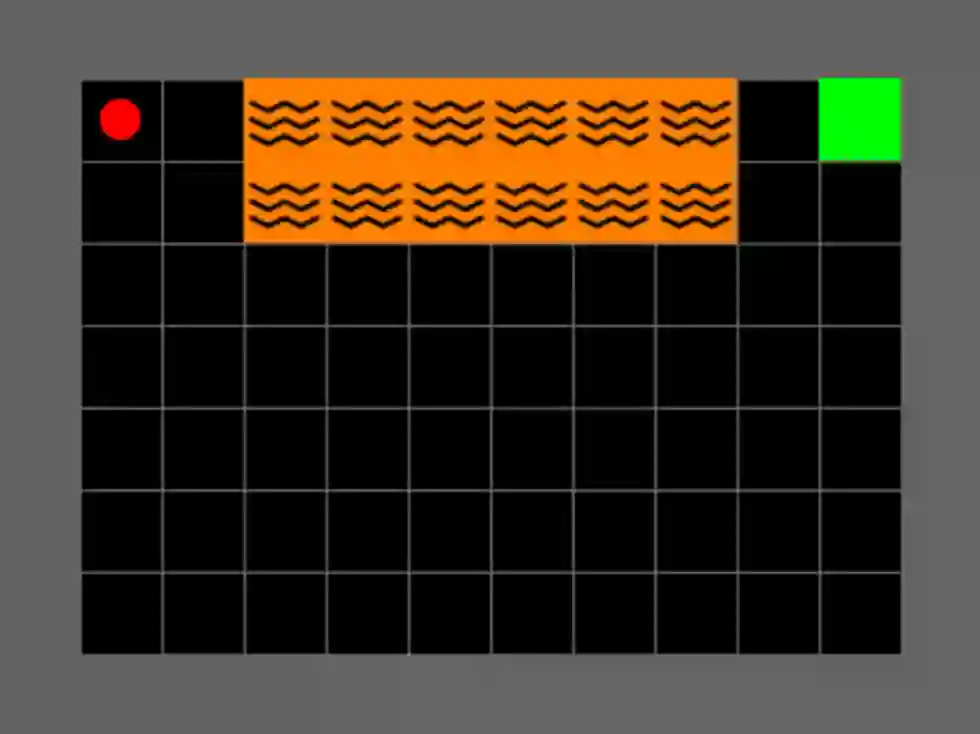
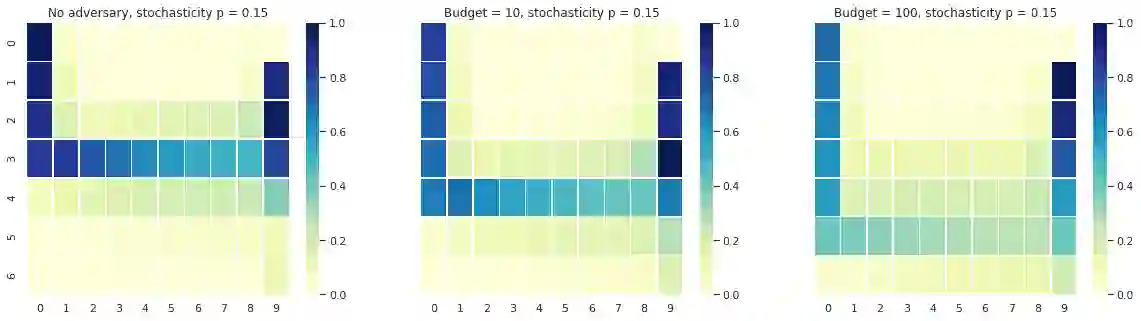
In this paper we present a risk-averse reinforcement learning (RL) method called Conditional value-at-risk Adversarial Reinforcement Learning (CARL). To the best of our knowledge, CARL is the first game formulation for Conditional Value-at-Risk (CVaR) RL. The game takes place between a policy player and an adversary that perturbs the policy player's state transitions given a finite budget. We prove that, at the maximin equilibrium point, the learned policy is CVaR optimal with a risk tolerance explicitly related to the adversary's budget. We provide a gradient-based training procedure to solve CARL by formulating it as a zero-sum Stackelberg Game, enabling the use of deep reinforcement learning architectures and training algorithms. Finally, we show that solving the CARL game does lead to risk-averse behaviour in a toy grid environment, also confirming that an increased adversary produces increasingly cautious policies.
翻译:在本文中,我们展示了一种反风险强化学习(RL)方法,称为条件值风险抗反强化学习(CARL)。据我们所知,CARL是有条件值抗风险强化学习(CVaR)RL的第一个游戏配方。游戏发生在一个政策玩家和一个干扰政策玩家状态过渡的对手之间,因为预算有限。我们证明,在最大平衡点,学习的政策是CVAR最佳的,其风险容忍度明确与对手的预算有关。我们提供了一种基于梯度的培训程序,通过将CARL编成零和 Stakkelberg 游戏来解决 CARL问题,从而使得能够使用深层强化学习架构和培训算法。最后,我们证明解决CARL游戏确实导致在保守网格环境中的风险规避行为,我们也证实,日益增强的对手产生了越来越谨慎的政策。