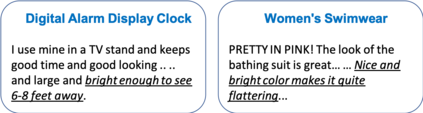
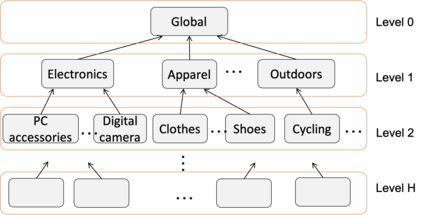
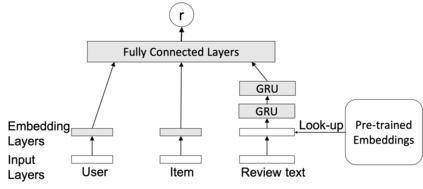
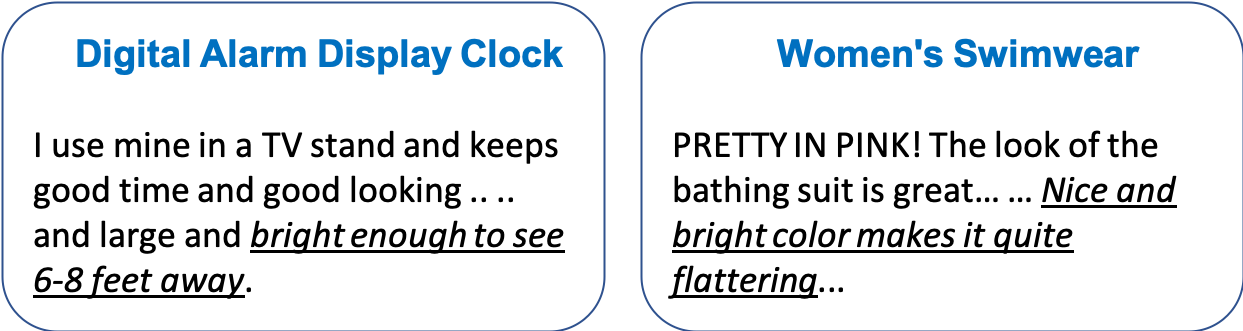
The meaning of a word often varies depending on its usage in different domains. The standard word embedding models struggle to represent this variation, as they learn a single global representation for a word. We propose a method to learn domain-specific word embeddings, from text organized into hierarchical domains, such as reviews in an e-commerce website, where products follow a taxonomy. Our structured probabilistic model allows vector representations for the same word to drift away from each other for distant domains in the taxonomy, to accommodate its domain-specific meanings. By learning sets of domain-specific word representations jointly, our model can leverage domain relationships, and it scales well with the number of domains. Using large real-world review datasets, we demonstrate the effectiveness of our model compared to state-of-the-art approaches, in learning domain-specific word embeddings that are both intuitive to humans and benefit downstream NLP tasks.
翻译:一个单词的含义往往因其在不同领域的使用而不同。 标准嵌入模式的字词在努力代表这一差异, 因为它们学习了一个单词的全球代表。 我们提出了一个方法来学习从按等级划分的文字中具体域的字嵌入, 比如在电子商务网站上的审查, 产品遵循分类法。 我们结构化的概率模型允许同一字的矢量表达方式在分类学的遥远域中相互漂移, 以适应其特定域的含义。 通过学习一套特定域的字表达方式, 我们的模式可以共同利用域际关系, 并将它与域数相匹配。 我们使用大型真实世界审查数据集, 展示了我们模型与最新技术方法相比的有效性, 在学习对人来说不切实际的、对下游国家语言方案任务有益的特定域嵌入方面。