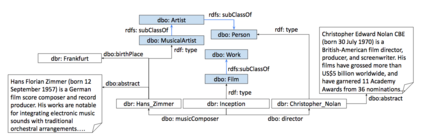
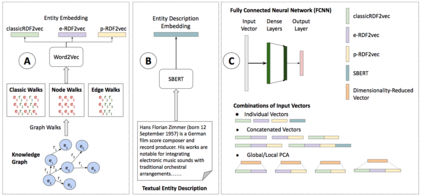
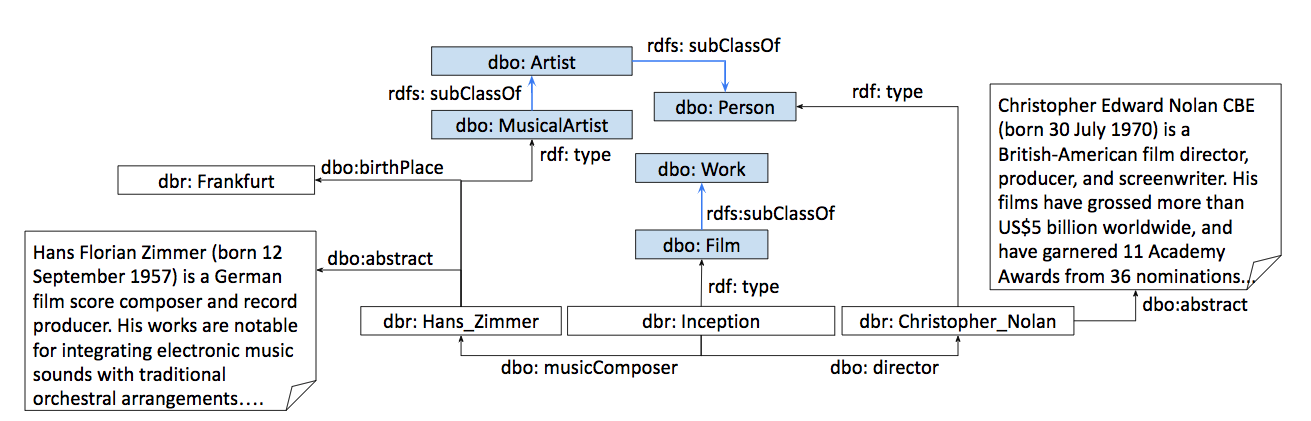
The entity type information in Knowledge Graphs (KGs) such as DBpedia, Freebase, etc. is often incomplete due to automated generation or human curation. Entity typing is the task of assigning or inferring the semantic type of an entity in a KG. This paper presents \textit{GRAND}, a novel approach for entity typing leveraging different graph walk strategies in RDF2vec together with textual entity descriptions. RDF2vec first generates graph walks and then uses a language model to obtain embeddings for each node in the graph. This study shows that the walk generation strategy and the embedding model have a significant effect on the performance of the entity typing task. The proposed approach outperforms the baseline approaches on the benchmark datasets DBpedia and FIGER for entity typing in KGs for both fine-grained and coarse-grained classes. The results show that the combination of order-aware RDF2vec variants together with the contextual embeddings of the textual entity descriptions achieve the best results.
翻译:DBpedia、Freebase等知识图(KGs)中的实体类型信息往往因自动生成或人为校正而不完整。实体键入是指定或推断KG中实体的语义类型的任务。本文展示了\ textit{GRAND},这是实体在RDF2vec和文本实体描述中利用不同图形行走策略进行输入的新办法。RDF2vec首先生成图形散行,然后使用语言模型为图表中的每个节点获得嵌入。本研究显示,行走生成战略和嵌入模型对实体打字任务的业绩有重大影响。拟议的方法超越了基准数据集DBpedia和FIGER的基准方法,用于实体在KGs打入精细和粗粗粗的分类。结果显示,有识的RDF2vec变量与文本实体描述的背景嵌入组合了最佳结果。