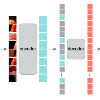
This paper revisits the standard pretrain-then-finetune paradigm used in computer vision for visual recognition tasks. Typically, state-of-the-art foundation models are pretrained using large scale (weakly) supervised datasets with billions of images. We introduce an additional pre-pretraining stage that is simple and uses the self-supervised MAE technique to initialize the model. While MAE has only been shown to scale with the size of models, we find that it scales with the size of the training dataset as well. Thus, our MAE-based pre-pretraining scales with both model and data size making it applicable for training foundation models. Pre-pretraining consistently improves both the model convergence and the downstream transfer performance across a range of model scales (millions to billions of parameters), and dataset sizes (millions to billions of images). We measure the effectiveness of pre-pretraining on 10 different visual recognition tasks spanning image classification, video recognition, object detection, low-shot classification and zero-shot recognition. Our largest model achieves new state-of-the-art results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%). Our study reveals that model initialization plays a significant role, even for web-scale pretraining with billions of images.
翻译:本文重新审视了计算机视觉中用于视觉识别任务的标准预先训练-微调范式。通常,利用数十亿张图像的大规模(弱)监督数据集对最先进的基础模型进行预训练。我们引入了一个额外的预先预训练阶段,该阶段简单易行,使用自监督的MAE技术初始化模型。虽然MAE仅被证明与模型大小相比,模型大小越大,但我们发现它也会随着训练数据集的大小而扩展。因此,我们基于MAE的预先预训练可以与模型和数据大小一起扩展,从而适用于训练基础模型。预先预训练始终可以改善各种模型尺度(百万到十亿级参数)和数据集大小(数百万到数十亿张图像)的模型收敛和下游转移性能。我们测量了预先预训练对10个不同的视觉识别任务的有效性,包括图像分类,视频识别,目标检测,低频点分类和零点识别。我们最大的模型在iNaturalist-18(91.3%),1-shot ImageNet-1k(62.1%)和Food-101的零点转移(96.0%)上实现了新的最先进结果。我们的研究揭示了模型初始化的重要性,即使是使用数十亿张图像进行网络级别预训练也是如此。