作者 | 刘旺旺
编辑 | 唐里
来源 | ICLR 2020 在审
链接 | https://arxiv.org/pdf/1909.10351.pdf
代码 | 暂未公布
动机
预训练的语言模型+微调的模式提升了很多nlp任务的baseline,但是预训练的语言模型太过庞大,参数都是百万级别,因此很难应用到实际的应用场景中,尤其是一些资源有限的设备上。
![]()
解决方法
文献(https://arxiv.org/pdf/1901.10430.pdf)等证明了预训练语言模型的参数是冗余的。
因此论文提出了一种基于transformer结构的知识蒸馏方法,用于bert的压缩和加速。
最终将模型大小减小为原来的1/7.5, inference的时间减少为原来的1/9.4,并且可以达到与原有bert模型相当的效果。
预备知识
transformer layer
包含两个部分:
Multi-Head Attention (MHA) 和 Position-wise Feed-Forward Network (FFN),bert主要的结构也是多层transformer layer的堆叠。
MHA层和FFN层之间,以及FFN层之后还包含一个残差连接和norm层,详细可见文献(https://arxiv.org/pdf/1706.03762.pdf)
Knowledge Distillation(KD)
知识蒸馏是一种模型压缩常见方法,指的是在teacher-student框架中,将复杂、学习能力强的网络(teacher)学到的特征表示“知识”蒸馏出来,传递给参数量小、学习能力弱的网络(student)。
teacher网络中学习到的特征表示可作为监督信息,训练student网络以模仿teacher网络的行为。
整个知识蒸馏过程的误差函数为:
其中,
x
是网络输入,L(⋅)是衡量在输入x下,teacher网络和student的网络的差异性,
![]() 是训练集。
是训练集。
![]() 和
和
![]() 分别表示teacher和student网络的行为函数,可以通俗理解成网络中特征表示。
从公式可看出,知识蒸馏的过程关键在于,如何定义网络的差异性loss,以及如何选取网络的行为函数。
分别表示teacher和student网络的行为函数,可以通俗理解成网络中特征表示。
从公式可看出,知识蒸馏的过程关键在于,如何定义网络的差异性loss,以及如何选取网络的行为函数。
基于transformer的知识蒸馏模型压缩
先前也有一些工作使用知识蒸馏的方法来做bert模型的压缩:
通过表格可以看出,论文tinybert的创新点在于学习了teacher Bert中更多的层数的特征表示,蒸馏的特征表示包括:
-
-
Transformer layer的输出以及注意力矩阵
-
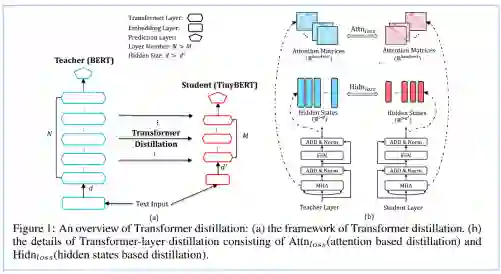
上图描述了bert知识蒸馏的过程,左边的图整体概括了知识蒸馏的过程:
左边是Teacher BERT,右边是Student TinyBERT,论文的目的是将Teacher BERT学习到的知识迁移到TinyBERT中;
右边的图描述了知识迁移的细节,在训练过程中选用Teacher BERT中每一层transformer layer的attention矩阵和输出作为监督信息。
假设 Teacher BERT 有M层,TinyBERT有N层(N<M), n = g(m) 是TinyBERT到Teacher BERT 映射函数,表示TinyBERT的第m层是从Teacher BERT中的第n层学习知识的。
