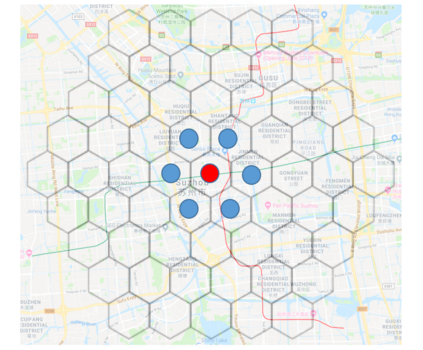
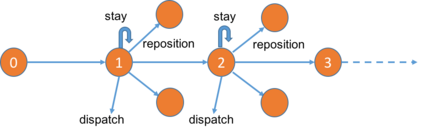
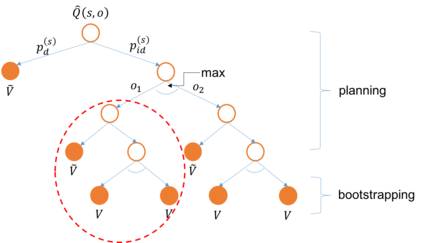
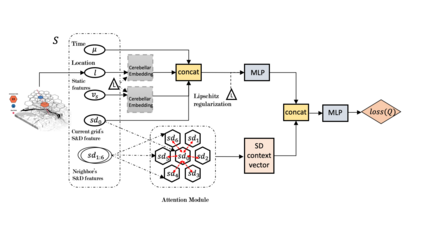
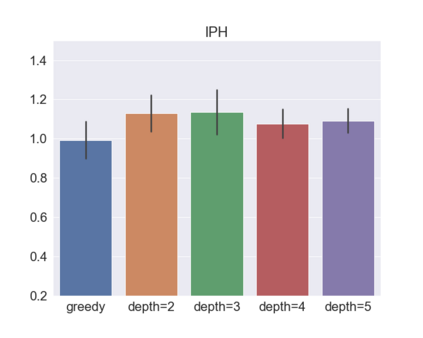
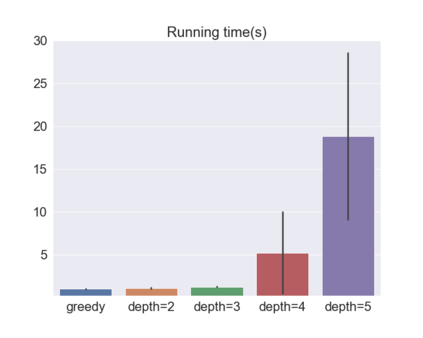
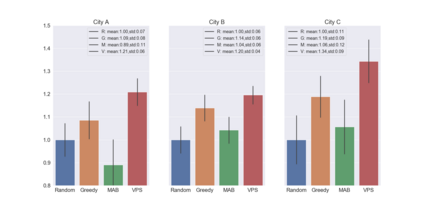
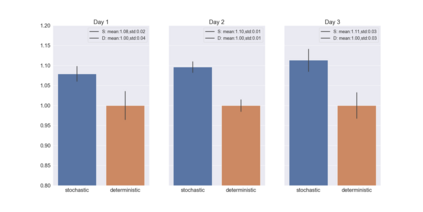
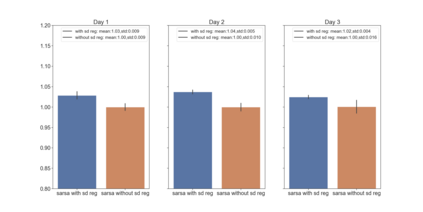
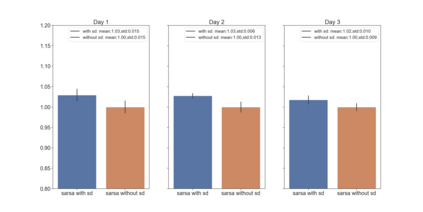
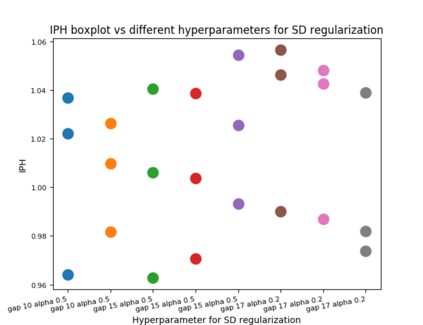
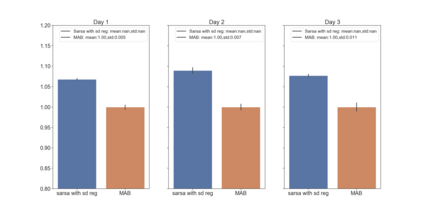
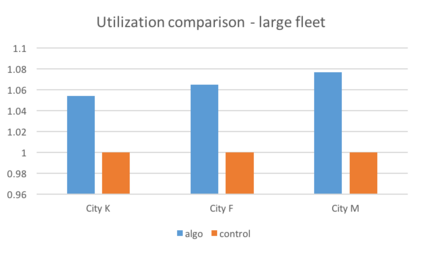
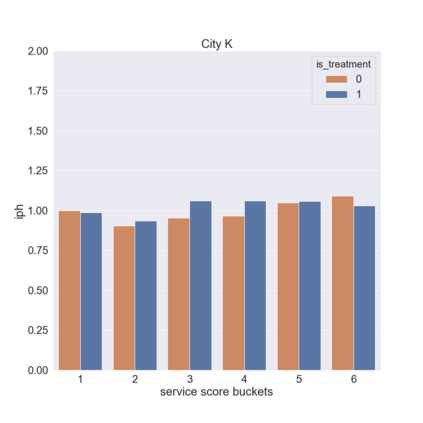
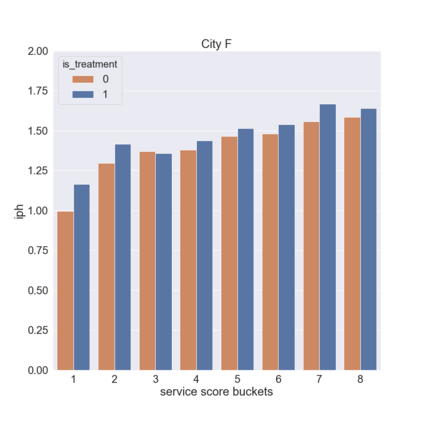
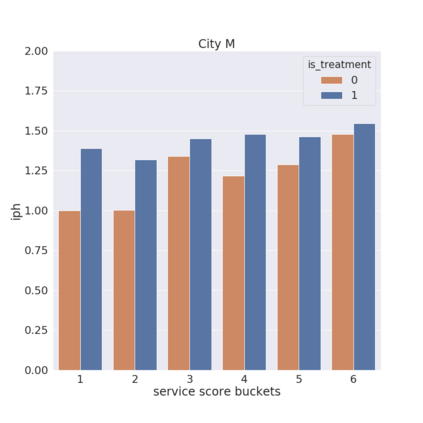
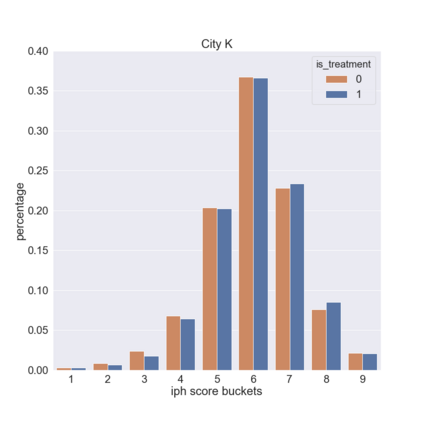
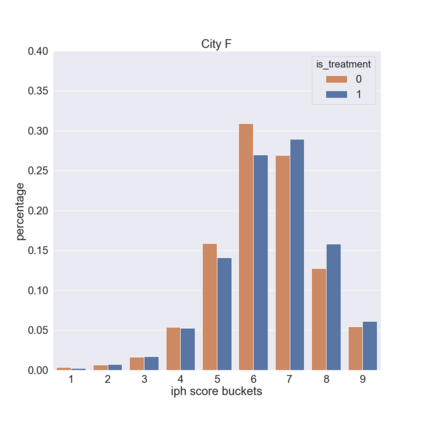
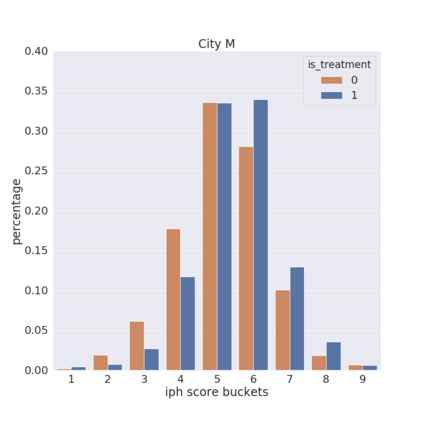
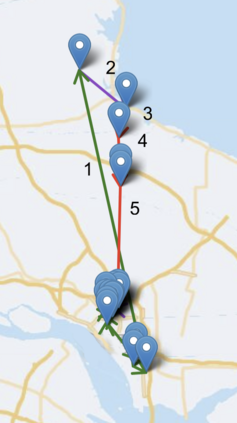
We present a new practical framework based on deep reinforcement learning and decision-time planning for real-world vehicle repositioning on ride-hailing (a type of mobility-on-demand, MoD) platforms. Our approach learns the spatiotemporal state-value function using a batch training algorithm with deep value networks. The optimal