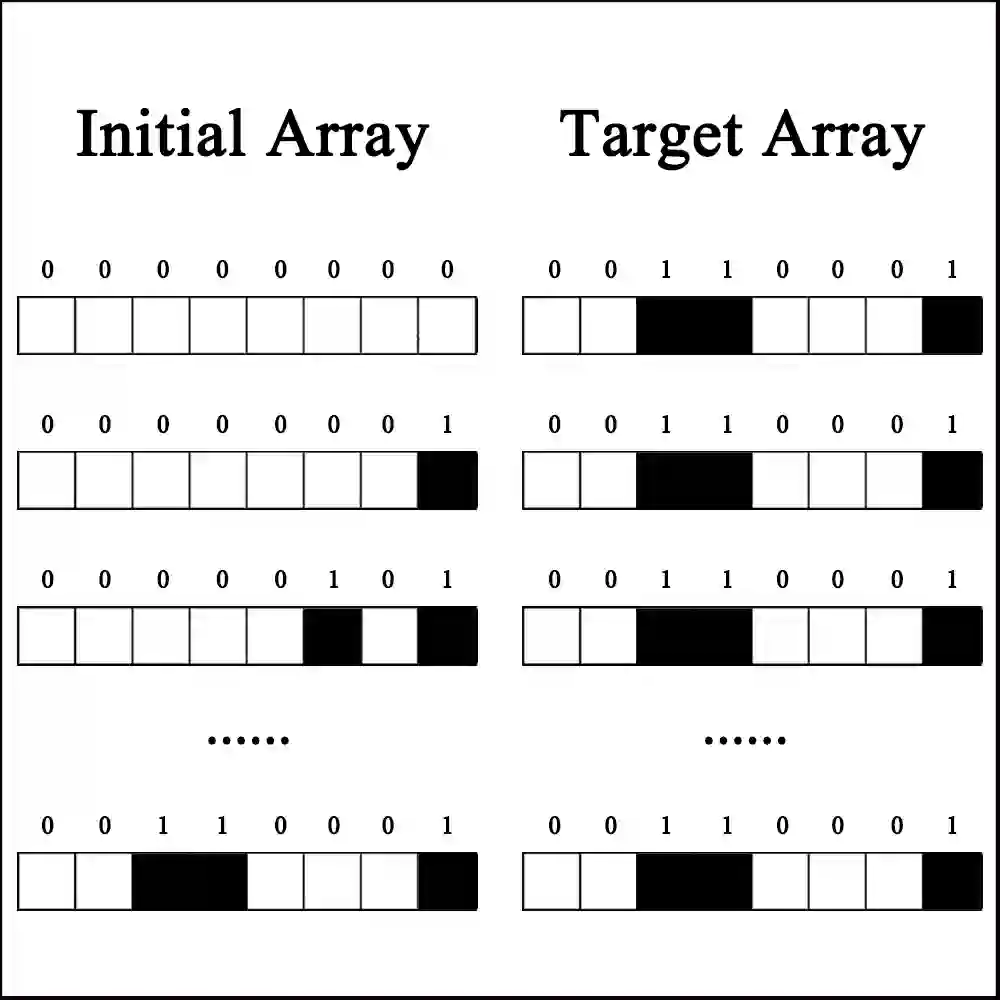
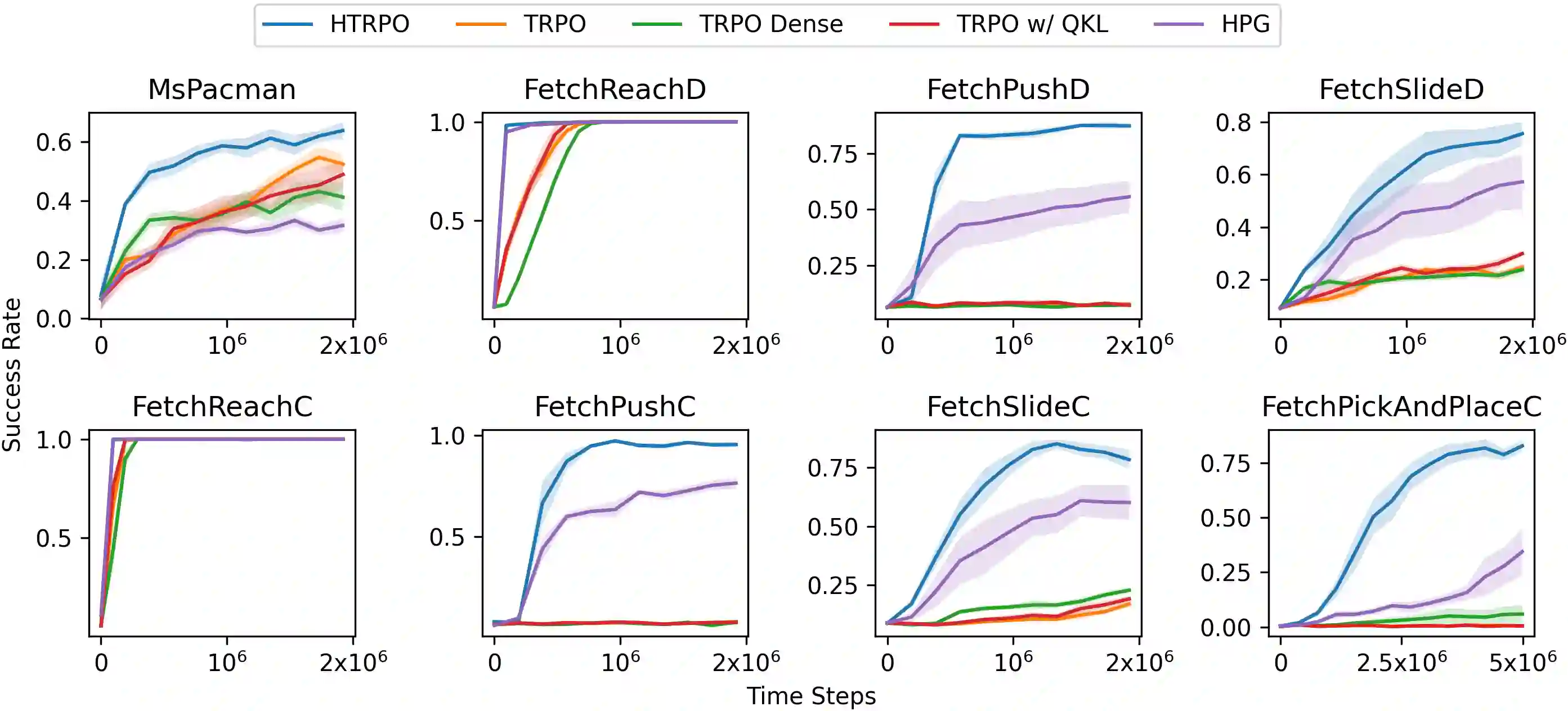
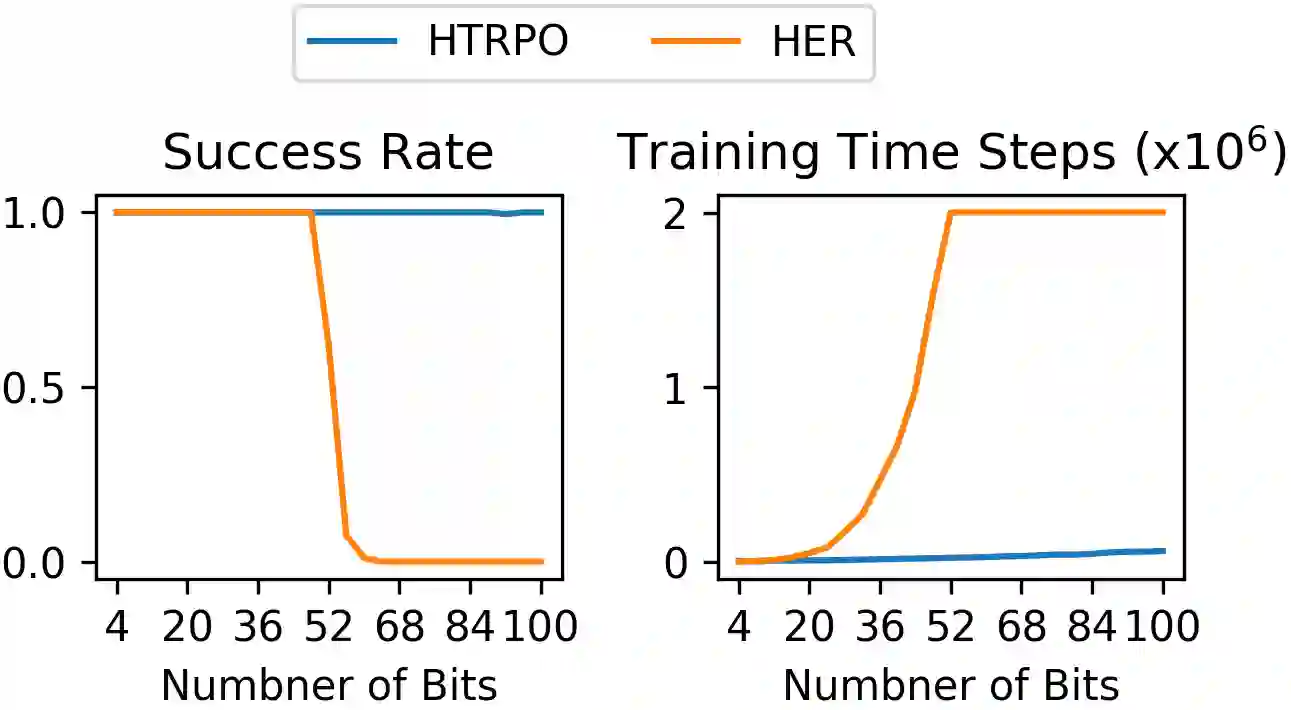
Reinforcement Learning(RL) with sparse rewards is a major challenge. We propose \emph{Hindsight Trust Region Policy Optimization}(HTRPO), a new RL algorithm that extends the highly successful TRPO algorithm with \emph{hindsight} to tackle the challenge of sparse rewards. Hindsight refers to the algorithm's ability to learn from information across goals, including ones not intended for the current task. HTRPO leverages two main ideas. It