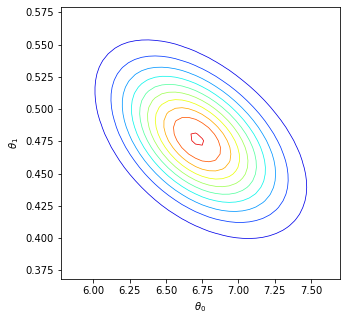
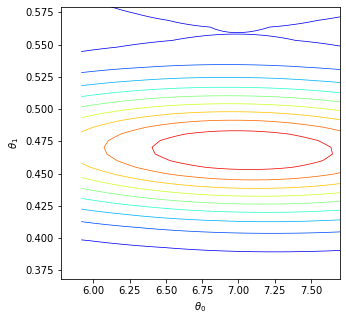
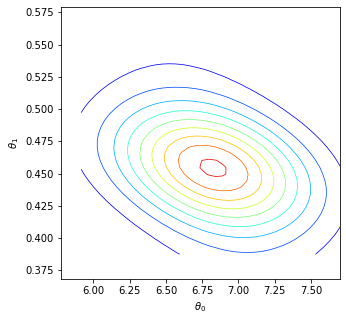
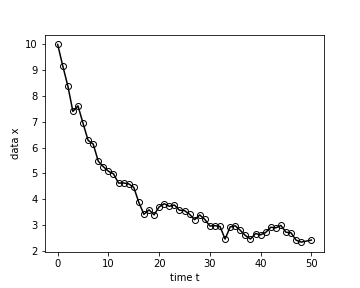
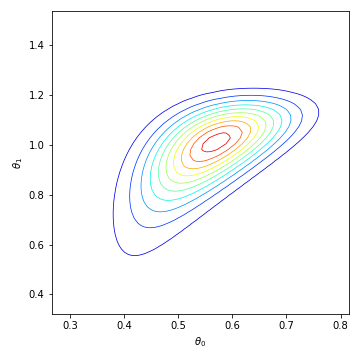
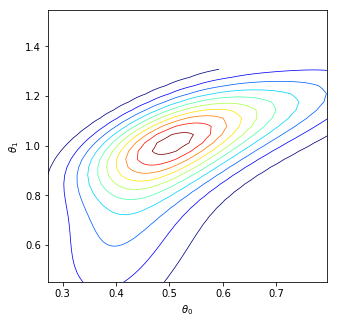
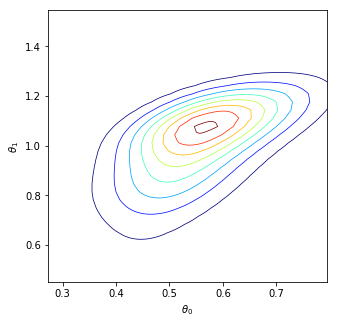
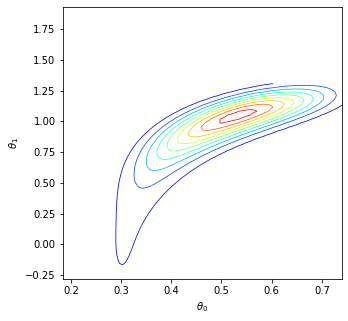
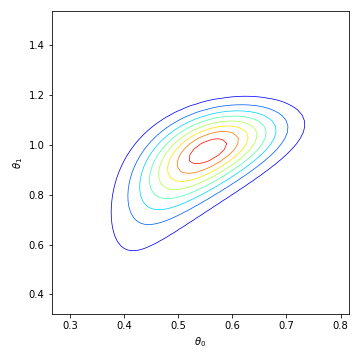
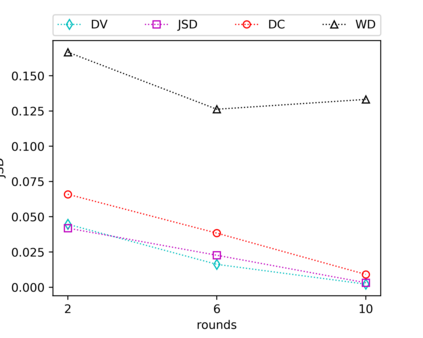
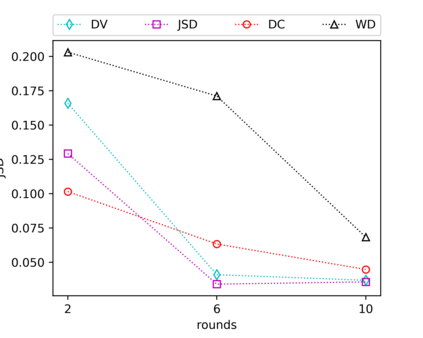
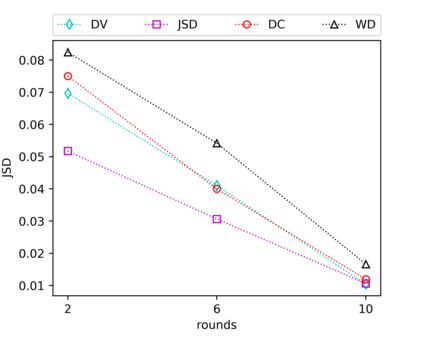
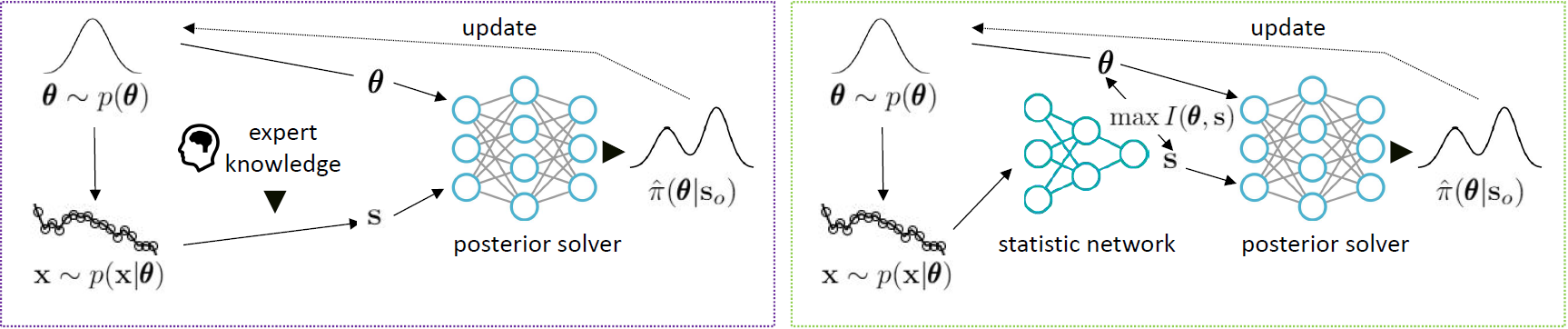
We consider the fundamental problem of how to automatically construct summary statistics for implicit generative models where the evaluation of the likelihood function is intractable, but sampling data from the model is possible. The idea is to frame the task of constructing sufficient statistics as learning mutual information maximizing representations of the data with the help of deep neural networks. The infomax learning procedure does not need to estimate any density or density ratio. We apply our approach to both traditional approximate Bayesian computation and recent neural likelihood methods, boosting their performance on a range of tasks.
翻译:我们考虑了如何为隐含基因模型自动构建简要统计数据的根本问题,在这些模型中,对可能性功能的评估难以解决,但有可能从模型中采集抽样数据,目的是通过在深层神经网络的帮助下学习相互信息,最大限度地体现数据,从而构建足够的统计数据。信息学学习程序不需要估计任何密度或密度比率。我们采用我们的方法,既采用传统的近似巴耶斯计算方法,又采用最近的神经概率方法,提高它们在一系列任务上的绩效。