Teacher BERT 词向量层和预测输出层的特征表示也被用于知识蒸馏。
TinyBERT词向量层和预测输出层是从Teacher BERT相应的层学习知识的。
将Teacher BERT 词向量层看作第0层,预测输出层看作M+1层,映射函数可表示为 0 = g(0), n = g(m), N+1=g(M + 1)
将Teacher BERT学习到的特征表示作为TinyBERT的监督信息,从而训练TinyBERT,训练的loss可表示为如下公式:
![]() 其中
其中
![]() 为当前层衡量Teacher BERT络和TinyBERT的差异性的loss函数,
为当前层衡量Teacher BERT络和TinyBERT的差异性的loss函数,
![]() 是超参数,代表当前层的重要程度。
对应不同的层,论文采用了不同的loss函数
论文第一次将attention矩阵作为知识蒸馏过程中teacher网络的监督信息。
因为 文献(https://arxiv.org/pdf/1906.04341.pdf)证明了attention举证中包含了语法和共指信息,通过将attention矩阵作为teacher网络中的监督信息,可以将这些信息迁移到student网络。
采用的是均方误差函数,
h
是atteniton的头数,每层共有
h
个注意力矩阵
A
。
是超参数,代表当前层的重要程度。
对应不同的层,论文采用了不同的loss函数
论文第一次将attention矩阵作为知识蒸馏过程中teacher网络的监督信息。
因为 文献(https://arxiv.org/pdf/1906.04341.pdf)证明了attention举证中包含了语法和共指信息,通过将attention矩阵作为teacher网络中的监督信息,可以将这些信息迁移到student网络。
采用的是均方误差函数,
h
是atteniton的头数,每层共有
h
个注意力矩阵
A
。
![]() 是teacher Bert或者tinyBert中的注意力矩阵,
l
是输入文本的长度。
是teacher Bert或者tinyBert中的注意力矩阵,
l
是输入文本的长度。
![]()
同样使用均方误差函数,使用Wh进行维度转换
同样使用均方误差函数,使用We进行维度转换
仅在微调阶段的知识蒸馏过程中使用,
同样使用均方误差函数,使用Wh进行维度转换
同样使用均方误差函数,使用We进行维度转换
仅在微调阶段的知识蒸馏过程中使用,
![]() 和
和
![]() 分别表示teacher Bert和tinyBert网络在具体下游任务中预测层输出。
t是知识蒸馏中的温度参数,实验中被设置为1.
分别表示teacher Bert和tinyBert网络在具体下游任务中预测层输出。
t是知识蒸馏中的温度参数,实验中被设置为1.
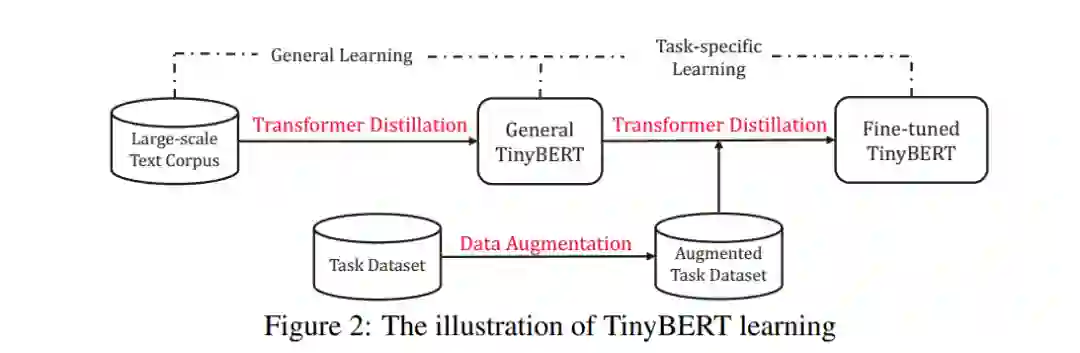
Pre-training和Fine-tuning两个阶段知识蒸馏
知识蒸馏的过程也被分为两个阶段, General distillation (Pre-training阶段),使用大规模无监督的数据, 帮助student网络TinyBERT学习到尚未微调的teacher BERT中的知识,有利于提高TinyBERT的泛化能力。此时,由于词向量维度的减小,隐层神经元的减少,以及网络层数的减少,tinybert的表现远不如teacher bert。(注意:在Pre-training阶段,蒸馏的特征表示未使用预测层输出)
