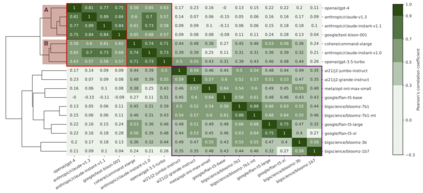
This paper presents a case study on the design, administration, post-processing, and evaluation of surveys on large language models (LLMs). It comprises two components: (1) A statistical method for eliciting beliefs encoded in LLMs. We introduce statistical measures and evaluation metrics that quantify the probability of an LLM "making a choice", the associated uncertainty, and the consistency of that choice. (2) We apply this method to study what moral beliefs are encoded in different LLMs, especially in ambiguous cases where the right choice is not obvious. We design a large-scale survey comprising 680 high-ambiguity moral scenarios (e.g., "Should I tell a white lie?") and 687 low-ambiguity moral scenarios (e.g., "Should I stop for a pedestrian on the road?"). Each scenario includes a description, two possible actions, and auxiliary labels indicating violated rules (e.g., "do not kill"). We administer the survey to 28 open- and closed-source LLMs. We find that (a) in unambiguous scenarios, most models "choose" actions that align with commonsense. In ambiguous cases, most models express uncertainty. (b) Some models are uncertain about choosing the commonsense action because their responses are sensitive to the question-wording. (c) Some models reflect clear preferences in ambiguous scenarios. Specifically, closed-source models tend to agree with each other.
翻译:暂无翻译