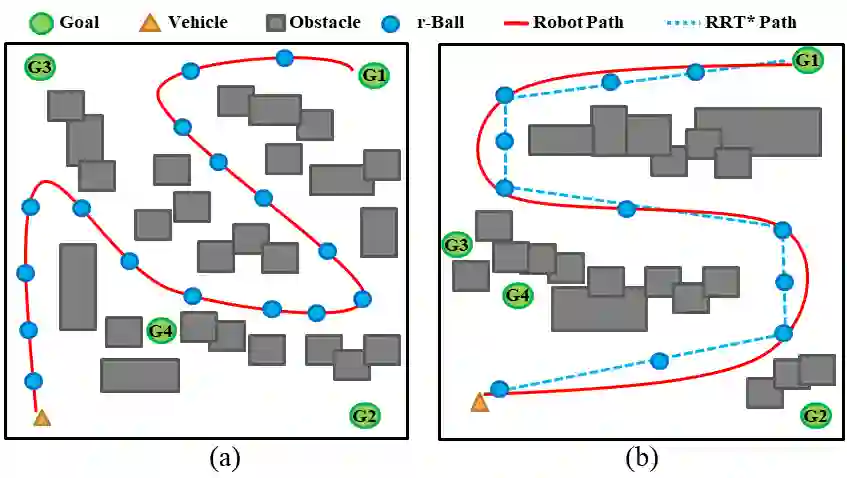
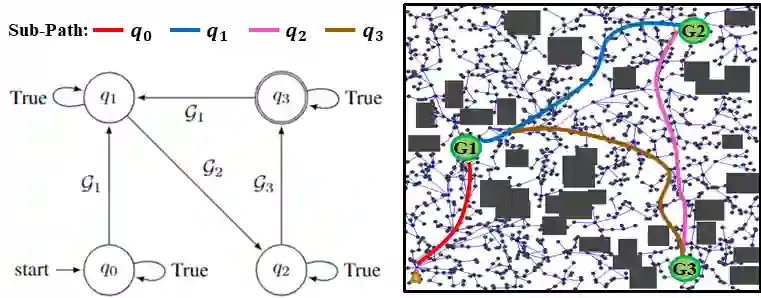
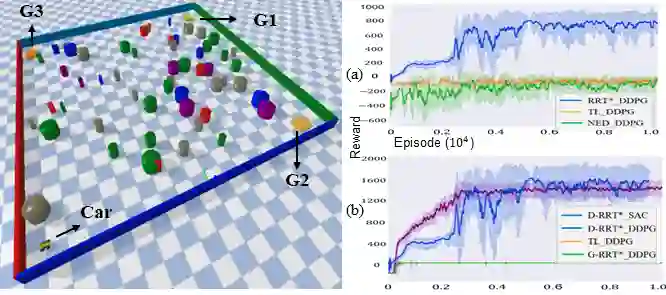
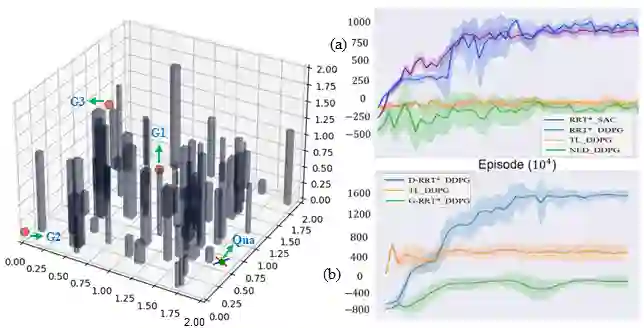
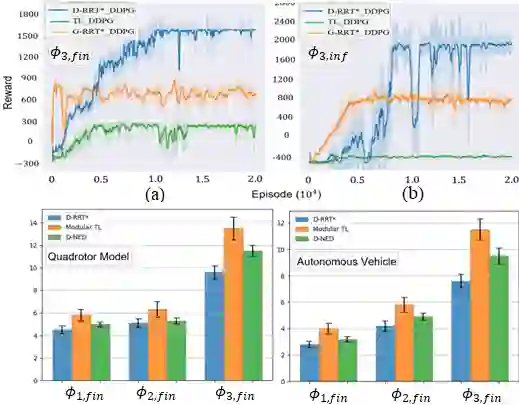
Exploration is a fundamental challenge in Deep Reinforcement Learning (DRL) based model-free navigation control since typical exploration techniques for target-driven navigation tasks rely on noise or greedy policies, which are sensitive to the density of rewards. In practice, robots are always deployed in complex cluttered environments, containing dense obstacles and narrow passageways, raising natural spare rewards that are hard to explore for training. Such a problem becomes even more serious when pre-defined tasks are complex and have rich expressivity. In this paper, we focus on these two aspects and present a deep policy gradient algorithm for a task-guided robot with unknown dynamics deployed in a complex cluttered environment. Linear Temporal Logic (LTL) is used to express rich robotic specifications. To overcome the environmental challenge of exploration during training, we propose a novel path planning-guided reward scheme that is dense over the state space, and crucially, robust to the infeasibility of computed geometric paths due to the black-box dynamics. The long or infinite horizons of general LTL specifications are often an issue for DRL due to its myopic tendencies. To facilitate LTL satisfaction, our approach decomposes the LTL mission into sub-tasks that are solved using distributed DRL, where the sub-tasks can be trained in parallel, using Deep Policy Gradient algorithms. Our framework is shown to significantly improve performance (effectiveness, efficiency) and exploration of robots tasked with complex missions in large-scale complex environments. The Video demonstration can be found on YouTube Channel: https://youtu.be/YQRQ2-yMtIk.
翻译:深强化学习(DRL)基于无型导航控制模式的探索是深强化学习(DRL)的根本性挑战,因为目标驱动导航任务典型的探索技术依赖于噪音或贪婪政策,对奖励的密度十分敏感。在实践上,机器人总是部署在复杂的杂乱环境中,包含密集的障碍和狭窄的通道,带来难以用于培训的自然剩余奖赏。当预先确定的任务复杂且具有丰富的直观性时,这一问题就变得更加严重。在本文中,我们集中关注这两个方面,为在复杂杂乱的环境中部署的、具有未知动态的任务制导机器人提出一个深度的政策梯度算法。线性极极时,用于表达丰富的机器人规格。为了克服培训期间的勘探环境挑战,我们提出了一个新的路径规划指导奖赏计划,在州空间上十分密集,而且关键地,对于由于黑箱动态而计算出地球测量路径的不可行性能。一般LTL技术规格的复杂或无限的视野常常成为DRL的一个问题,因为它具有我的视觉趋势。LTLL用来表达丰富的动态。LLLLLL系统,为了大大地展示它。为了展示它,在深度的图像上展示我们的数据效率,在深度上展示我们的亚程中,可以展示我们的亚平级平级平流路段平流路段平平平平平平平平平平。