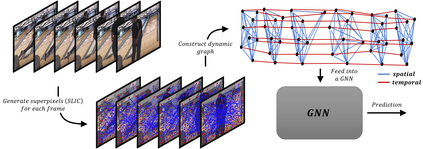
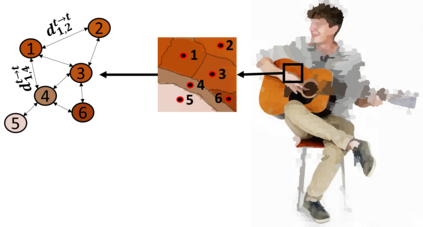
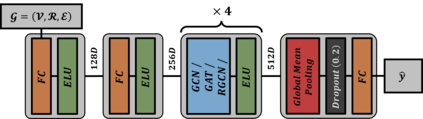
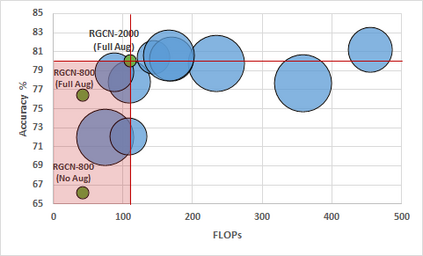
We propose a concise representation of videos that encode perceptually meaningful features into graphs. With this representation, we aim to leverage the large amount of redundancies in videos and save computations. First, we construct superpixel-based graph representations of videos by considering superpixels as graph nodes and create spatial and temporal connections between adjacent superpixels. Then, we leverage Graph Convolutional Networks to process this representation and predict the desired output. As a result, we are able to train models with much fewer parameters, which translates into short training periods and a reduction in computation resource requirements. A comprehensive experimental study on the publicly available datasets Kinetics-400 and Charades shows that the proposed method is highly cost-effective and uses limited commodity hardware during training and inference. It reduces the computational requirements 10-fold while achieving results that are comparable to state-of-the-art methods. We believe that the proposed approach is a promising direction that could open the door to solving video understanding more efficiently and enable more resource limited users to thrive in this research field.
翻译:我们提出一个简明的视频表达方式,将感知上有意义的功能编码成图表。 通过这个表达方式,我们的目标是利用视频中的大量冗余,并节省计算。 首先,我们通过将超级像素作为图形节点来构建基于超级像素的视频图示,并在相邻的超像素之间建立空间和时间连接。 然后,我们利用图形革命网络来处理这个表达方式并预测想要的产出。结果,我们能够以少得多的参数来培训模型,这些参数转化为短期的培训时间和计算资源需求的减少。 关于公开提供的数据集Kinetics-400和Charades的全面实验研究表明,拟议方法成本效益高,在培训和推断过程中使用有限的商品硬件。它减少了计算要求10倍,同时取得与最新方法相近的结果。 我们认为,拟议的方法是一个有希望的方向,可以打开更高效地解决视频理解的大门,使资源有限的用户能够在这个研究领域蓬勃发展。