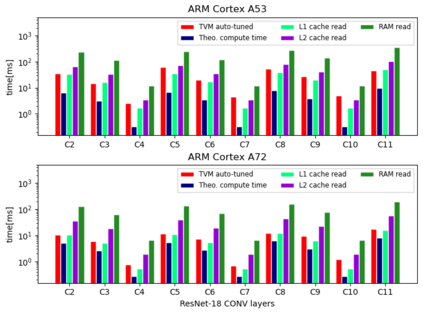
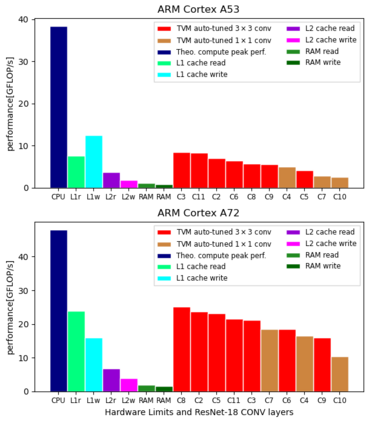
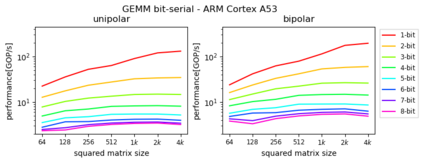
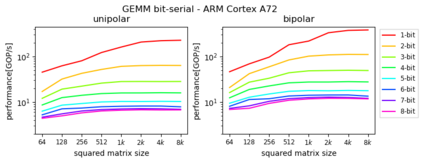
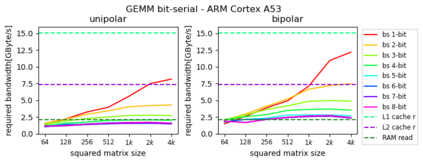
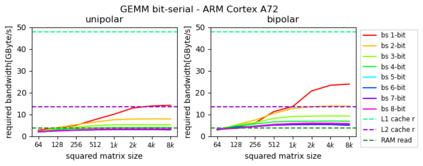
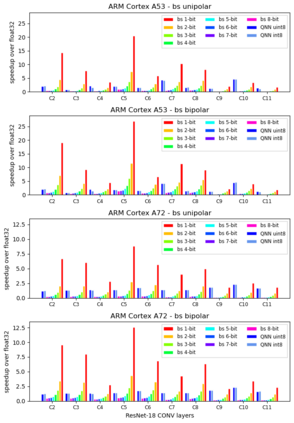
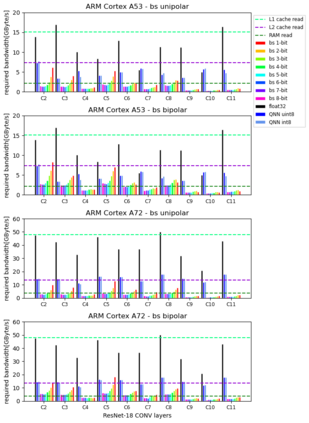
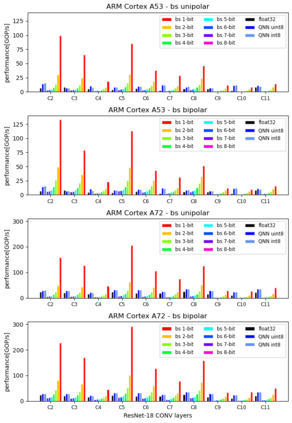
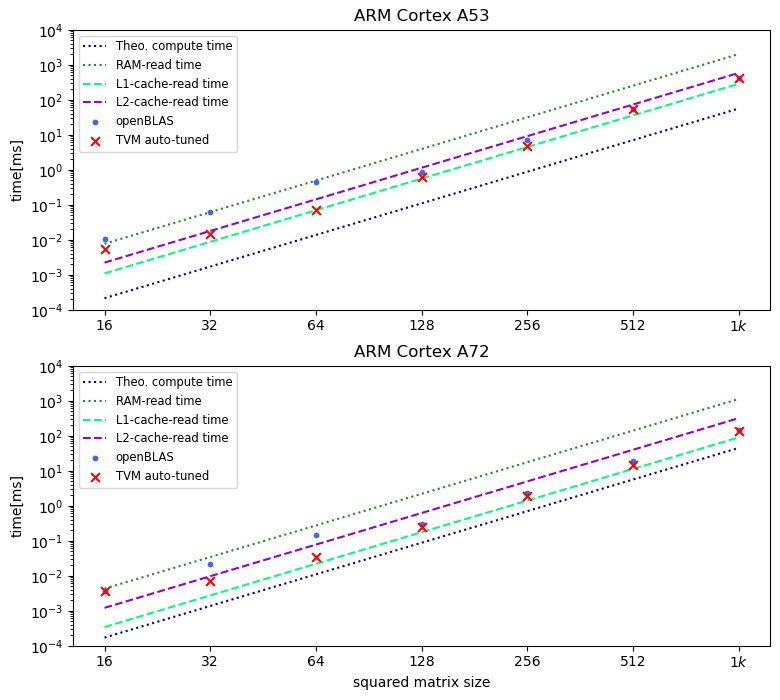
Machine Learning compilers like TVM allow a fast and flexible deployment on embedded CPUs. This enables the use of non-standard operators, which are common in ML compression techniques. However, it is necessary to understand the limitations of typical compute-intense operators in ML workloads to design a proper solution. This is the first in-detail analysis of dense and convolution operators, generated with TVM, that compares to the fundamental hardware limits of embedded ARM processors. Thereby it explains the gap between computational peak performance, theoretical and measured, and real-world state-of-the-art results, created with TVM and openBLAS. Instead, one can see that single-precision general matrix multiply (GEMM) and convolutions are bound by L1-cache-read bandwidth. Explorations of 8-bit and bit-serial quantized operators show that quantization can be used to achieve relevant speedups compared to cache-bound floating-point operators. However, the performance of quantized operators highly depends on the interaction between data layout and bit packing.
翻译:类似 TVM 的机器学习编译器可以快速灵活地在嵌入式CPU上部署。 这样可以使用非标准操作器, 这在 ML 压缩技术中很常见。 但是, 有必要理解 ML 工作量中典型的计算强度操作器的局限性, 以便设计一个合适的解决方案。 这是与嵌入式ARM 处理器的基本硬件限制相比, 由 TVM 生成的密度和卷变操作器的首次详细分析。 由此可以解释计算峰值性能、 理论性能和测量性能与现实世界最新结果之间的差距, 由 TVM 和 OpenBLAS 创建。 相反, 量化操作器的性能高度取决于数据布局和位式包装之间的交互作用 。