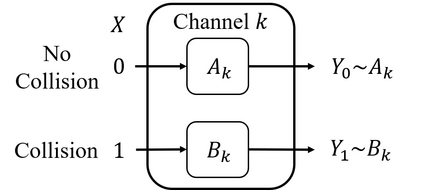
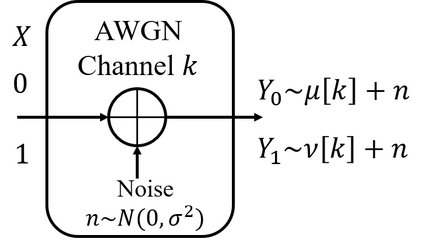
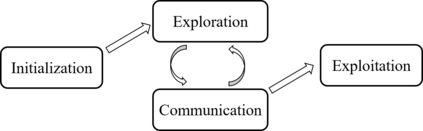
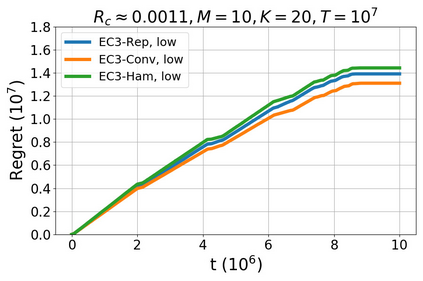
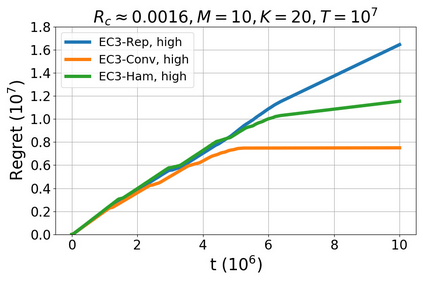
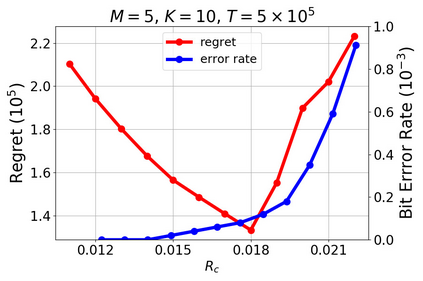
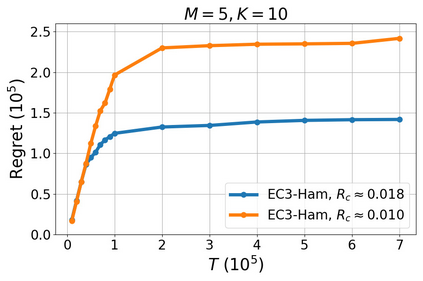
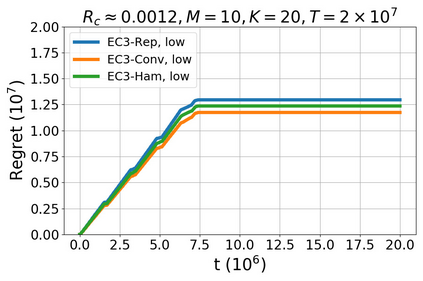
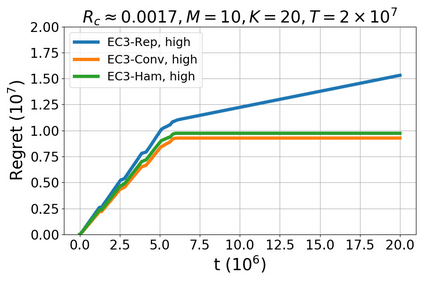
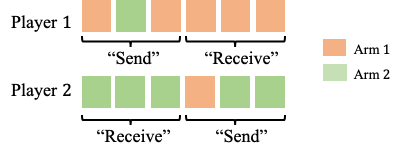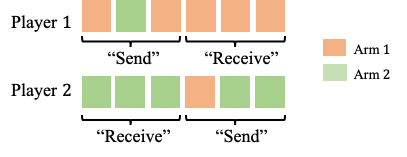We study a new stochastic multi-player multi-armed bandits (MP-MAB) problem, where the reward distribution changes if a collision occurs on the arm. Existing literature always assumes a zero reward for involved players if collision happens, but for applications such as cognitive radio, the more realistic scenario is that collision reduces the mean reward but not necessarily to zero. We focus on the more practical no-sensing setting where players do not perceive collisions directly, and propose the Error-Correction Collision Communication (EC3) algorithm that models implicit communication as a reliable communication over noisy channel problem, for which random coding error exponent is used to establish the optimal regret that no communication protocol can beat. Finally, optimizing the tradeoff between code length and decoding error rate leads to a regret that approaches the centralized MP-MAB regret, which represents a natural lower bound. Experiments with practical error-correction codes on both synthetic and real-world datasets demonstrate the superiority of EC3. In particular, the results show that the choice of coding schemes has a profound impact on the regret performance.
翻译:我们研究的是一个新的多玩家多臂强盗问题(MP-MAB),如果手臂发生碰撞,奖励分配就会发生变化。现有的文献总是假定在碰撞发生时对所涉玩家给予零奖励,但对于认知收音机等应用来说,更现实的情景是碰撞会减少平均奖励,但不一定是零。我们侧重于更实际的无观测环境,让玩家不直接看到碰撞,并提出错误校正协调通信(EC3)算法,模型将通信隐含为可靠的通信,而不是吵闹的频道问题,为此,随机编码错误会被用来证明任何通信协议都无法战胜的最佳遗憾。最后,优化代码长度与解码错误率之间的权衡,导致遗憾接近中央MP-MAB的遗憾,这代表了自然下限。在合成和真实世界数据集上实际错误校正代码的实验显示了EC3的优势。特别是,结果显示,编码计划的选择对后悔表现产生了深远的影响。