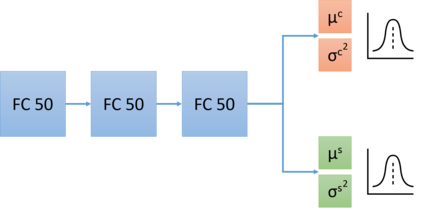
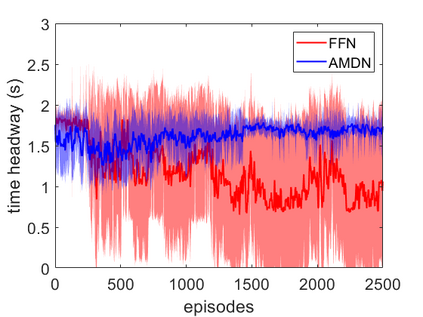
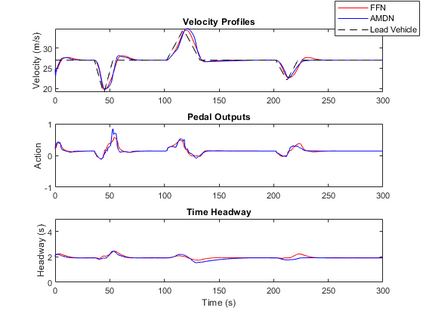
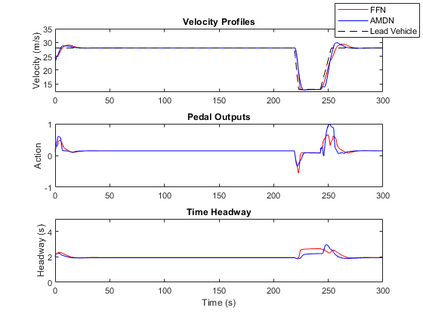
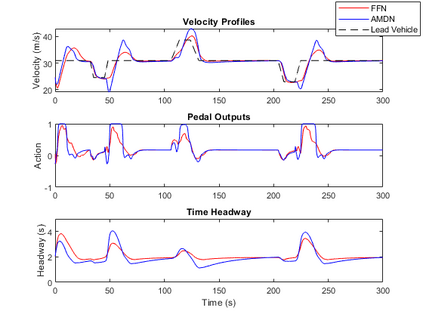
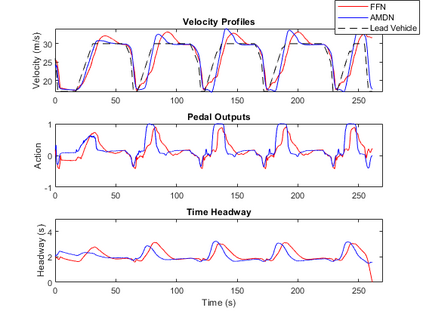
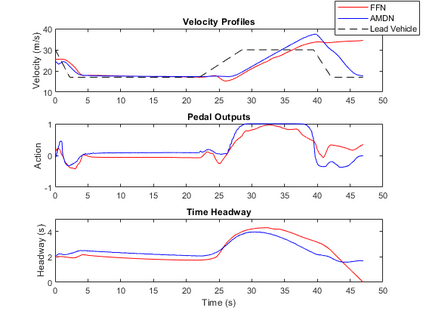
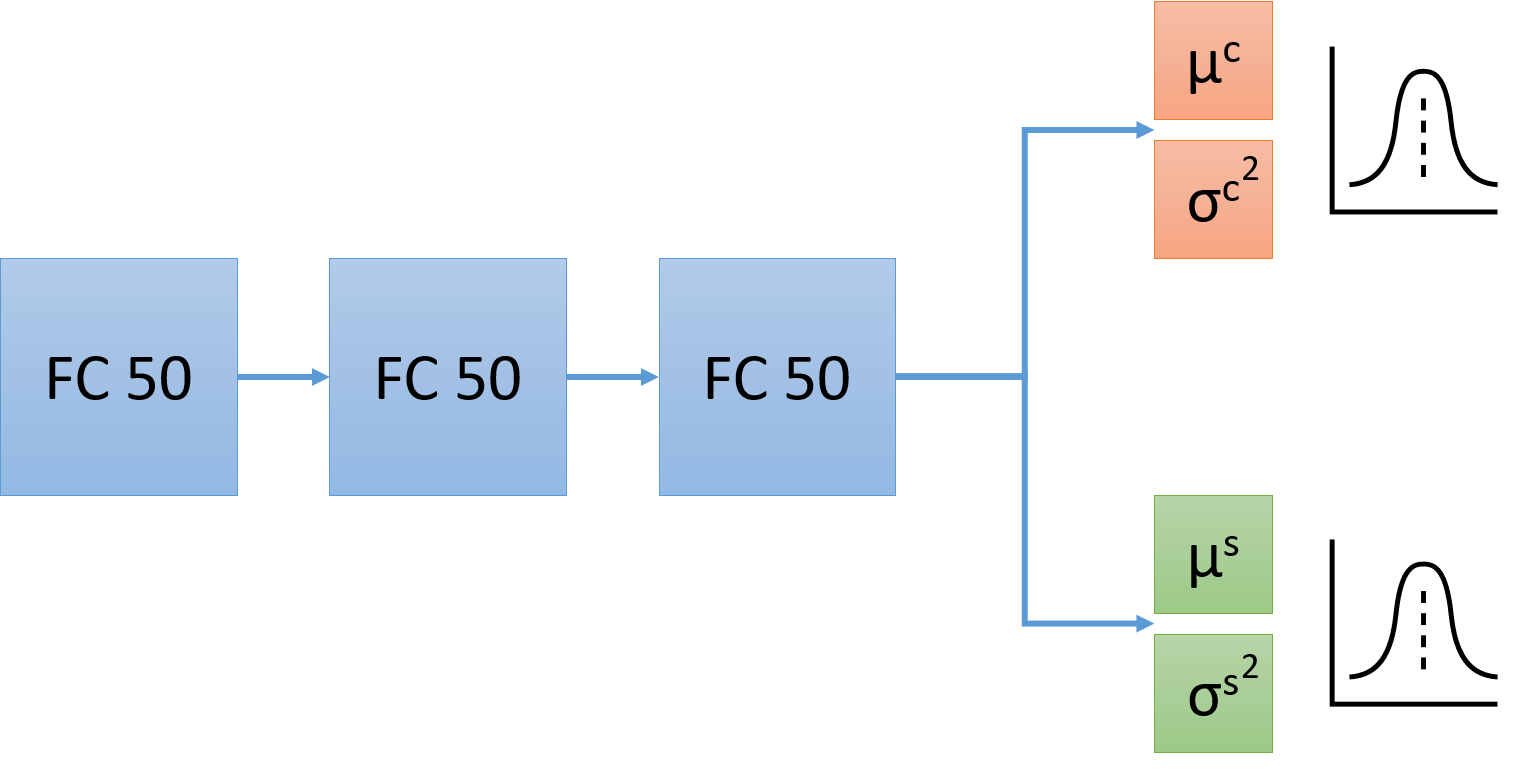
Imitation learning has been widely used to learn control policies for autonomous driving based on pre-recorded data. However, imitation learning based policies have been shown to be susceptible to compounding errors when encountering states outside of the training distribution. Further, these agents have been demonstrated to be easily exploitable by adversarial road users aiming to create collisions. To overcome these shortcomings, we introduce Adversarial Mixture Density Networks (AMDN), which learns two distributions from separate datasets. The first is a distribution of safe actions learned from a dataset of naturalistic human driving. The second is a distribution representing unsafe actions likely to lead to collision, learned from a dataset of