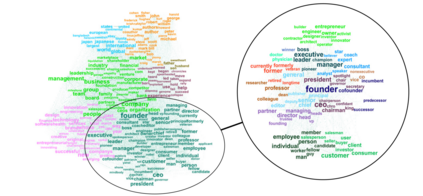
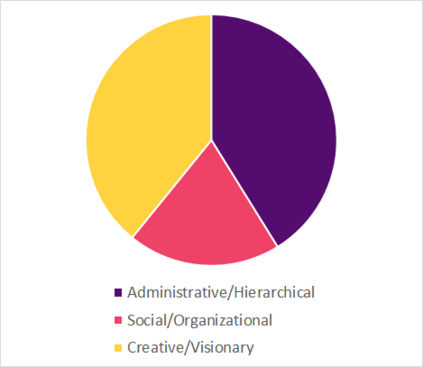
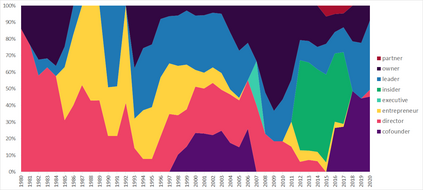
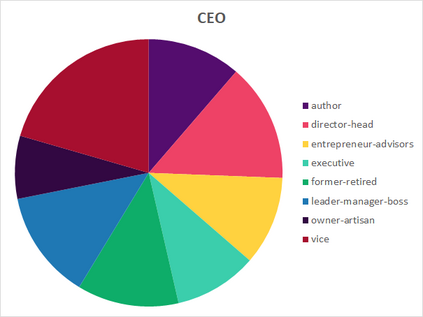
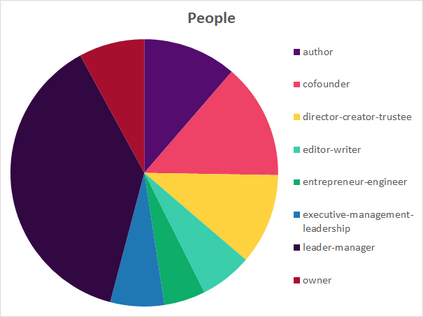
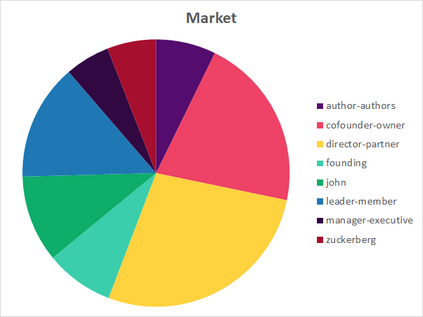
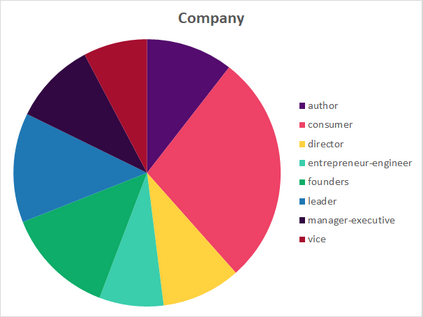
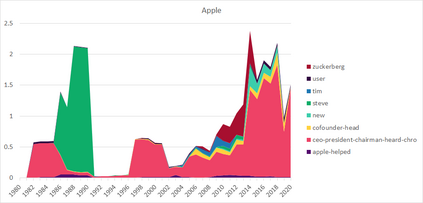
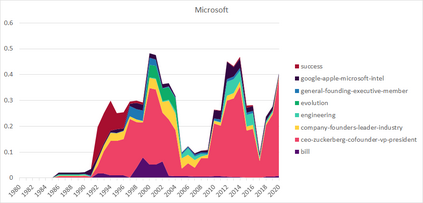
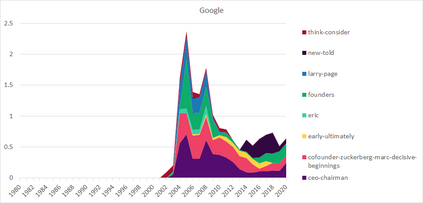
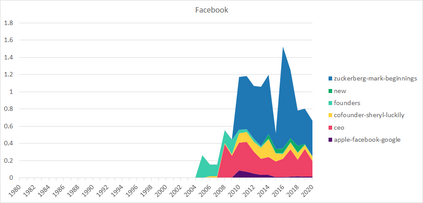
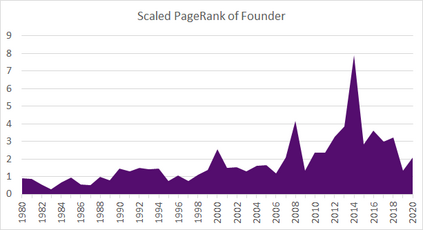
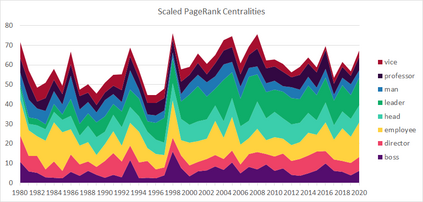
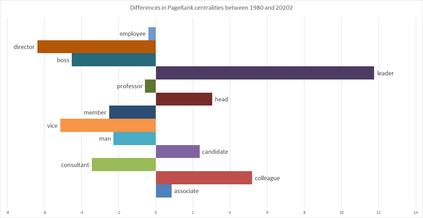
Much information available to applied researchers is contained within written language or spoken text. Deep language models such as BERT have achieved unprecedented success in many applications of computational linguistics. However, much less is known about how these models can be used to analyze existing text. We propose a novel method that combines transformer models with network analysis to form a self-referential representation of language use within a corpus of interest. Our approach produces linguistic relations strongly consistent with the underlying model as well as mathematically well-defined operations on them, while reducing the amount of discretionary choices of representation and distance measures. It represents, to the best of our knowledge, the first unsupervised method to extract semantic networks directly from deep language models. We illustrate our approach in a semantic analysis of the term "founder". Using the entire corpus of Harvard Business Review from 1980 to 2020, we find that ties in our network track the semantics of discourse over time, and across contexts, identifying and relating clusters of semantic and syntactic relations. Finally, we discuss how this method can also complement and inform analyses of the behavior of deep learning models.
翻译:应用研究人员可获得的大量信息都包含在书面语言或口头文字中。深语言模型,如BERT,在许多计算语言应用中取得了前所未有的成功。然而,这些模型如何用来分析现有文本却远不为人所知。我们提出了一个新颖的方法,将变压器模型与网络分析结合起来,形成一种在兴趣中以自我偏好的方式表达语言使用的语言。我们的方法产生了与基本模型以及数学上明确界定的语言关系,同时减少了代表和距离措施的自由裁量选择的数量。根据我们的知识,它代表着从深层语言模型中直接提取语义网络的第一种不受监督的方法。我们用“创建者”一词的语义分析来说明我们的方法。我们利用1980年至2020年整个哈佛商业评论的文集,发现我们的网络联系可以跟踪长期和跨背景的语义学的语义学,并查明和相关的语义学和合成关系组。最后,我们讨论了这一方法如何补充和启发对深层次学习模型行为的分析。