自动驾驶感知技术的实践与探索

分享嘉宾:王超 智加科技 技术专家
编辑整理:Hoh Xil
内容来源:DataFunTalk
出品平台:智加科技、DataFun
注:欢迎转载,转载请留言。
导读:自动驾驶中的感知技术如同驾驶员的"眼睛"和"耳朵",在高速重卡的场景中,感知技术将面临哪些挑战?在量产化道路中,如何让感知技术与产品相结合去看清和理解足够的场景,本文将分享我们的一些心得体验。
以下Enjoy~
大家好,很高兴今天给大家分享智加科技在感知技术上的实践和探索,在前面的环节,江博士已经介绍了很多深度学习在智加自动驾驶中的很多应用,这里我特地给大家多介绍一些感知方面,深度学习(还包括其它的一些传统方法)能够落地的一些方法和实践,尤其是我们在实践过程中遇到的一些技术问题和一些有意思的case,以及我们量产过程中遇到的一些问题,都会跟大家一起做一些分享,大家也可以留言跟我们讨论。
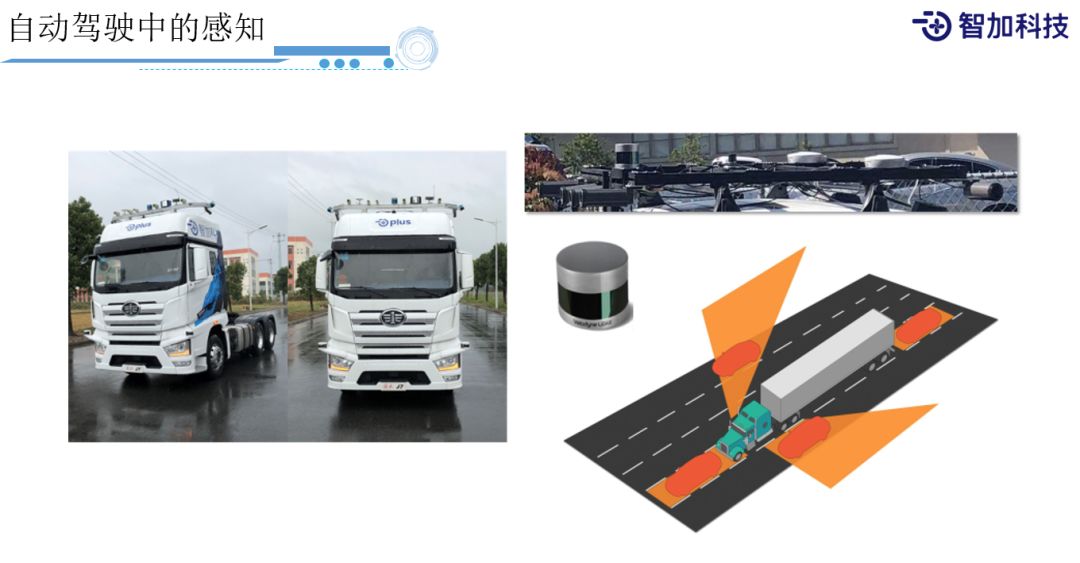
这里,感知的定义就不多介绍了,感知是我们自动驾驶的"眼睛"和"耳朵",是自动驾驶信息获取的第一步,所以感知是非常基础和关键的一个环节。这需要在我们的自动驾驶车辆上布满传感器,这样才能360°无死角的知道周边的各种情况,而且不止包括我们的"眼睛"Camera,还包括我们的"耳朵"激光雷达和毫米波雷达等非视觉传感器,这些在我们的测试车辆上都是必备的,我们可以从上图中看到,我们的车辆上布满了传感器,车前、车尾、车顶都会存在传感器。

