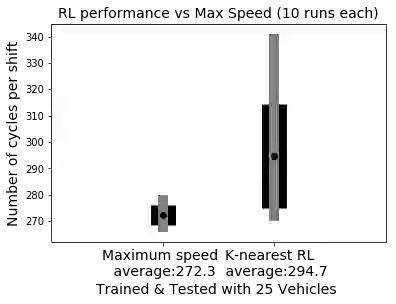
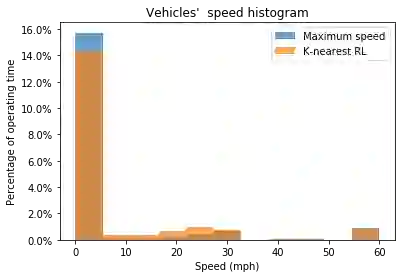
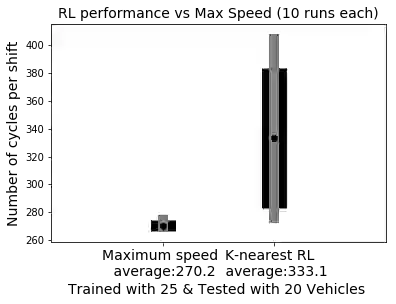
Traditionally, the performance of multi-agent deep reinforcement learning algorithms are demonstrated and validated in gaming environments where we often have a fixed number of agents. In many industrial applications, the number of available agents can change at any given day and even when the number of agents is known ahead of time, it is common for an agent to break during the operation and become unavailable for a period of time. In this paper, we propose a new deep reinforcement learning algorithm for multi-agent collaborative tasks with a variable number of agents. We demonstrate the application of our algorithm using a fleet management simulator developed by Hitachi to generate realistic scenarios in a production site.
翻译:传统上,多试剂深层强化学习算法的性能在游戏环境中得到证明和验证,因为在游戏环境中,我们往往有固定数量的代理商。在许多工业应用中,可用的代理商的数量可以在任何特定日期发生变化,即使事先知道代理商的数量,代理人在操作期间经常中断,在一段时间内无法使用。在本文中,我们建议为多试剂合作任务提出一个新的深层强化学习算法,与数量不等的代理商合作。我们用由Hitachi开发的车队管理模拟器在生产现场产生现实情景来证明我们的算法的应用。