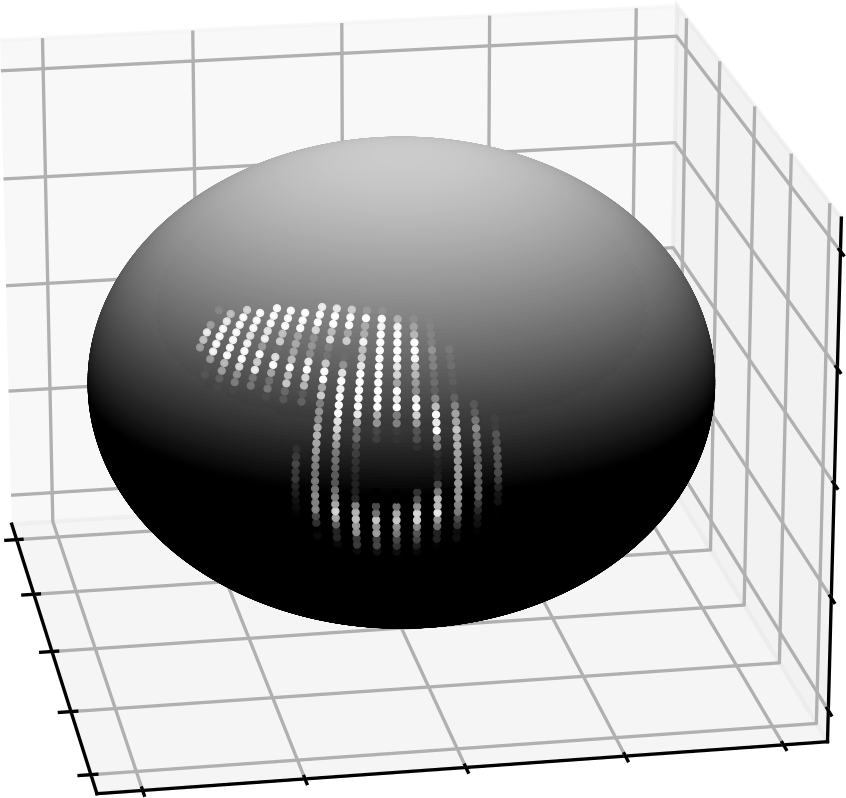
We analyze the role of rotational equivariance in convolutional neural networks (CNNs) applied to spherical images. We compare the performance of the group equivariant networks known as S2CNNs and standard non-equivariant CNNs trained with an increasing amount of data augmentation. The chosen architectures can be considered baseline references for the respective design paradigms. Our models are trained and evaluated on single or multiple items from the MNIST or FashionMNIST dataset projected onto the sphere. For the task of image classification, which is inherently rotationally invariant, we find that by considerably increasing the amount of data augmentation and the size of the networks, it is possible for the standard CNNs to reach at least the same performance as the equivariant network. In contrast, for the inherently equivariant task of semantic segmentation, the non-equivariant networks are consistently outperformed by the equivariant networks with significantly fewer parameters. We also analyze and compare the inference latency and training times of the different networks, enabling detailed tradeoff considerations between equivariant architectures and data augmentation for practical problems. The equivariant spherical networks used in the experiments will be made available at https://github.com/JanEGerken/sem_seg_s2cnn .
翻译:我们分析了用于球形图像的神经神经网络(CNNs)中旋转等差的作用。我们比较了称为S2CNNNs和标准非等差型CNN的集团等差网络的性能,并用越来越多的数据增强来培训。选择的架构可以被视为各自设计范式的基准参考。我们的模型在从MNIST 或时装MNIST 数据集中预测到球体的单项或多项项目上经过培训和评价。关于图像分类的任务,它本质上是旋转不定的。我们发现,通过大幅提高数据增强量和网络规模,标准CNNs至少可以达到与等差网络相同的性能。相比之下,对于本质上的语系分割任务,非等差性网络始终比等异的网络多,参数要少得多。我们还分析并比较了不同网络的推推推定的纬度和训练时间,从而使得标准CNNPN能够实现与等差网络至少达到与等差性网络相同的性运行。在实用性/变差结构中使用的数据问题中,将进行详细的贸易考虑。