自动驾驶车辆除了能看到东西之外,关键还是需要理解它。只有理解它之后获得的信息,才对我们后续的处理有意义,所以需要识别,那么,对于自动驾驶而言,需要识别什么?显而易见,第一个是车道线,我们知道车道线才能知道怎么开;然后我们还需要知道红绿灯,以及非常重要一点,就是动态障碍物(如前面有什么车辆),这是非常重要的;还有就是行人(对于城区的自动驾驶是非常关键的)。对于智加的重卡自动驾驶中,最重要的还是车道线和动态障碍物,所以这两方面会重点进行介绍。
1. 车道线检测
① 传统方法到深度学习方法

首先是车道线检测。从图像来看,车道线相对而言比较有规律,所以用一些传统的视觉算法就能取得不错的效果,比如对输入的数据做变换之后,做边缘检测(Edge Detection)和霍夫变换(Hough Transform)就能够识别出图像上的这些很像车道线的形状了。其中边缘检测是非常关键的一环,根据像素和像素之间的差值做一个滤波,找到差异点的线段,这就是传统的方法。但是传统方法会遇到瓶颈,因为要处理的场景非常多:
不同的光线;不同的车道线形状;车道线本身不同程度的破损;或者是它的一些噪音,尤其是一些障碍物的遮挡,如大量车辆遮挡的情况下,用传统方法很快就会遇到瓶颈,调参数是调不过来的。
所以,我们采用深度学习的方法来解决。
② 基于深度学习的方法
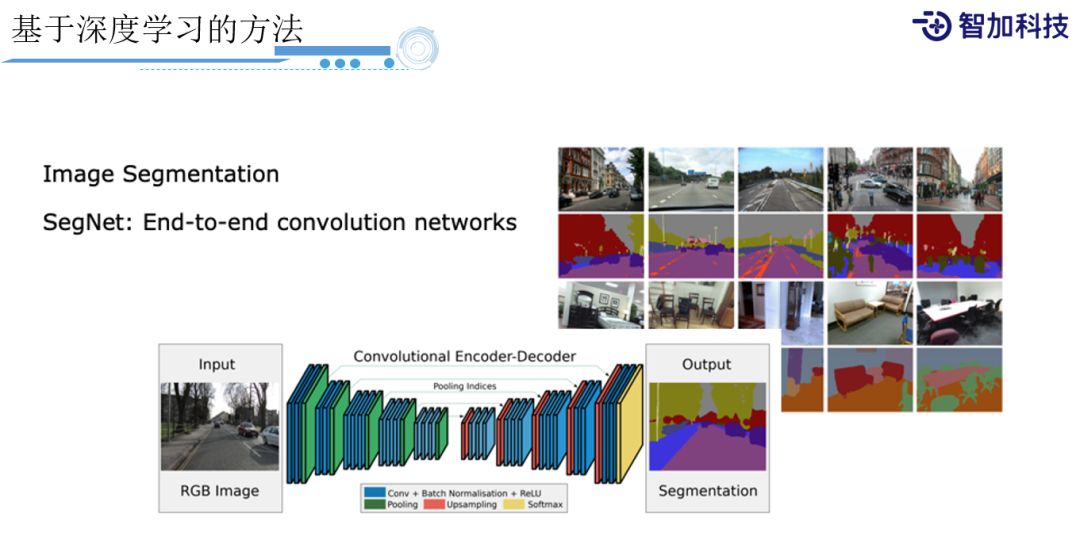
