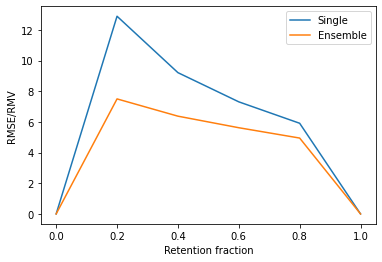
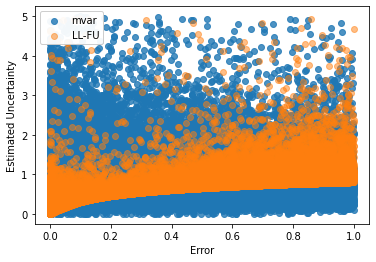
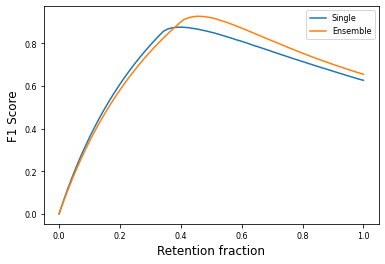
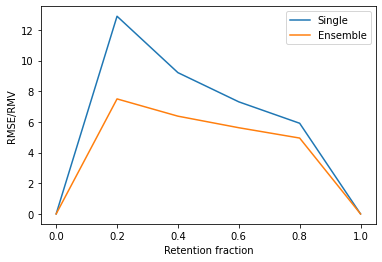
Most machine learning models operate under the assumption that the training, testing and deployment data is independent and identically distributed (i.i.d.). This assumption doesn't generally hold true in a natural setting. Usually, the deployment data is subject to various types of distributional shifts. The magnitude of a model's performance is proportional to this shift in the distribution of the dataset. Thus it becomes necessary to evaluate a model's uncertainty and robustness to distributional shifts to get a realistic estimate of its expected performance on real-world data. Present methods to evaluate uncertainty and model's robustness are lacking and often fail to paint the full picture. Moreover, most analysis so far has primarily focused on classification tasks. In this paper, we propose more insightful metrics for general regression tasks using the Shifts Weather Prediction Dataset. We also present an evaluation of the baseline methods using these metrics.
翻译:大多数机器学习模型的运作假设是,培训、测试和部署数据是独立的,分布相同(一.d.)。这一假设在自然环境中一般不正确。通常,部署数据受各种分布变化的影响。模型的性能与数据集分布的变化成正比。因此,有必要评估模型对分布变化的不确定性和稳健性,以便对其真实世界数据的预期性能作出现实的估计。目前缺乏评估不确定性和模型稳健性的方法,而且往往无法描绘全局。此外,迄今为止,大多数分析主要侧重于分类任务。在本文中,我们用变换天气预测数据集为一般回归任务提出了更具有洞察力的衡量标准。我们还用这些参数对基线方法进行了评估。