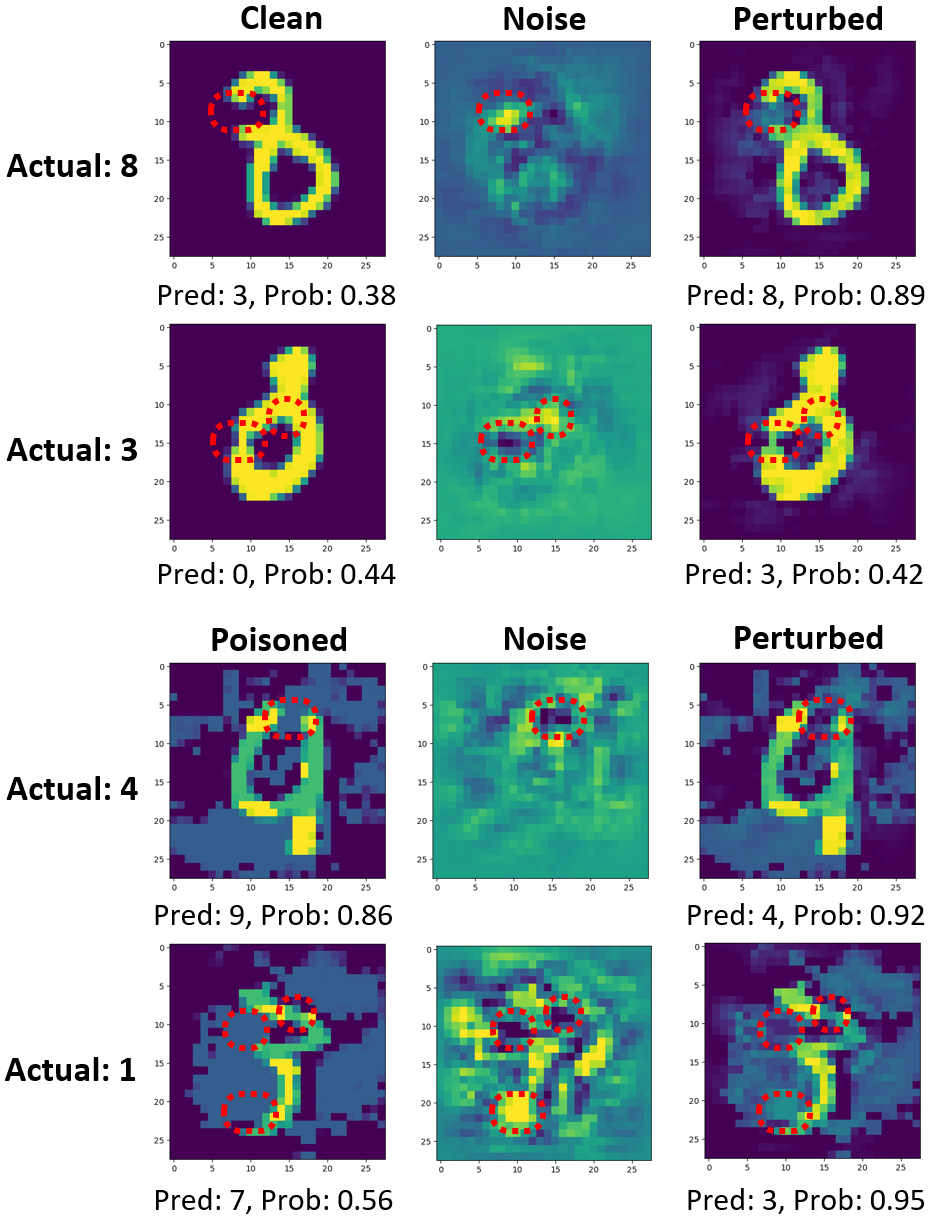
While numerous defense methods have been proposed to prohibit potential poisoning attacks from untrusted data sources, most research works only defend against specific attacks, which leaves many avenues for an adversary to exploit. In this work, we propose an efficient and robust training approach to defend against data poisoning attacks based on influence functions, named Healthy Influential-Noise based Training. Using influence functions, we craft healthy noise that helps to harden the classification model against poisoning attacks without significantly affecting the generalization ability on test data. In addition, our method can perform effectively when only a subset of the training data is modified, instead of the current method of adding noise to all examples that has been used in several previous works. We conduct comprehensive evaluations over two image datasets with state-of-the-art poisoning attacks under different realistic attack scenarios. Our empirical results show that HINT can efficiently protect deep learning models against the effect of both untargeted and targeted poisoning attacks.
翻译:暂无翻译