对于深度学习,业界已经有很多成熟的方法。这里很重要的就是图像分割,我们会给图像上每一个pixel(像素)都去预测它到底是什么样的分类,然后在打标的时候,也会标注图像上到底哪些是车道线,哪些是障碍物,哪些是天空,哪些是树木,等不同类型的标签。我们通过这样一个卷积的网络,类似Encoder-Decoder架构,先去做encoding到feature map,然后再deconvolution到一个大的feature map,然后再预测每个pixel跟ground truth之间分类的loss,比如用Softmax或者cross entropy都是可以的,最后我们就能学习出每个pixel是什么分类。但是光知道图像的分类可能还不够。
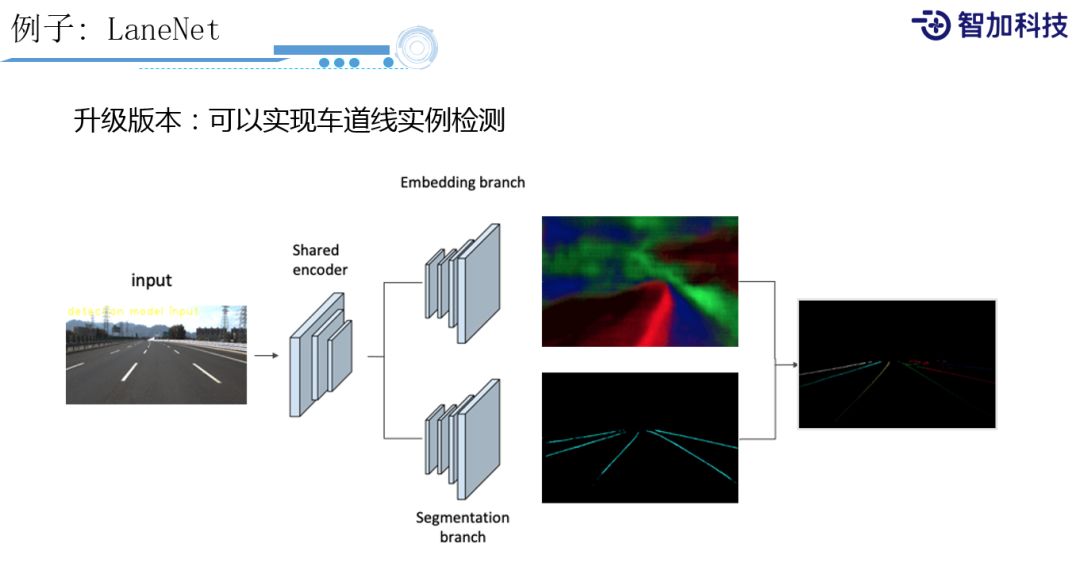
我们还需要进一步知道,到底图像上有几条车道线,哪些车道线是属于一条车道的?这里简单介绍下,我们会按照图中的做法,先把图像做encoding之后会分成两个branch,一个是Embedding branch,用来生成每个pixel的向量,这个向量可以告诉你它跟不同实例距离的分布,另外一个是Segmentation branch传统的分类网络。Embedding branch 向量计算出来之后和ground truth点的向量之间计算距离,这样就可以知道跟ground truth点之间有多近,和非ground truth点之间有多远,用这个距离当做loss,最后再结合分类的loss,得出最终的结果。