task-specific distillation(Fine-tuning阶段),使用具体任务的数据,帮助TinyBERT学习到更多任务相关的具体知识。
值得注意的是,在Fine-tuning阶段,论文采用了数据增强的策略,从后面的实验中可以看出,数据增强起到了很重要的作用。
数据扩充的过程如下:
对于特定任务的数据中每一条文本,首先使用bert自带的方式进行bpe分词,bpe分词之后是完整单词(single-piece word),用[MASK]符号代替,然后使用bert进行预测并选择其对应的候选词N个;
如果bpe分词之后不是完整单词,则使用Glove词向量以及余弦相似度来选择对应的N个候选词,最后以概率
![]() 选择是否替换这个单词,从而产生更多的文本数据。
选择是否替换这个单词,从而产生更多的文本数据。
实验结果
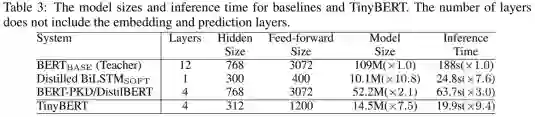
TinyBERT(参数个数14.5M):
网络层数
M=4
, 隐层维度
![]() ,FFN层维度
,FFN层维度
![]() ,h=12
Techer BERT(参数个数109M):
网络层数
N=12
, 隐层维度
d=768
, FFN层维度
,h=12
Techer BERT(参数个数109M):
网络层数
N=12
, 隐层维度
d=768
, FFN层维度
![]() ,
h=1
2
映射函数:
g(m)=3×m
每层的重要性参数λ设置为1
实验结果
,
h=1
2
映射函数:
g(m)=3×m
每层的重要性参数λ设置为1
实验结果
![]()
-
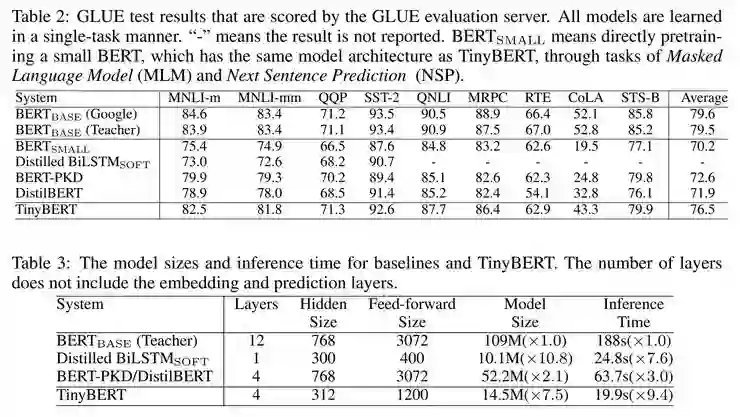
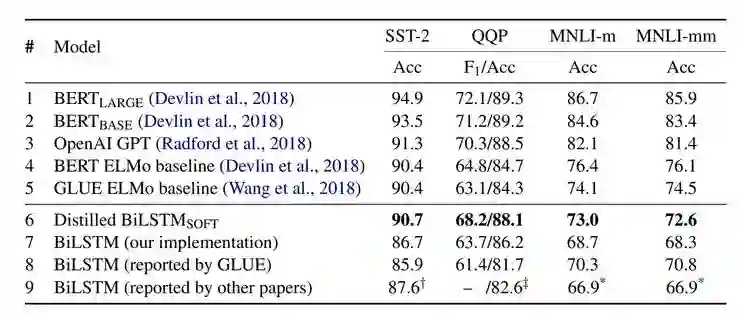
由于参数的减小,Bert small 与 Bert base相比,效果相差很大
-
TinyBERT 效果在所有任务上都超越了 Bert small,最多平均提升了6.3%
-
TinyBERT 的效果也优于先前的基于知识蒸馏的模型压缩方法BERT-PKD 和 DistillBERT
-
TinyBERT模型大小减小为原来的7.5分之一,Inference的时间减少为原来的9.4分之一
-
TinyBERT模型大小比Distilled BiLSTM大。
但是,Inference 速度要比Distilled BiLSTM快,并且在所展示的任务上效果都超过了Distilled BiLSTM
-
对于CoLA这个数据集,所有压缩模型的效果都不如Bert base,但是相比于其他压缩模型,TinyBERT有最好的效果。
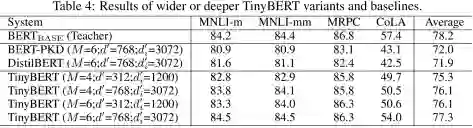
CoLA是判断一句话是否语法正确的数据集,需要更多语言学知识,需要更大的网络去拟合,随着TinyBERT参数增大,也能提高TinyBERT在该数据集上的效果,Table 4 也证明了这个结论。
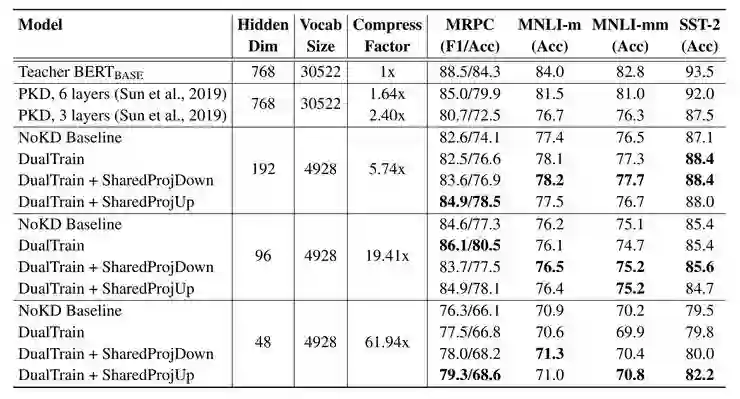
通过尝试更深更宽的网络实验结果如Table 4 所以,可以得到如下结论:
-
论文提出的知识蒸馏的方法,适用于任何大小的TinyBERT
-
对于Cola数据集,加深加宽网络可以能带来效果的大幅提升 (f49.7 -> 54.0),仅仅加宽或加深带来的提升不大
-
4层的TinyBERT比6层的其他压缩的模型效果要好,这也证明了论文提出模型的有效性
