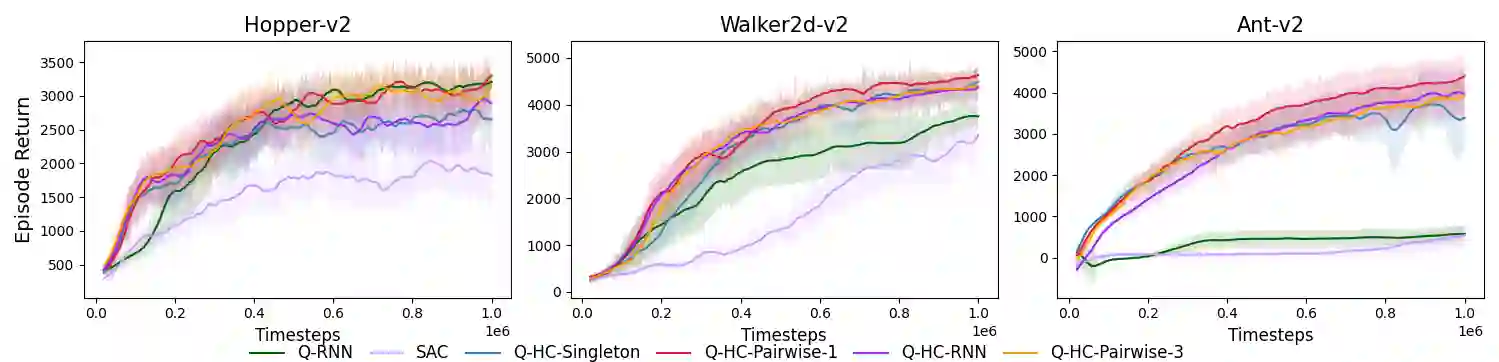
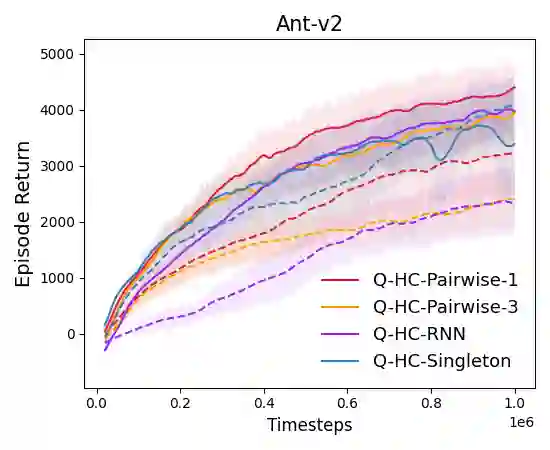
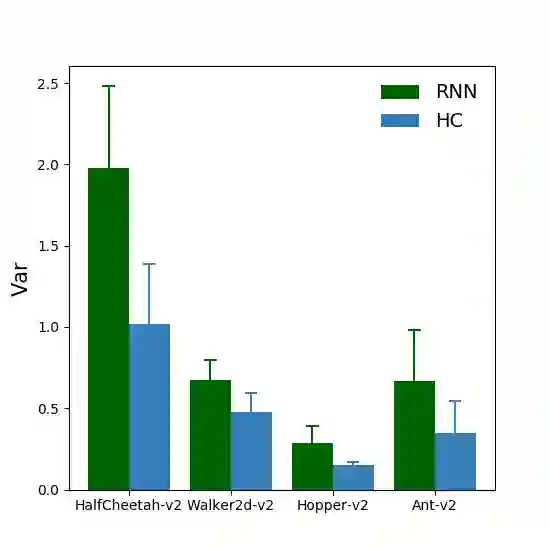
We study deep reinforcement learning (RL) algorithms with delayed rewards. In many real-world tasks, instant rewards are often not readily accessible or even defined immediately after the agent performs actions. In this work, we first formally define the environment with delayed rewards and discuss the challenges raised due to the non-Markovian nature of such environments. Then, we introduce a general off-policy RL framework with a new Q-function formulation that can handle the delayed rewards with theoretical convergence guarantees. For practical tasks with high dimensional state spaces, we further introduce the HC-decomposition rule of the Q-function in our framework which naturally leads to an approximation scheme that helps boost the training efficiency and stability. We finally conduct extensive experiments to demonstrate the superior performance of our algorithms over the existing work and their variants.
翻译:在许多现实世界的任务中,即时奖励往往不易获得,甚至不能在代理人采取行动后立即界定。在这项工作中,我们首先正式以延迟奖励的方式界定环境,并讨论由于这种环境的非马尔科维尼亚性质而产生的挑战。然后,我们推出一个一般性非政策性RL框架,采用新的Q-功能配方,能够用理论趋同保证来处理延迟奖励。对于涉及高维度国家空间的实际任务,我们进一步引入了“Q”功能的HC分解规则,这自然导致一种近似计划,有助于提高培训效率和稳定性。我们最后进行了广泛的实验,以展示我们算法相对于现有工作及其变体的优异性表现。