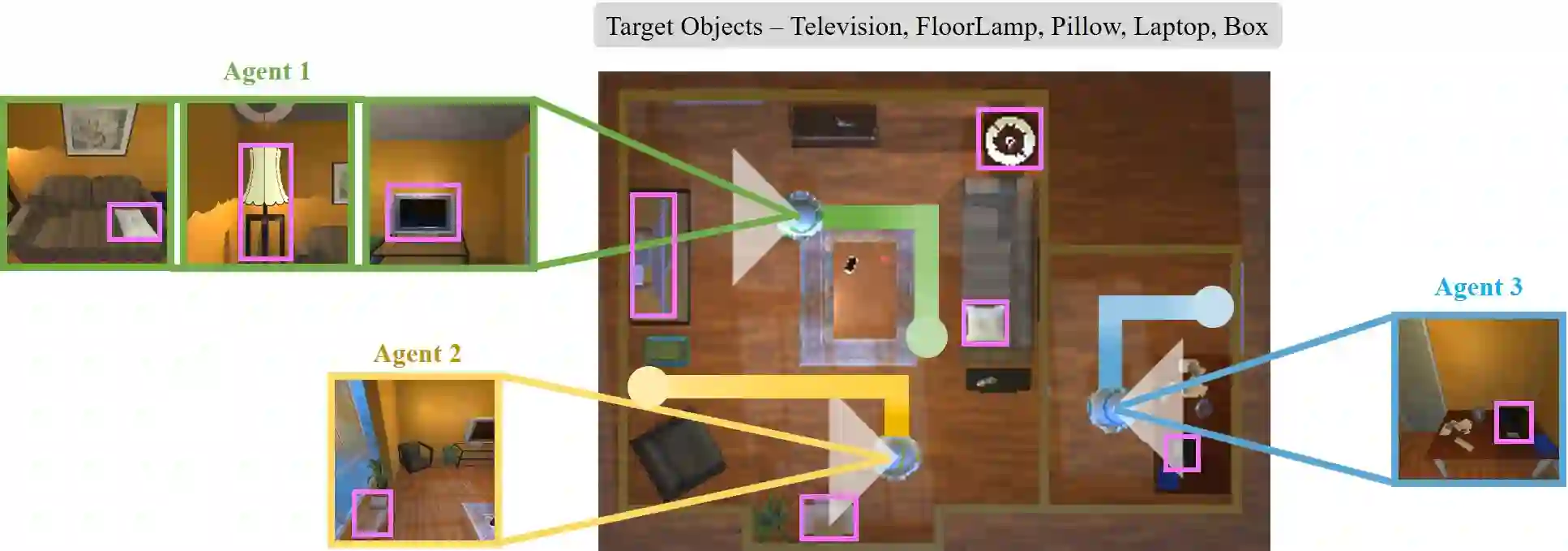
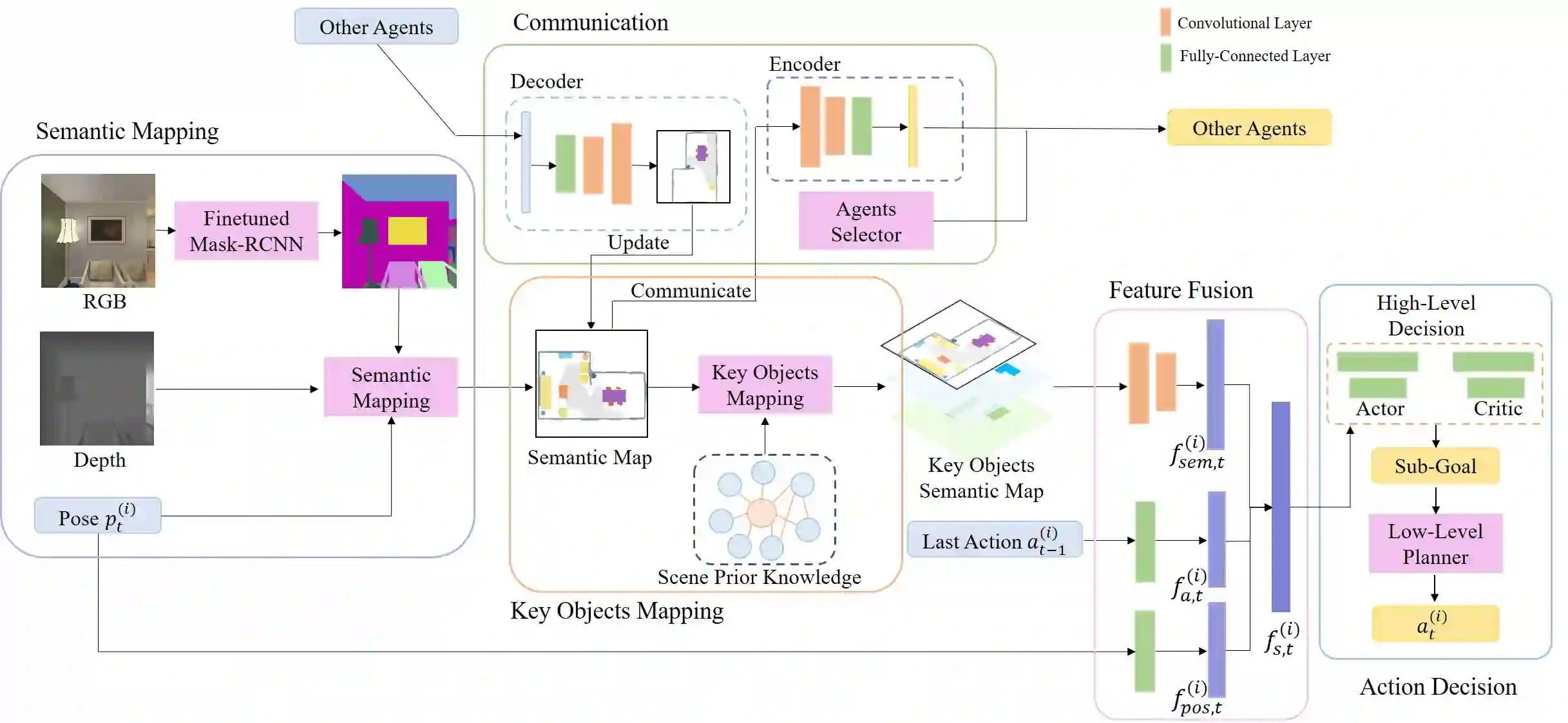
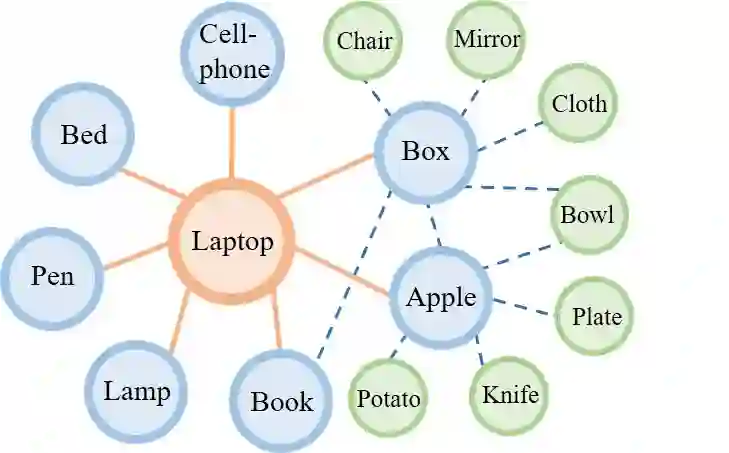
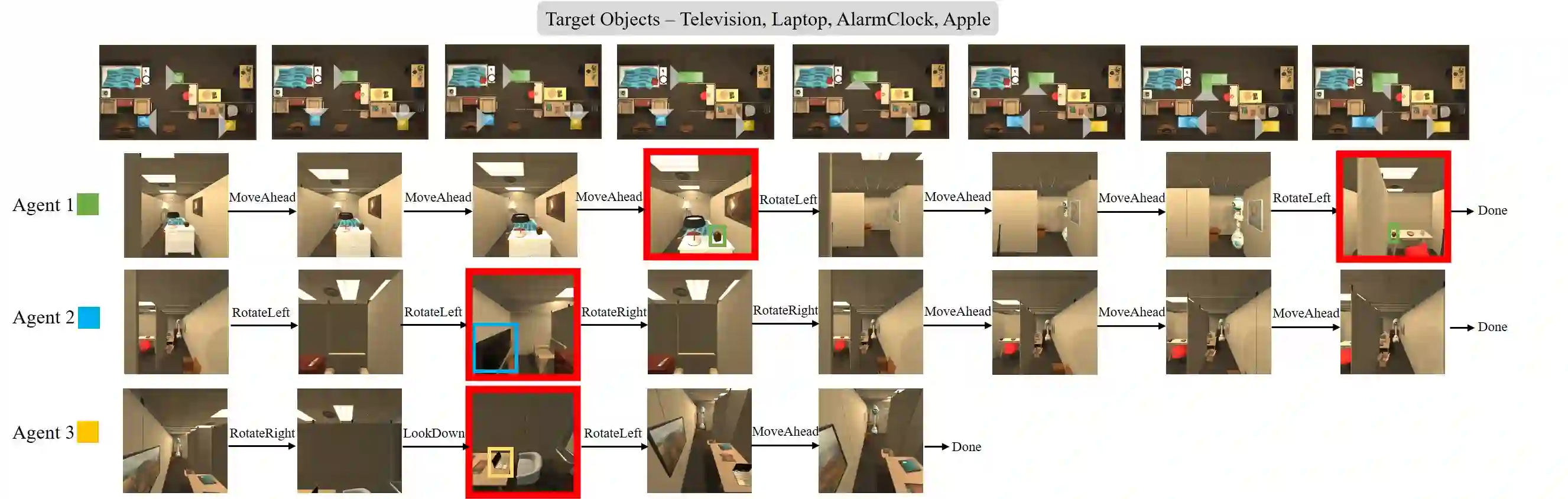
In visual semantic navigation, the robot navigates to a target object with egocentric visual observations and the class label of the target is given. It is a meaningful task inspiring a surge of relevant research. However, most of the existing models are only effective for single-agent navigation, and a single agent has low efficiency and poor fault tolerance when completing more