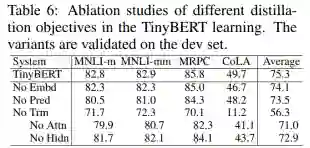
分析两个阶段的知识蒸馏 TD (Task-specific Distillation)和GD (General Distillation),以及数据扩充DA (Data Augmentation) 对TinyBERT整体效果的作用
-
总体可看出,去掉TD和DA对整体结果影响较大,去掉GD对整体的结果作用较小
-
去掉GD对CoLA的作用大于MNLI和MRPC(CoLA在没有GD的情况下降了9%),CoLA是判断一句话是否语法正确的数据集,需要更多语言学知识,而GD的过程正是捕获这种知识的手段。
分析知识蒸馏过程中,选取的不同的特征表示对整体结果的作用
-
没有Transformer层对模型的影响最大,Transformer层是整个模型的主要构成部分
-
Transformer层中attention矩阵相比隐层输出的作用要大
-
整体来说,Transformer层,embeding层,预测输出层,对于提高模型的整体效果都是有效的。
分析知识蒸馏的过程中,使用不同的映射函数, 对整体结果的作用
-
-
Top-strategy和Bottom-strategy相比,在不同的任务上,效果优劣不一。
总结
论文提出一个基于知识蒸馏进行模型的压缩的方法,分别对bert的预训练阶段以及微调阶段进行知识蒸馏。创新部分在于,使用更多的teacher bert的学习到的知识(不同层的特征表示)作为student网络的监督信息。实验结果表明,与先前的知识蒸馏用于模型压缩的方法的相比,论文提出的方法更有效,提升效果的同时更加快了inference速度。实验翔实,具有参考意义。
但是从table5可以看出数据增强的对模型最终的效果影响很大。在CoLA数据集上,tinyBert不用数据增强(No DA)的结果低于table2中DistilBERT的结果;在MRPC数据集上,则结果相当。table2 中用于对比的方法并未使用该数据增强的方法,若能增加一组实验会更有说服力。
延伸阅读:
蒸馏
另一个有趣的模型压缩方法是蒸馏,这是一种将大型「teacher」网络的知识转移到较小的「student」网络的技术,训练学生网络来模仿教师网络的行为。
Rich Caruana 及其合作者率先采用了这种策略。在他们先驱性的论文中,他们提供了令人信服的证明:大型集成模型所获得的知识可以转移到单个小型的模型中。
Geoffrey Hinton 等人在他们的「Distilling the Knowledge in a Neural Network」论文中证明了这种技术可以应用于神经网络模型。
DistilBERT
从 Hinton 开始,蒸馏的方法逐渐被应用到了不同的神经网络中,当然你可能也听过 HuggingFace 提出的 DistilBERT,这是一种对 BERT 的蒸馏。这项工作出自论文「DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter」,目前已经提交到 NeurIPS 2019。
DistilBERT 是一种较小的语言模型,受 BERT 的监督而训练。在该模型中,作者删除了令牌类型嵌入和合并器(用于下一个句子分类任务),并保持体系架构其余部分不变,同时将层数减少了两倍。
您可以在 HuggingFace(以前叫做 pytorch-transformers 和 pytorch-pretrained-bert)的 translators python 软件包的帮助下,使用现成的 DistilBERT。该软件包的 2.0.0 版本支持 TensorFlow 2.0 / PyTorch 互操作。
