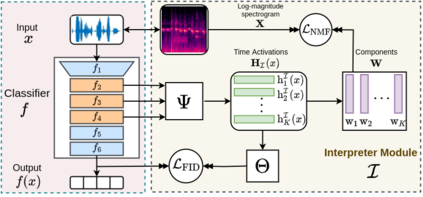
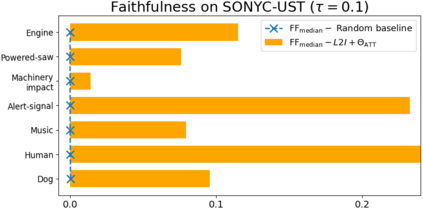
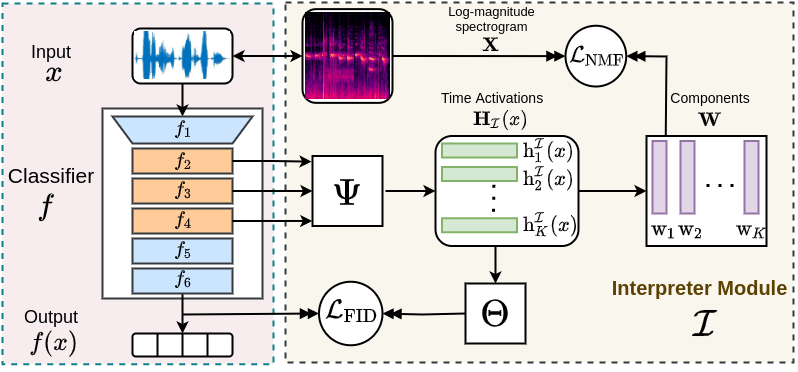
This paper tackles post-hoc interpretability for audio processing networks. Our goal is to interpret decisions of a network in terms of high-level audio objects that are also listenable for the end-user. To this end, we propose a novel interpreter design that incorporates non-negative matrix factorization (NMF). In particular, a carefully regularized interpreter module is trained to take hidden layer representations of the targeted network as input and produce time activations of pre-learnt NMF components as intermediate outputs. Our methodology allows us to generate intuitive audio-based interpretations that explicitly enhance parts of the input signal most relevant for a network's decision. We demonstrate our method's applicability on popular benchmarks, including a real-world multi-label classification task.
翻译:本文涉及对音频处理网络的控件后可解释性。 我们的目标是解释网络决定的高级音频物体,这些物品也可为终端用户所收听。 为此,我们提出新的翻译设计,纳入非负矩阵因子化(NMF ) 。 特别是, 精心规范的口译模块经过培训,将目标网络的隐性层表示作为输入,并生成作为中间输出的中位输出的预感性NMF组件的时间激活。 我们的方法允许我们生成直观的音频解释,以明确加强与网络决定最相关的部分输入信号。 我们展示了我们的方法对大众基准的适用性,包括现实世界多标签分类任务。