complicated tasks. Multi-agent collaboration can improve the efficiency and has strong application potentials. In this paper, we propose the multi-agent visual semantic navigation, in which multiple agents collaborate with others to find multiple target objects. It is a challenging task that requires agents to learn reasonable collaboration strategies to perform efficient exploration under the restrictions of communication bandwidth. We develop a hierarchical decision framework based on semantic mapping, scene prior knowledge, and communication mechanism to solve this task. The results of testing experiments in unseen scenes with both known objects and unknown objects illustrate the higher accuracy and efficiency of the proposed model compared with the single-agent model.
翻译:在视觉语义导航中,机器人通过以自我为中心的视觉观察和目标的分类标签向目标对象导航,这是一项有意义的任务,激发了相关研究的激增。然而,大多数现有模型仅对单一试探导航有效,而单一剂在完成更复杂的任务时效率低,差错容忍度低。多剂协作可以提高效率,并具有强大的应用潜力。在本文件中,我们提议多剂视觉语义导航,其中多个剂与他人合作寻找多个目标对象。这是一项具有挑战性的任务,要求代理人学习合理的协作战略,以便在通信带宽的限制下进行有效的探索。我们根据语义绘图、先行知识和通信机制,开发一个等级决策框架,以解决这项任务。用已知的物体和未知物体对看不见的场景进行试验的结果表明,与单一试样相比,拟议模型的准确性和效率更高。