DistilBERT 的作者还使用了最新 RoBERTa 论文中的一些训练技巧,这些技巧表明 BERT 的训练方式对其最终性能至关重要。
DistilBERT 与 BERT 相比具有出人意料的结果:作者保留了 95%以上的性能,但参数却减少了 40%。
在推断时间方面,DistilBERT 比 BERT 快了 60%以上,比 ELMo + BiLSTM 快 120%。
TinyBERT
就在几天前,出现了一种新的 BERT 蒸馏方法,来自华为诺亚方舟实验室的刘群团队提出了 TinyBERT。
为了构建一个具有竞争力的 TinyBERT,作者首先提出了一种新的 Transformer 蒸馏方法,来蒸馏嵌入 BERT 的知识。
具体来说就是,他们设计了几个损失函数来适合 BERT 层的不同表示形式:
2、Transformer 层派生的隐藏状态和注意力矩阵;
论文中基于注意力的拟合则得益于最近的发现,即 BERT 学习的注意力权重可以捕获大量的语言知识,这意味着语言知识可以很好地从教师 BERT 转移到学生 TinyBERT。而在 BERT 的现有知识蒸馏的方法(如 Distilled BiLSTM_SOFT,BERT-PKD 和 DistilBERT)中却忽略了这一点。
在这项工作中,作者还提出了一种新颖的两阶段学习框架,包括通用蒸馏和特定任务蒸馏。在通用蒸馏阶段,未经微调的原始 BERT 充当教师模型,学生 TinyBERT 通过在通用领域对大型语料库执行通常的 Transformer 蒸馏来学习模仿教师的行为。他们获得了可以对各种下游任务进行微调的通用 TinyBERT。在特定任务蒸馏阶段,他们将数据进行扩充,来提供更多与任务相关的材料供教师-学生学习,然后在增强的数据上重新执行 Tranformer 蒸馏。
这个两阶段方法对于提升 TinyBERT 的性能和泛化能力是必不可少的。
TinyBERY 在实验上取得了非常的成绩,相对于 GLUE 数据集的 BERT-base,其性能并没有下降多少,而推理参数小了 7.5 倍,推理时间快了 9.4 倍。
我们期待他们能够将这种方法应用到 BERT-large 和 XLNet 等大型模型中,同样也期待他们开放源码。
其他蒸馏方法
除了 DistilBERT 和 TinyBERT 外,还有其他一些为大家所熟知的蒸馏方法。
(2019/03)「Distilling Task-Specific Knowledge from BERT into Simple Neural Networks」
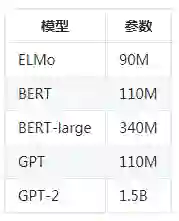
这篇论文将 BERT 蒸馏到单层 BiLSTM 中,取得了与 ELMo 可比的结果,同时使用的参数减少了大约 100 倍,推理时间减少了 15 倍。
BiLSTM_SOF 是 TBiLSTM 的蒸馏,后者是在 soft logit 目标上训练出来的。
(2019/08)「Patient Knowledge Distillation for BERT Model Compression」
这篇论文提出了一种耐心知识蒸馏的方法,这是首次尝试使用教师的隐藏状态,而不仅仅是最后一层的输出。他们的学生模型从教师模型的多个中间层「耐心」地学习来获得更多知识。在他们的耐心蒸馏知识框架中,只训练学生模仿中间层的 [CLS] 令牌的表示形式。代码已公开。
