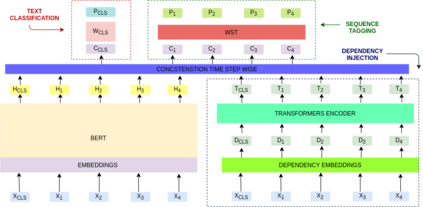
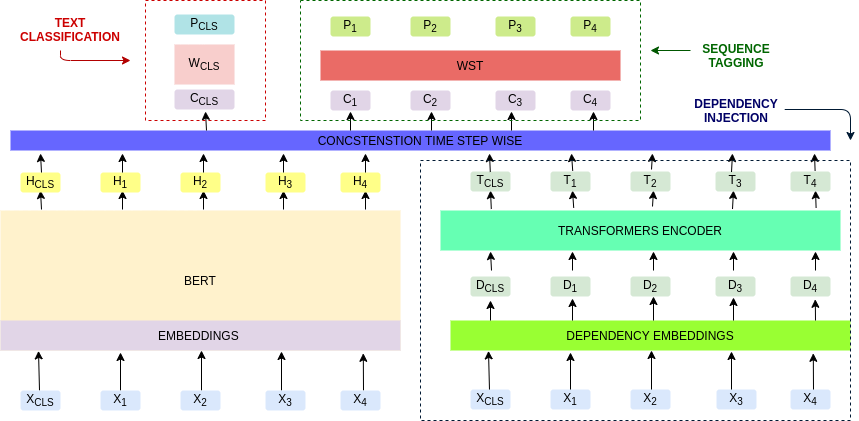
In this work, we retrained the distilled BERT language model for Walmart's voice shopping assistant on retail domain-specific data. We also injected universal syntactic dependencies to improve the performance of the model further. The Natural Language Understanding (NLU) components of the voice assistants available today are heavily dependent on language models for various tasks. The generic language models such as BERT and RoBERTa are useful for domain-independent assistants but have limitations when they cater to a specific domain. For example, in the shopping domain, the token 'horizon' means a brand instead of its literal meaning. Generic models are not able to capture such subtleties. So, in this work, we retrained a distilled version of the BERT language model on retail domain-specific data for Walmart's voice shopping assistant. We also included universal dependency-based features in the retraining process further to improve the performance of the model on downstream tasks. We evaluated the performance of the retrained language model on four downstream tasks, including intent-entity detection, sentiment analysis, voice title shortening and proactive intent suggestion. We observed an increase in the performance of all the downstream tasks of up to 1.31% on average.
翻译:在这项工作中,我们重新培训了Walmart语音购物助理的蒸馏BERT语言模型,用于零售特定域的数据。我们还注入了通用综合依赖性,以进一步提高该模型的性能。今天,语音助理的自然语言理解(NLU)部分在很多任务上都严重依赖语言模型。BERT和RoBERTA等通用语言模型对于依赖域的助理是有用的,但在满足特定域的需要时有局限性。例如,在购物域中,代号“horizon”是指品牌,而不是其字面含义。通用模型无法捕捉到这种微妙之处。因此,在这项工作中,我们重新培训了BERT语言模型关于Walmart语音购物助理零售特定域的数据的再生版版。我们还在再培训过程中纳入了通用依赖性特征,以进一步提高下游任务模式的性能。我们评估了四个下游任务的再培训语言模型的性能,包括意向识别、情绪分析、语音标题缩短和主动意向性意向性建议。我们观察到,在Walmart的下游任务中,平均提高了1%。