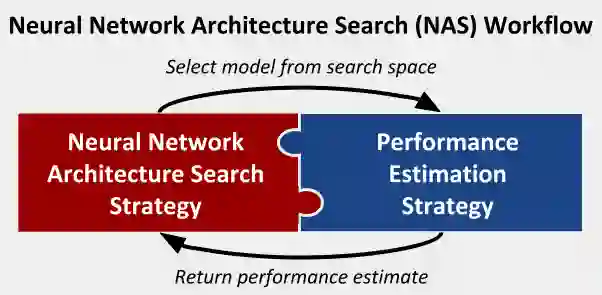
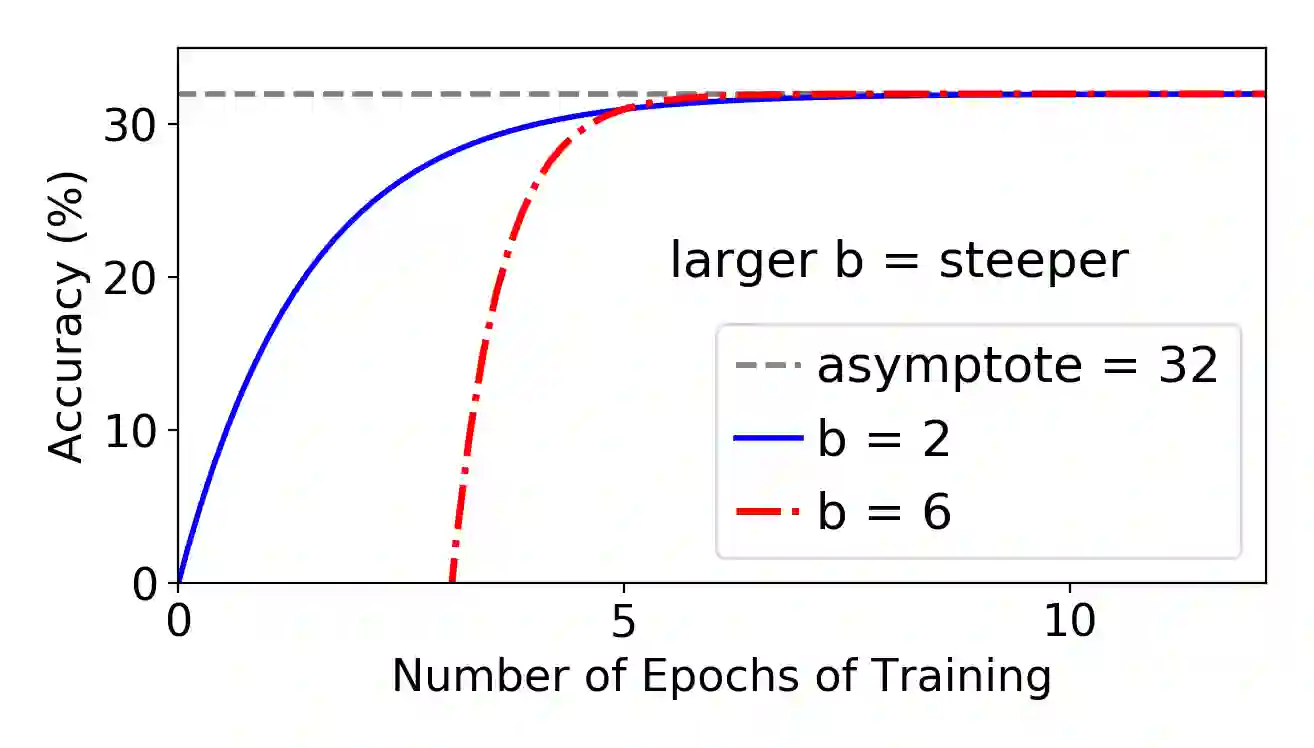
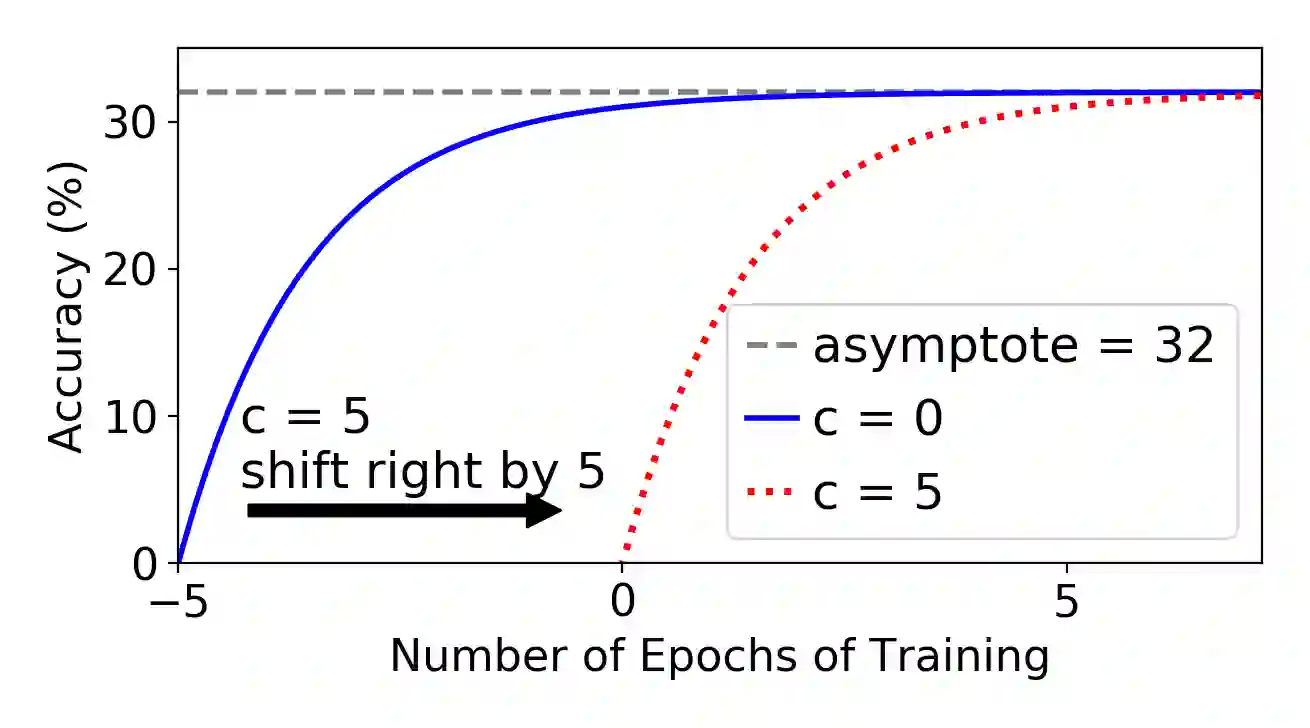
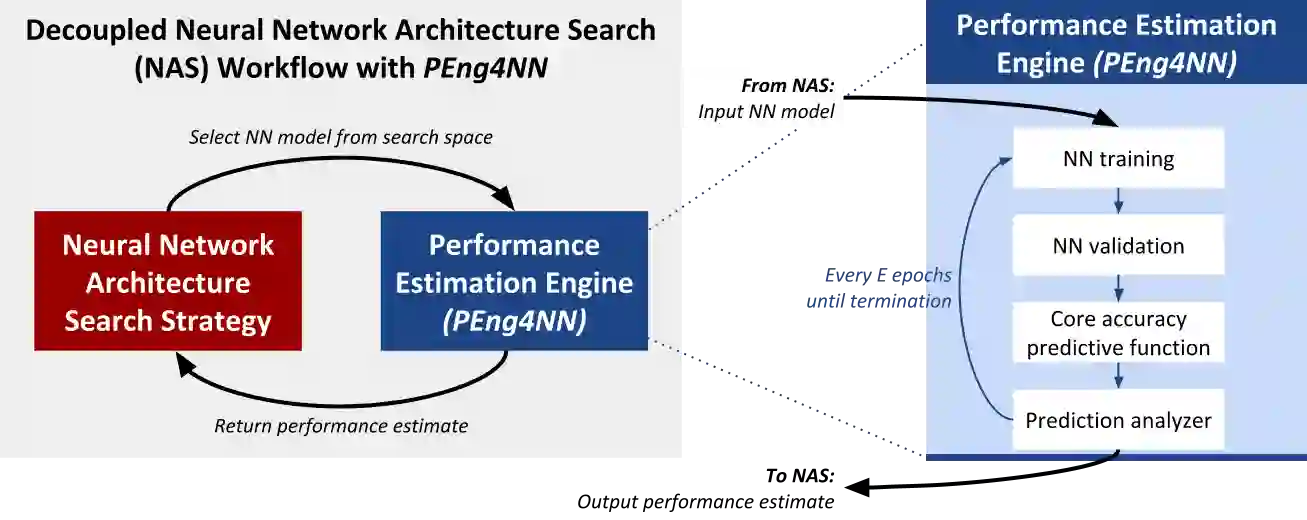
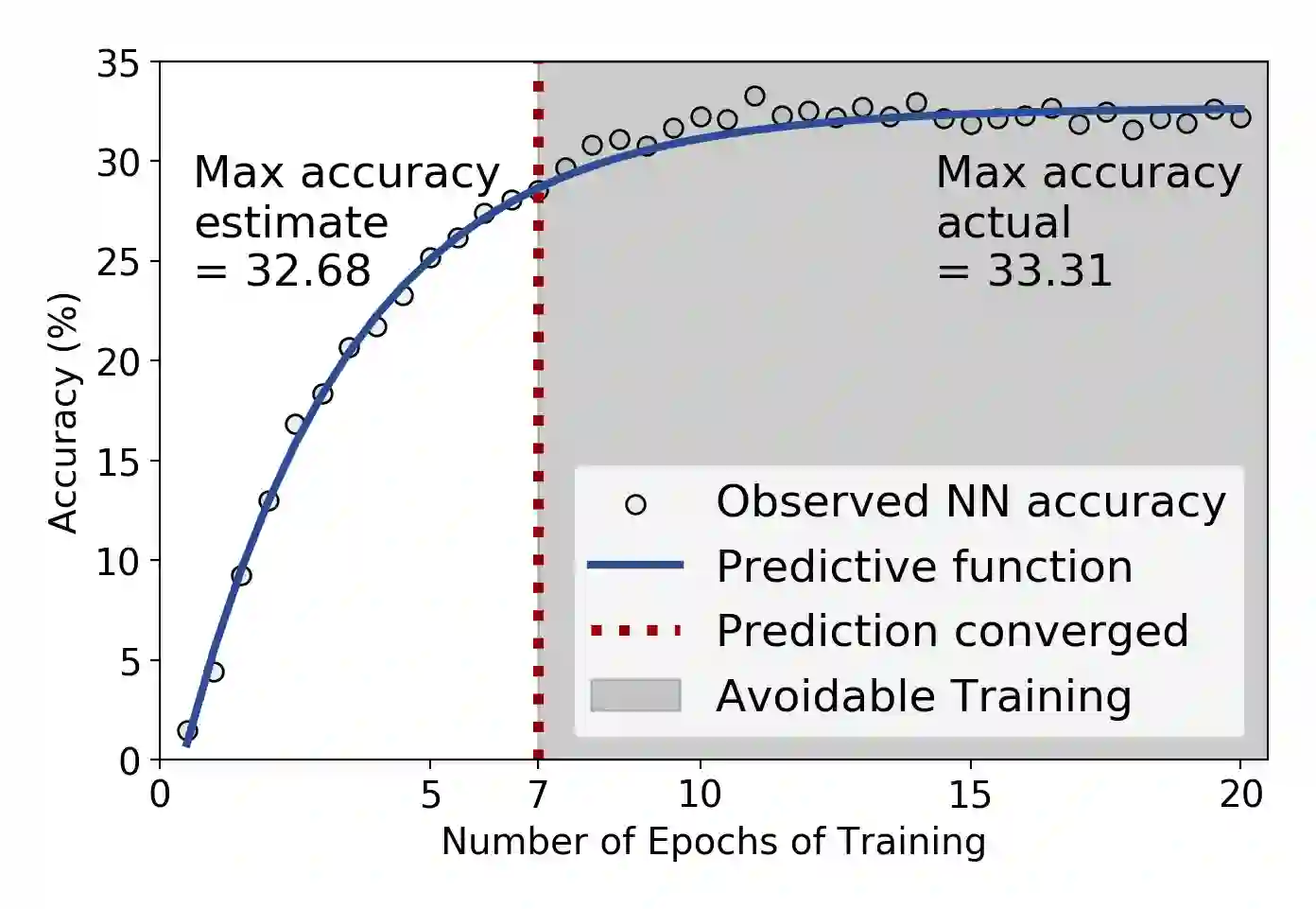
Neural network (NN) models are increasingly used in scientific simulations, AI, and other high performance computing (HPC) fields to extract knowledge from datasets. Each dataset requires tailored NN model architecture, but designing structures by hand is a time-consuming and error-prone process. Neural architecture search (NAS) automates the design of NN architectures. NAS attempts to find well-performing NN models for specialized datsets, where