(2019/09)「Extreme Language Model Compression with Optimal Subwords and Shared Projections」
这是最近提交到 ICLR 2020 的一篇论文,这篇论文专注于一种用于训练词汇量显著较小、嵌入和隐藏状态维度较低的学生模型的知识蒸馏技术。作者采用了双重训练机制,可以同时训练教师和学生模型,从而能够获得针对学生词汇的最佳词嵌入。该方法能够将 BERT-base 模型压缩 60 倍以上,而下游任务指标只有很小的下降,从而使得语言模型占用的空间只有不到 7MB。
TinyBERT 的结果似乎更好,但一个 7MB 的类 BERT 模型简直爽的不能再爽!
![]()
![]() 点击“阅读原文”加入ICLR 顶会交流小组
点击“阅读原文”加入ICLR 顶会交流小组


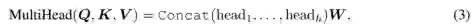
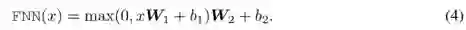
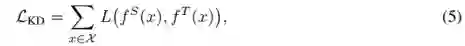
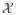 是训练集。
是训练集。
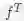 和
和
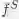 分别表示teacher和student网络的行为函数,可以通俗理解成网络中特征表示。
从公式可看出,知识蒸馏的过程关键在于,如何定义网络的差异性loss,以及如何选取网络的行为函数。
分别表示teacher和student网络的行为函数,可以通俗理解成网络中特征表示。
从公式可看出,知识蒸馏的过程关键在于,如何定义网络的差异性loss,以及如何选取网络的行为函数。

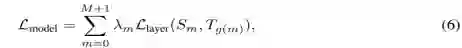
 为当前层衡量Teacher BERT络和TinyBERT的差异性的loss函数,
为当前层衡量Teacher BERT络和TinyBERT的差异性的loss函数,
 是超参数,代表当前层的重要程度。
是超参数,代表当前层的重要程度。
 是teacher Bert或者tinyBert中的注意力矩阵,
是teacher Bert或者tinyBert中的注意力矩阵,
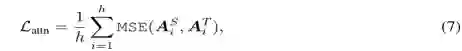


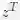 和
和
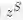 分别表示teacher Bert和tinyBert网络在具体下游任务中预测层输出。
t是知识蒸馏中的温度参数,实验中被设置为1.
分别表示teacher Bert和tinyBert网络在具体下游任务中预测层输出。
t是知识蒸馏中的温度参数,实验中被设置为1.
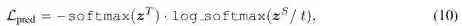

 选择是否替换这个单词,从而产生更多的文本数据。
选择是否替换这个单词,从而产生更多的文本数据。

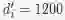 ,FFN层维度
,FFN层维度
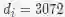 ,
,