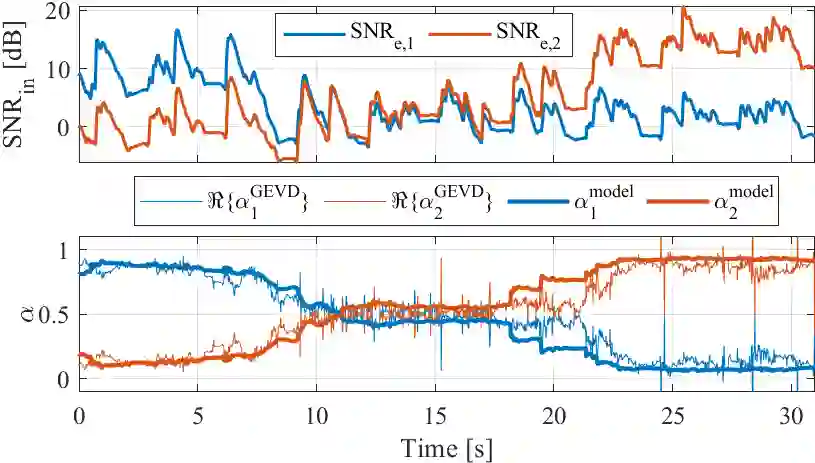
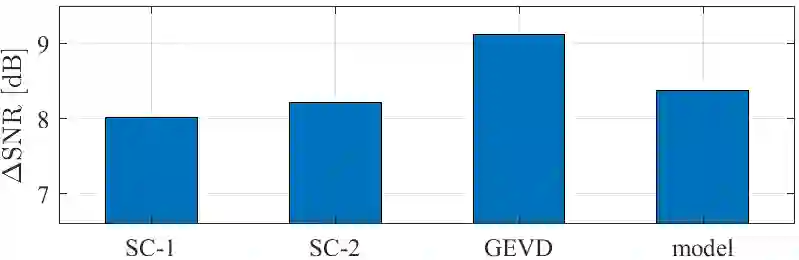
In many multi-microphone algorithms, an estimate of the relative transfer functions (RTFs) of the desired speaker is required. Recently, a computationally efficient RTF vector estimation method was proposed for acoustic sensor networks, assuming that the spatial coherence (SC) of the noise component between a local microphone array and multiple external microphones is low. Aiming at optimizing the output signal-to-noise ratio (SNR), this method linearly combines multiple RTF vector estimates, where the complex-valued weights are computed using a generalized eigenvalue decomposition (GEVD). In this paper, we perform a theoretical bias analysis for the SC-based RTF vector estimation method with multiple external microphones. Assuming a certain model for the noise field, we derive an analytical expression for the weights, showing that the optimal model-based weights are real-valued and only depend on the input SNR in the external microphones. Simulations with real-world recordings show a good accordance of the GEVD-based and the model-based weights. Nevertheless, the results also indicate that in practice, estimation errors occur which the model-based weights cannot account for.
翻译:在许多多麦克风算法中,需要估计理想发言者的相对转移功能(RTFs)。最近,为音响传感器网络提出了一个计算高效的RTF矢量估计方法,假设当地麦克风阵列和多个外部麦克风之间的噪音组成部分的空间一致性较低。这一方法旨在优化输出信号对噪音比率(SNR),线性地结合了多个RTF矢量估计,其中复杂价值的重量是使用通用电子数值分解法计算得出的。在本文中,我们对基于SC的RTF矢量估计方法进行了理论偏差分析,并配有多个外部麦克风。假设了某种声音场模式,我们对加权进行了分析,表明基于模型的最佳重量是真实价值的,仅取决于外部麦克风中输入的SRN。用真实世界记录模拟显示,基于GEVD的重量和基于模型的重量是良好的。然而,结果也表明,在实践中,基于模型的重量账户无法进行估算错误。