performance is measured by key metrics that capture the NN capabilities (e.g., accuracy of classification of samples in a dataset). Existing NAS methods are resource intensive, especially when searching for highly accurate models for larger and larger datasets. To address this problem, we propose a performance estimation strategy that reduces the resources for training NNs and increases NAS throughput without jeopardizing accuracy. We implement our strategy via an engine called PEng4NN that plugs into existing NAS methods; in doing so, PEng4NN predicts the final accuracy of NNs early in the training process, informs the NAS of NN performance, and thus enables the NAS to terminate training NNs early. We assess our engine on three diverse datasets (i.e., CIFAR-100, Fashion MNIST, and SVHN). By reducing the training epochs needed, our engine achieves substantial throughput gain; on average, our engine saves 61% to 82% of training epochs, increasing throughput by a factor of 2.5 to 5 compared to a state-of-the-art NAS method. We achieve this gain without compromising accuracy, as we demonstrate with two key outcomes. First, across all our tests, between 74% and 97% of the ground truth best models lie in our set of predicted best models. Second, the accuracy distributions of the ground truth best models and our predicted best models are comparable, with the mean accuracy values differing by at most .7 percentage points across all tests.
翻译:神经网络(NN) 模型越来越多地用于科学模拟、 AI 和其他高性能计算(HPC) 领域,以从数据集中提取知识。 每个数据集都需要定制的 NN 模型结构,但手工设计结构是一个耗时和容易出错的过程。 神经结构搜索(NAS) 将NNS架构的设计自动化起来。 NAS试图为专门的 Datsets找到运行良好的NNN模型, 其性能通过关键指标衡量,该指标的性能能够捕捉NNS的能力(例如,在数据集中样本分类的准确性能)。 现有的NAS方法需要大量资源,特别是在寻找高度准确的NNS模型时,但手工设计结构是一个耗时和容易出错的过程。 神经结构搜索(NAS)将减少NNS培训的资源,增加NAS的造价,而不会损害精确性能。 我们通过一个称为PENG4N的引擎执行我们现有的NS方法; 这样做时, PEN4NN通过培训过程的早期所有61 的准确性能, 向NS 向NS 提供最差的NS 的模型, 最差的模型提供最差的模型, 在NIS 的模型中, 二级的模型中, 最低性能的模型中, 我们的模型中, 我们的S 将实现最差性能性能性能性能性能性能的S 的模型显示的模型, 我们的S 和最差的S 在S IM 的模型中, 通过S 的S IM 的模型,我们测算算算出最低的 。