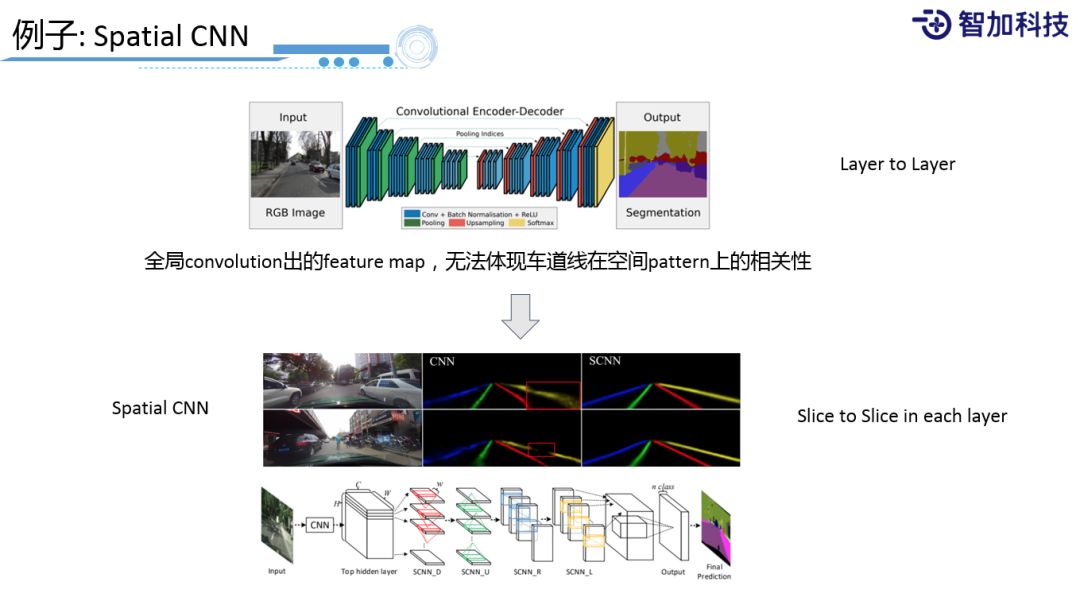
刚刚说的这些方法其实都是基于convolution这样传统的方法来去做的,它有一个局限,我们知道CNN是对整个图片都去做一次卷积,输出的feature map反映的还是整个图片的特性。但是对于车道线而言,它其实是很有规律的,就是近处看到一个车道线,在远处还是同一个车道线,是一个很有复制性的pattern,所以业界提出了一个很好的方法,叫Spatial CNN,把整个空间按照一个sliding window结合相邻window上一次的输出,叠加到新的sliding window输入上,相当于在图像上的RNN,只不过它是在一个单层的图像上来做的。通过这种方法就能学习出空间上的pattern,得到更好的车道线精度,对于我们来说是非常有用的。
2. 障碍物检测
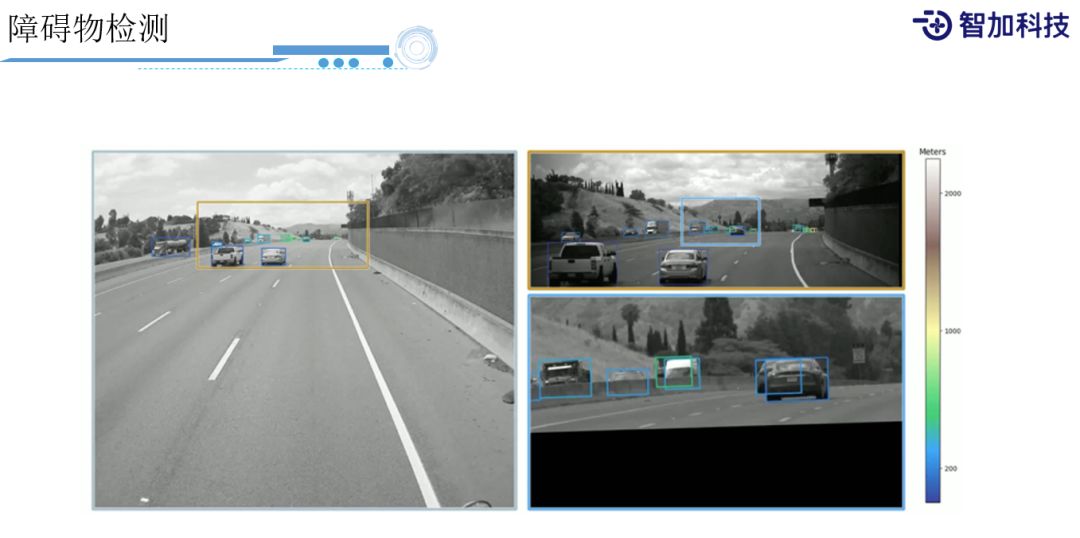
我们再来看下Object Detection,对于障碍物而言,它的pattern不像车道线那样有规律,而且非常的离散,所以单纯的用分割网络是很难解决的。所以我们还会用到现在业界比较成熟的Object Detection的方法。
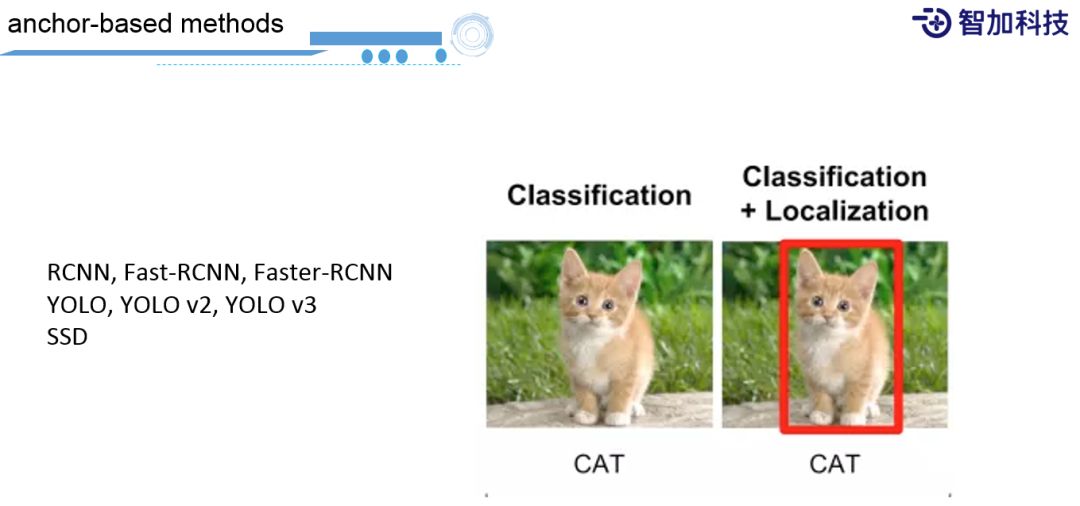
