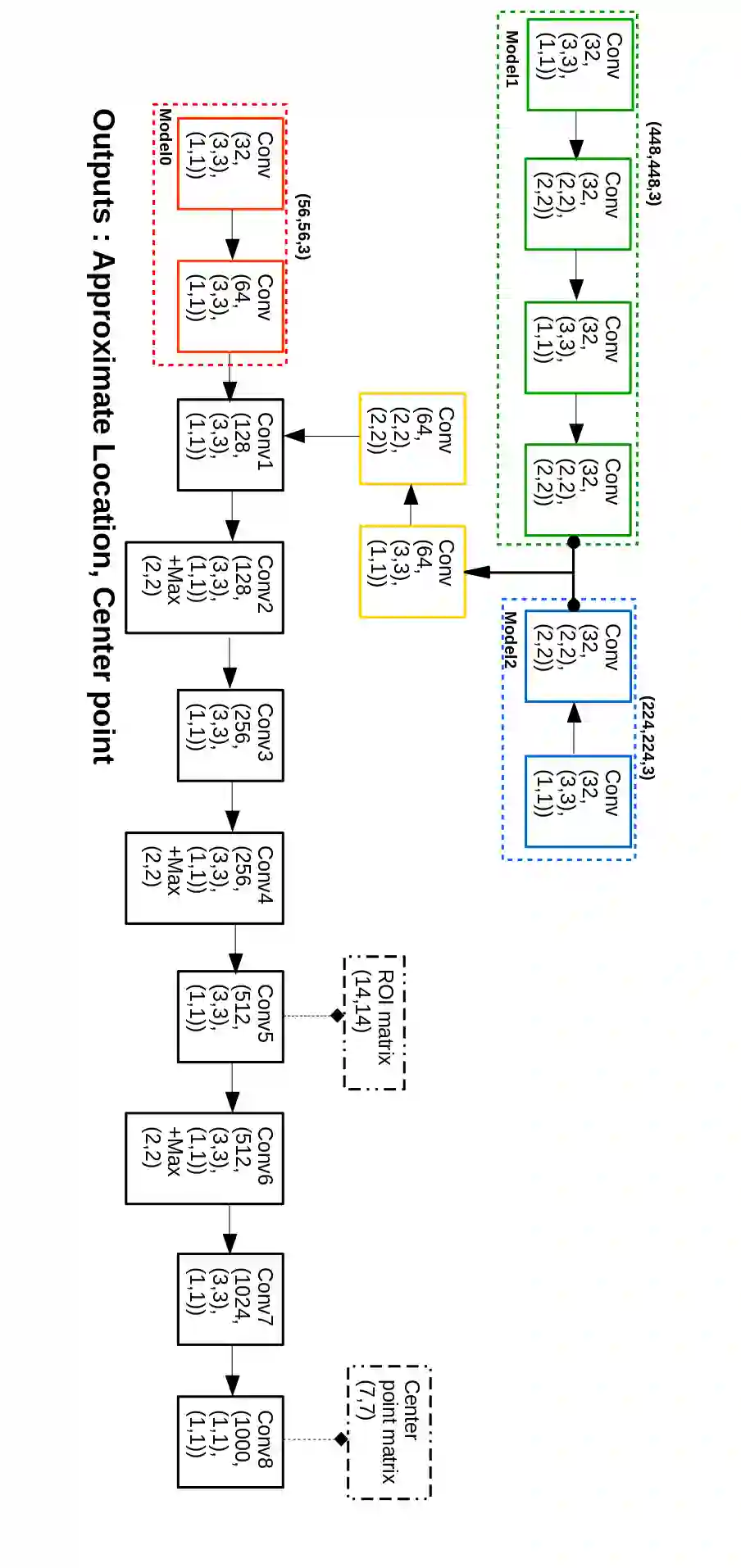
Object localization has a vital role in any object detector, and therefore, has been the focus of attention by many researchers. In this article, a special training approach is proposed for a light convolutional neural network (CNN) to determine the region of interest (ROI) in an image while effectively reducing the number of probable anchor boxes. Almost all CNN-based detectors utilize a fixed input size image, which may yield poor performance when dealing with various object sizes. In this paper, a different CNN structure is proposed taking three different input sizes, to enhance the performance. In order to demonstrate the effectiveness of the proposed method, two common data set are used for training while tracking by localization application is considered to demonstrate its final performance. The promising results indicate the applicability of the presented structure and the training method in practice.
翻译:物体定位在任何物体探测器中都具有关键作用,因此一直是许多研究人员关注的焦点。在本条中,提议对一个光相电动神经网络采取特别培训办法,以确定图像中感兴趣的区域,同时有效地减少可能的锚框数量。几乎所有有线电视新闻网的探测器都使用固定输入尺寸图像,在处理各种物体尺寸时,这种图像可能会造成不良性能。本文建议采用不同的有线电视新闻网结构,采用三种不同的输入尺寸来提高性能。为了证明拟议方法的有效性,在培训中使用了两个共同数据集,同时考虑通过定位应用程序跟踪跟踪,以显示其最终性能。有希望的结果表明,在实际操作中,所提出的结构和培训方法是可行的。