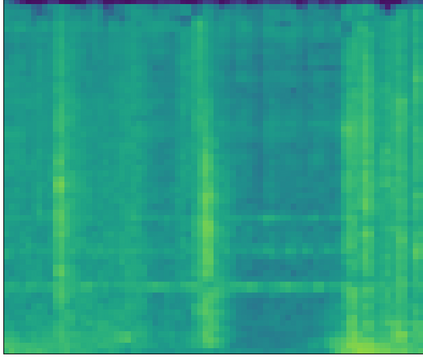
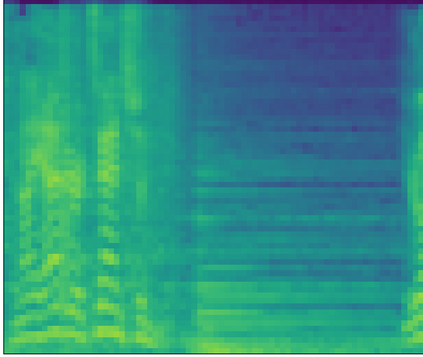
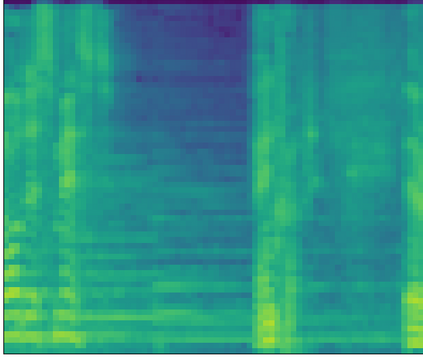
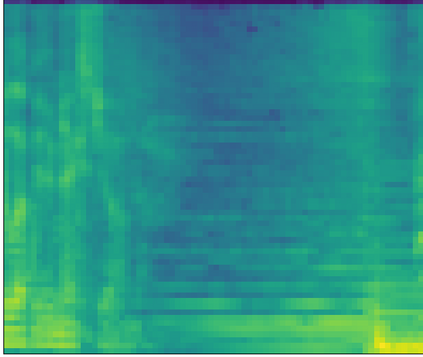
Large-scale audio tagging datasets inevitably contain imperfect labels, such as clip-wise annotated (temporally weak) tags with no exact on- and offsets, due to a high manual labeling cost. This work proposes pseudo strong labels (PSL), a simple label augmentation framework that enhances the supervision quality for large-scale weakly supervised audio tagging. A machine annotator is first trained on a large weakly supervised dataset, which then provides finer supervision for a student model. Using PSL we achieve an mAP of 35.95 balanced train subset of Audioset using a MobileNetV2 back-end, significantly outperforming approaches without PSL. An analysis is provided which reveals that PSL mitigates missing labels. Lastly, we show that models trained with PSL are also superior at generalizing to the Freesound datasets (FSD) than their weakly trained counterparts.
翻译:大型音频标签数据集不可避免地含有不完善的标签,例如由于高人工标签成本,短短的附加说明(时弱)标签,没有准确的贴现和抵消。这项工作提出了假的坚固标签(PSL),这是一个简单的标签增强框架,可以提高大规模微弱监督的音频标签的监管质量。一个机器标记员首先在大型薄弱监管的数据集上接受培训,然后为学生模型提供更精细的监督。利用PSL,我们利用一个移动网络V2后端,实现了35.95个平衡的音频组列,大大优于没有 PSL的方法。我们提供的分析显示,PSL会减少缺失的标签。最后,我们显示,经过PSL培训的模型也优于对自由声数据集(FSD)的普及,优于他们受过薄弱培训的对应方。