repositioning action is generated on-demand through value-based policy search, which combines planning and bootstrapping with the value networks. For the large-fleet problems, we develop several algorithmic features that we incorporate into our framework and that we demonstrate to induce coordination among the algorithmically-guided vehicles. We benchmark our algorithm with baselines in a ride-hailing simulation environment to demonstrate its superiority in improving income efficiency meausred by income-per-hour. We have also designed and run a real-world experiment program with regular drivers on a major ride-hailing platform. We have observed significantly positive results on key metrics comparing our method with experienced drivers who performed idle-time repositioning based on their own expertise.
翻译:我们提出了一个新的实用框架,其基础是深入强化学习和决定时间规划,以利实时机动车辆重新定位(按需流动,国防部)平台。我们的方法是利用具有深价值网络的批量培训算法,学习时空国家价值功能。最佳的重新定位行动是通过基于价值的政策搜索,将规划和靴子与价值网络结合起来,根据需求产生。对于大型飞行问题,我们开发了几种算法特征,将之纳入我们的框架中,并展示了在算法制车辆之间促成协调。我们用基线将我们的算法算法算法以搭乘模拟环境为基准,以显示其在提高收入效率方面的优势,通过每小时收入计算。我们还设计并运行了一个现实世界实验方案,定期司机在主要乘车平台上进行。我们观察到了在将我们的方法与经验丰富的驾驶员进行比较方面所取得的显著积极结果,这些驾驶员根据自己的专长进行了闲置的重新定位。