什么是Object Detection?传统的分类,只需要告诉你这个图片或者pixel是什么类型就可以了。对于Object Detection还要告诉图片上物体的位置、大小以及位置所对应的框里边的分类,是什么类型的物体。比较成熟的方法有:RCNN,Fast-RCNN,Faster-RCNN,YOLO,YOLO v2,YOLO v3,SSD等。
① Faster RCNN
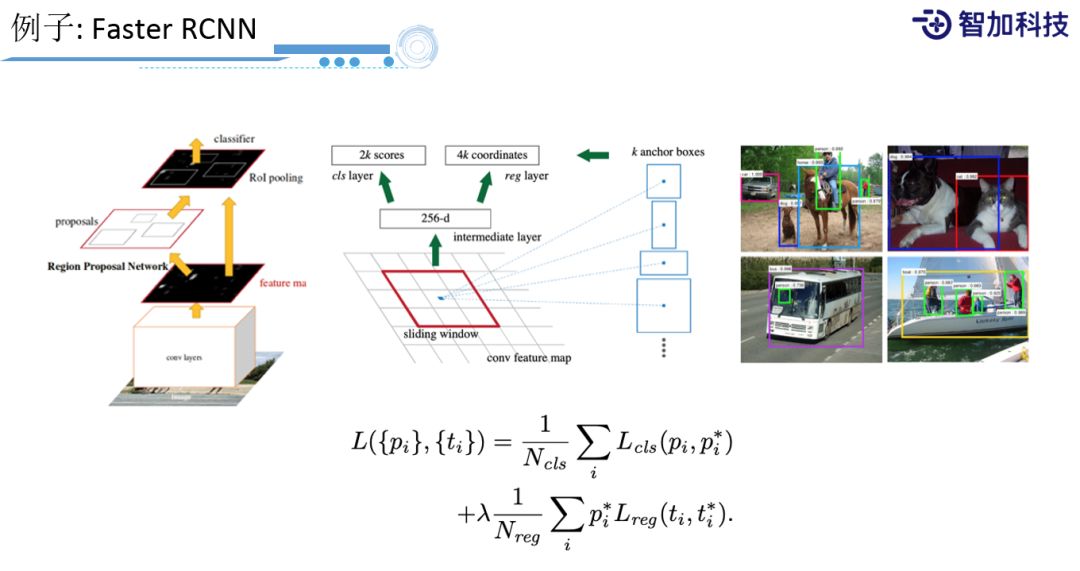
其中Faster RCNN是一个非常经典的做法,它是一个两阶段的算法,首先把图像通过卷积网络生成feature map,在feature map基础上预测出feature map上都有哪些region,region就相当于bounding box,预测出bounding box后, 再通过分类网络预测bounding box里面的图像,到底是什么样的类型。然后这两个网络会share之前的convolution network,所以在性能和效果上会达到一个比较好的tradeoff。同时,这里可以看到region proposal network是整个网里最关键的一个环节,它将整个网络划分成若干个grade,每个grade上的点生成固定的K个anchor boxes的候选,每个anchor box预测出它跟ground truth坐标的差距是多少,它是一个regression network。