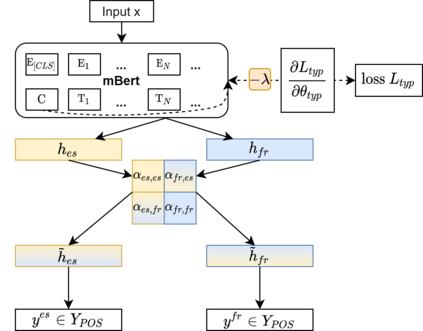
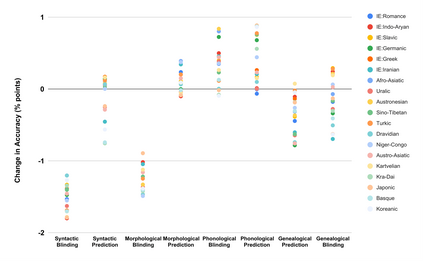
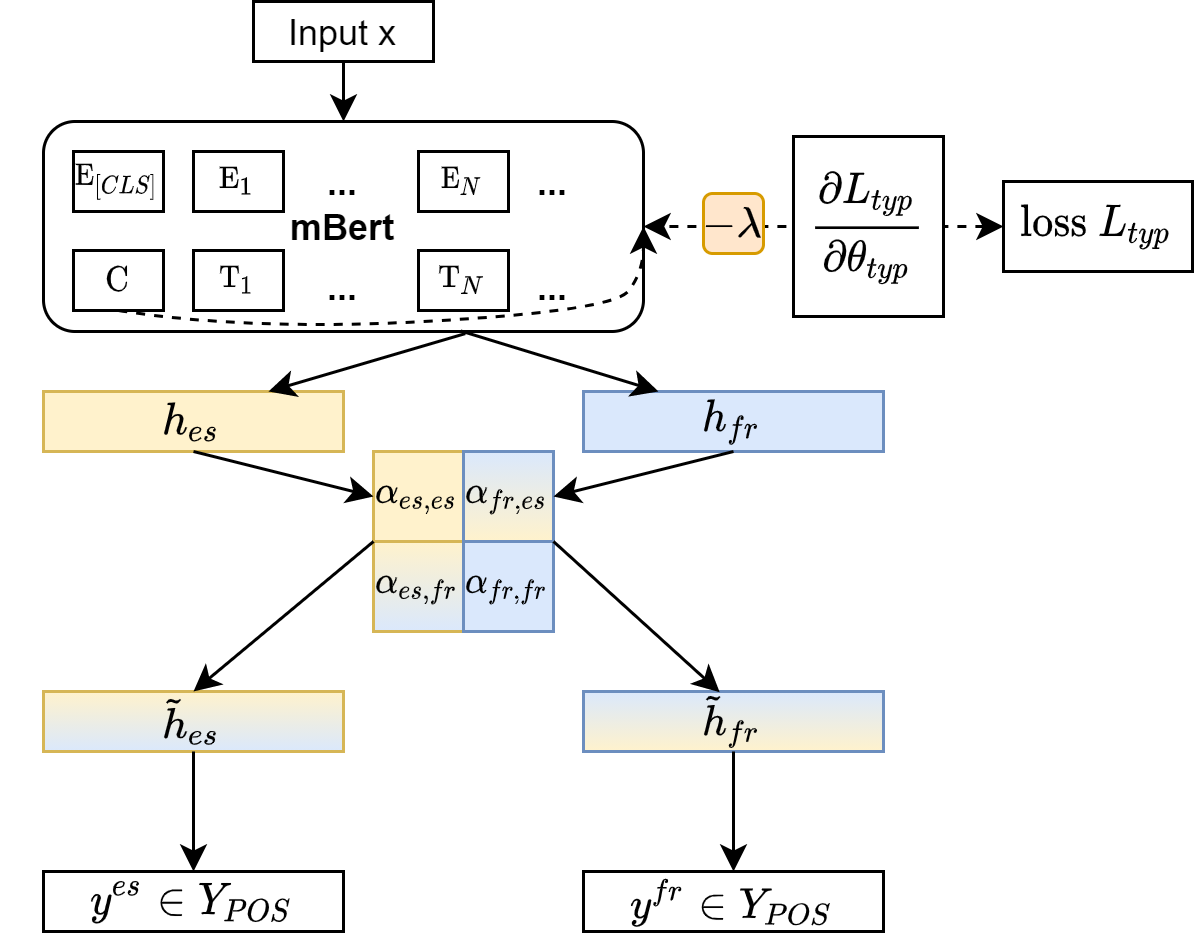
Bridging the performance gap between high- and low-resource languages has been the focus of much previous work. Typological features from databases such as the World Atlas of Language Structures (WALS) are a prime candidate for this, as such data exists even for very low-resource languages. However, previous work has only found minor benefits from using typological information. Our hypothesis is that a model trained in a cross-lingual setting will pick up on typological cues from the input data, thus overshadowing the utility of explicitly using such features. We verify this hypothesis by blinding a model to typological information, and investigate how cross-lingual sharing and performance is impacted. Our model is based on a cross-lingual architecture in which the latent weights governing the sharing between languages is learnt during training. We show that (i) preventing this model from exploiting typology severely reduces performance, while a control experiment reaffirms that (ii) encouraging sharing according to typology somewhat improves performance.
翻译:弥合高低资源语言之间的性能差距是以往许多工作的重点。来自世界语言结构图集等数据库的类型特征是这方面的首要选择,因为这些数据甚至存在于非常低资源的语言中。然而,以往的工作发现,使用类型信息只带来一些小的效益。我们的假设是,在跨语言环境中培训的模型会从输入数据中提取打字线索,从而掩盖明确使用这些特征的效用。我们通过盲目一种打字信息模型来验证这一假设,并调查跨语言共享和性能如何受到影响。我们的模式基于一种跨语言结构,在这种结构中,在培训中学习关于不同语言之间共享的潜在权重。我们表明,(一) 防止这种模式利用类型严重降低性能,而一项控制实验则重申:(二) 鼓励根据类型共享,在一定程度上改善性能。