collisions. During training, we leverage these two distributions to provide an additional loss based on the similarity of the two distributions. By penalising the safe action distribution based on its similarity to the unsafe action distribution when training on the collision dataset, a more robust and safe control policy is obtained. We demonstrate the proposed AMDN approach in a vehicle following use-case, and evaluate under naturalistic and adversarial testing environments. We show that despite its simplicity, AMDN provides significant benefits for the safety of the learned control policy, when compared to pure imitation learning or standard mixture density network approaches.
翻译:根据预先录制的数据,广泛利用模拟学习来学习自主驾驶的控制政策,然而,模拟学习政策在培训分布之外遇到国家时被证明容易出现复合错误。此外,还证明对抗性道路使用者很容易利用这些工具来制造碰撞。为了克服这些缺陷,我们引入了反反逆混合密度网络(AMDN),从不同的数据集中学习两种分布方式。第一个是分配从自然人类驾驶数据集中学习的安全行动。第二个是代表可能导致碰撞的不安全行动的分布,从碰撞数据集中学习。在培训期间,我们利用这两种分布方式,根据两种分布方式的相似性,提供额外损失。我们根据对碰撞数据集的培训,根据安全行动分布方式与不安全行动分布相类似,对安全行动进行处罚。我们展示了在使用后在车辆中采用AMDN方法的建议,并在自然和对抗性测试环境下进行评估。我们表明,尽管采用标准化的网络,我们学习了安全性控制方法,但我们学习了安全度的标准化。我们学习了安全性模型,但学习了安全性控制方法的标准化。