还有一个network是预测出物体到底是前景,还是背景,一个二分类网络。所以将这两个loss合并起来,当做整个学习的目标。所以,这也是为什么把这种方法叫做anchor-based,这里的anchor就是指region box。
② YOLO
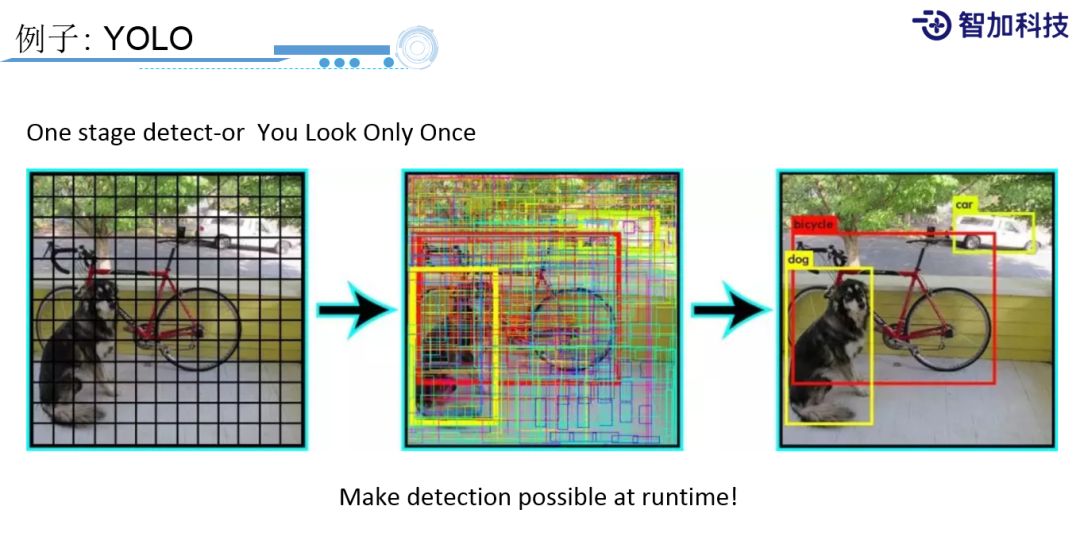
再进一步,业界又提出,可以一步就完成region预测和它的分类预测。比如YOLO,You Look Only Once这种方法,每个点会候选出若干个bounding box和sliding window,每个sliding window还有若干个要预测的分类,一步就能预测出分类和它对应的region box,让你的性能得到很大的提升。所以,现在很多业界主流都会用这样的方法。
③ 大物体检测
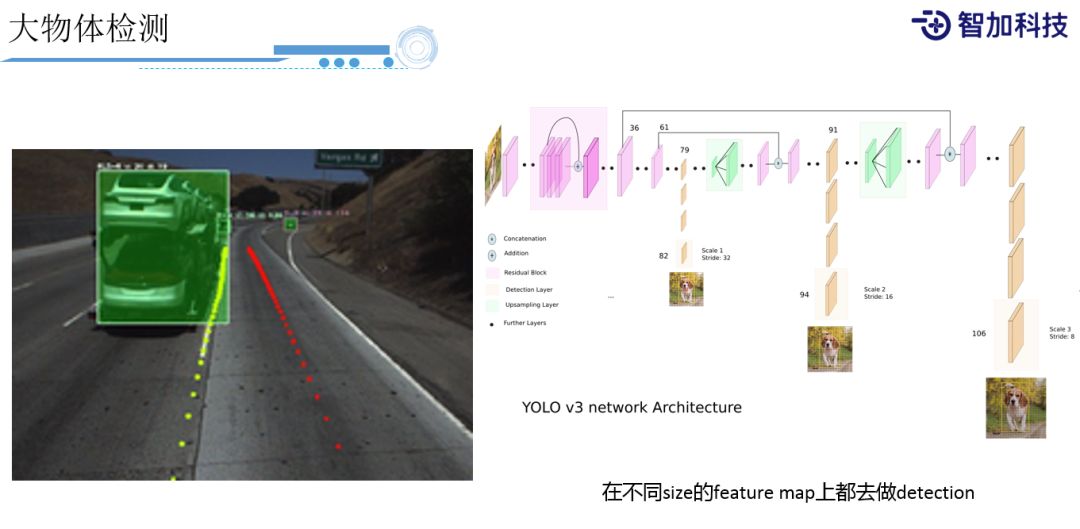
我们可以看下,我们采用这些方法后,实际中遇到的一些很有趣的问题。如左图,大家可以看到这是一个大车,是一个上下两层装载了很多小汽车的货车,从后面看它是两个小车,所以它到底是一个大车还是小车?这对于物体识别来说是一个很具有挑战性的例子,但我们还是能很稳定的识别出来。在这里,我们就借鉴了YOLO v3的思想,把feature map分成多个scale(级别),从小到大。将大物体在每个scale 的feature map都进行一次预测,这样大物体在小scale上能很好的预测出来。同时,它也兼顾了在大feature map上去预测小的分类物体。
