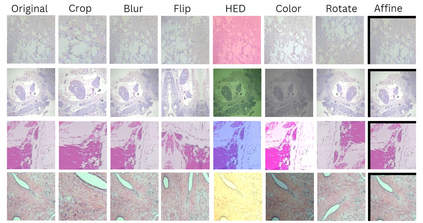
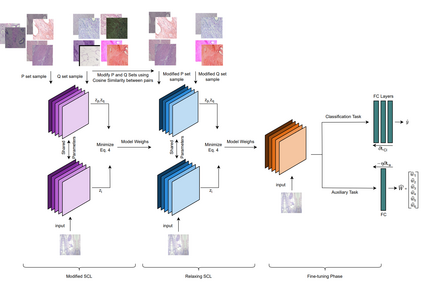
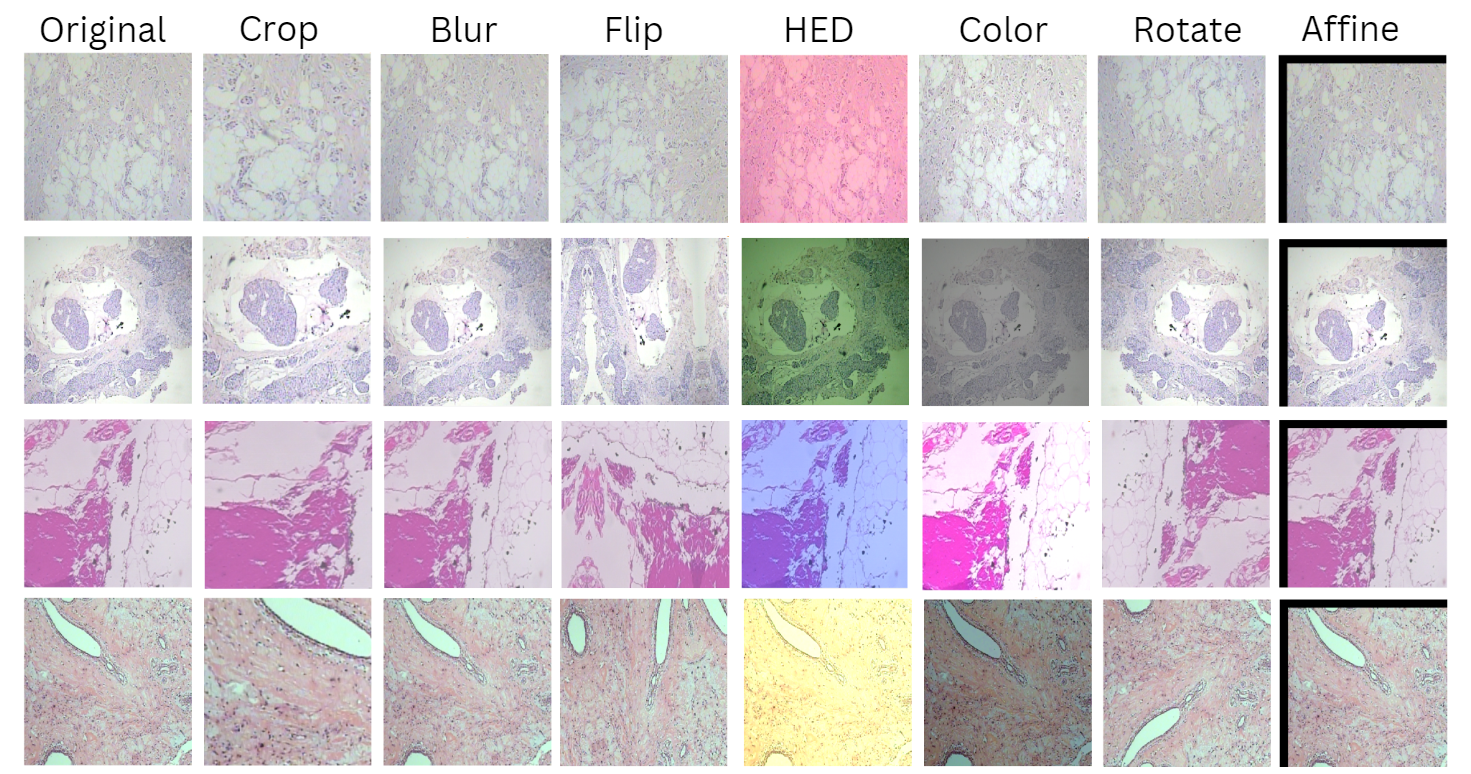
Deep neural networks have reached remarkable achievements in medical image processing tasks, specifically classifying and detecting various diseases. However, when confronted with limited data, these networks face a critical vulnerability, often succumbing to overfitting by excessively memorizing the limited information available. This work addresses the challenge mentioned above by improving the supervised contrastive learning method to reduce the impact of false positives. Unlike most existing methods that rely predominantly on fully supervised learning, our approach leverages the advantages of self-supervised learning in conjunction with employing the available labeled data. We evaluate our method on the BreakHis dataset, which consists of breast cancer histopathology images, and demonstrate an increase in classification accuracy by 1.45% at the image level and 1.42% at the patient level compared to the state-of-the-art method. This improvement corresponds to 93.63% absolute accuracy, highlighting our approach's effectiveness in leveraging data properties to learn more appropriate representation space.
翻译:暂无翻译