introduces QKL, a quadratic approximation to the KL divergence constraint on the trust region, leading to reduced variance in KL divergence estimation and improved stability in policy update. It also presents Hindsight Goal Filtering(HGF) to select conductive hindsight goals. In experiments, we evaluate HTRPO in various sparse reward tasks, including simple benchmarks, image-based Atari games, and simulated robot control. Ablation studies indicate that QKL and HGF contribute greatly to learning stability and high performance. Comparison results show that in all tasks, HTRPO consistently outperforms both TRPO and HPG, a state-of-the-art algorithm for RL with sparse rewards.
翻译:加强学习(RL) 少有回报是一个重大挑战。 我们提出 emph{ Hindsight Trust 区域政策优化 (HTRPO), 这是一种新的 RL 算法, 将极成功的TRPO 算法与 emph{hindsight} 相扩展, 以应对少有回报的挑战。 光观 指的是算法从不同目标的信息中学习的能力, 包括并非用于当前任务的信息。 HTRPO 利用了两个主要想法。 它引入了 QKL, 即 QKL, 这是对信任区域KL 差异限制的二次接近, 导致 KL 差异估计的差异减少, 并改进了政策更新的稳定性。 它还展示了 Hindsight 目标过滤(HGF) 以选择演练后视目标 。 在实验中, 我们评估 HTRPO 各种稀有的奖赏任务, 包括简单的基准、 以图像为基础的 Atari 游戏 和 模拟机器人控制 。 缩略研究表明, QKL 和 HGFPO 都有助于学习稳定性和高绩效。 。 比较结果表明, 在所有任务中, HTRPO 都 都 超越了 RTRPO 和 HGPO 。