④ 小物体检测

所以我们在这种小分类的物体上也能有比较好的效果。这是我们内部实验的一个效果,可以看到这些锥形筒,大部分都是能识别出来的。但是,由于YOLO这种方法分类的个数是固定的,并且region也是固定的一个数目,所以在一些小物体上,一些不好分类的类别上,还是很容易出错的,它并不是一个best search的方法。所以,有时候我们还会用一些特定的网络来专门识别这种特定的小物体。
⑤ 样本平衡
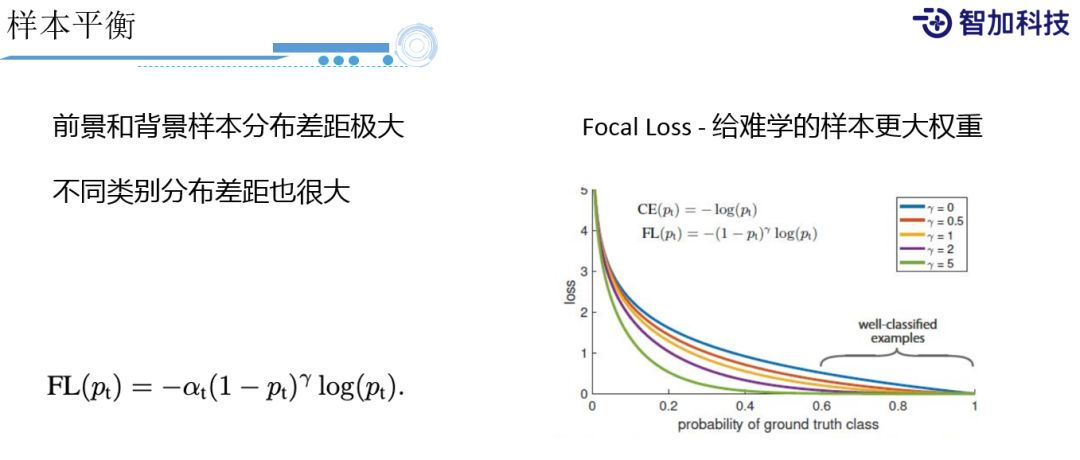
我们还会遇到一个问题,就是样本平衡问题。像刚才Faster RCNN里面,我们会遇到前景物体和背景物体样本分布差别很大,以及不同类别差别也很大。因为我们需要知道高速上行驶的到底是大车、小车,还是摩托车,对于不同类型的车,后续的策略可能是不一样的。由于不同类别差别很大,且天然的在样本上差别就很大,所以很难去平衡他它们。业界通常采用的方法,如Focal Loss会给这种比较难学的样本,增加它的权重,通过α和γ来控制权重比例。另外我们也可以直接计算不同类别的分布,然后用类别的分布当做一个控制Loss的权重。简单来讲,分布比较少的样本权重就会大一点。
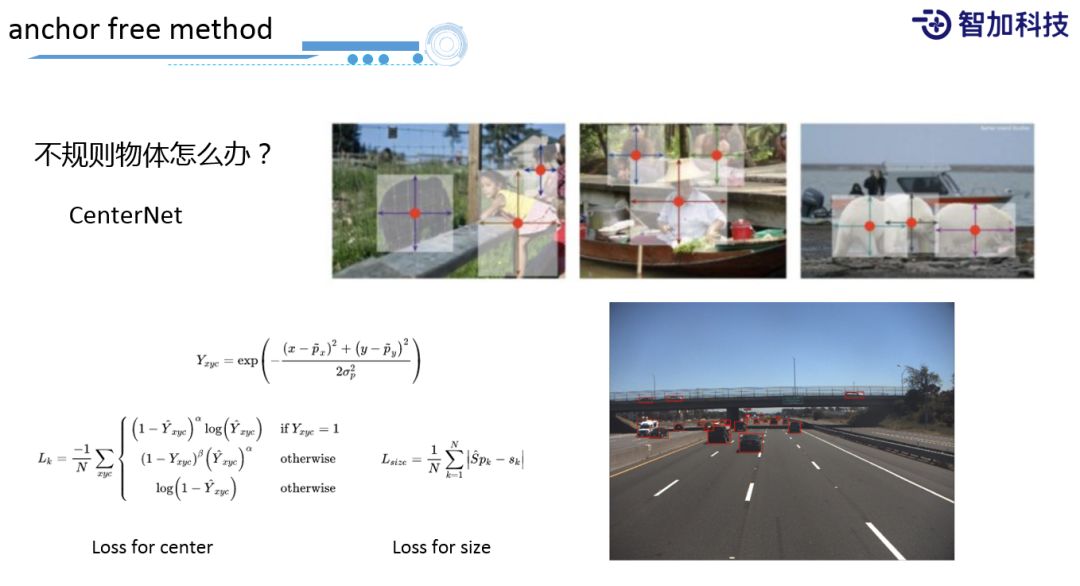
还有一个问题就是遇到这种不规则物体怎么办?比如图片中的小孩,如果用bounding box,整个bounding box之内物体的分布是很不规律的。因此业界提出了anchor free的方法,比如CenterNet,它的想法很简单,只预测每个物体/目标的中心点是什么就可以了。根据中心点和ground truth的中心点,计算它们之间的差距/距离。但是,ground truth中心点会按照高斯分布来分布出一个从中心点特征更明显,到周围比较弱一些的ground truth分布,再去跟预测点计算它的loss。可以看到这个形式其实很像刚才的Focal Loss,只不过这是一个计算点中心形式的Loss Function。同时,还会计算回归的大小,看什么样范围内的物体和ground truth匹配度更高一些。所以,在上图中,对于不规则物体,如桥上横着的货车,这种长条形状,我们也能够识别的很好。
3. Lidar Detection
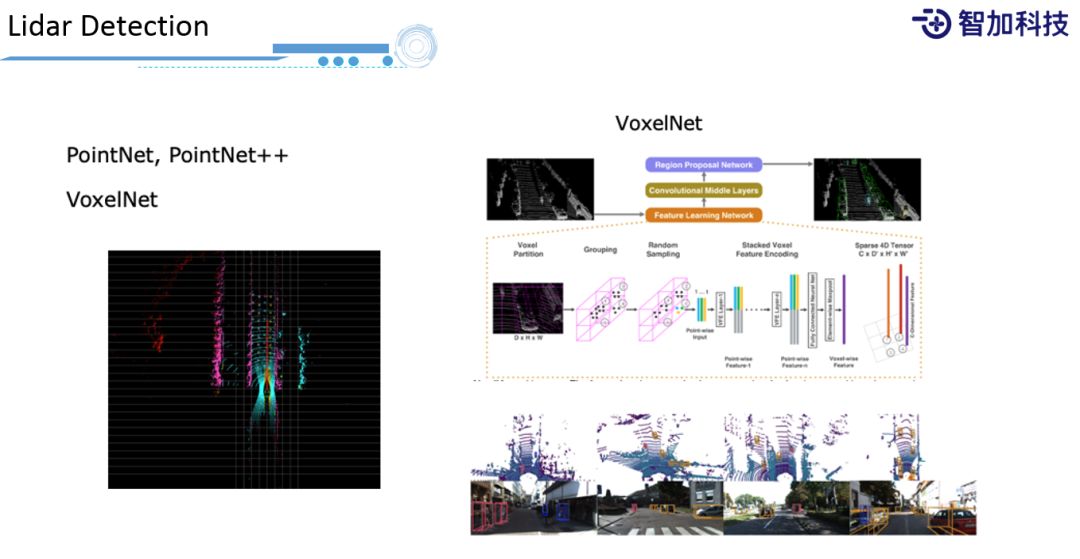
除了自动驾驶的"眼睛"之外,我们在"听觉"方面(如:激光雷达)也有很多的应用。我们会用激光雷达做Object Detection,对于比较流行的方法,我们都会做尝试,比如:PointNet,PointNet++,VoxelNet等。尤其是VoxelNet,它给你的空间做一个3D的划分,划分出若干个Voxel,在这基础上做预测,它在性能和效果上都能达到比较好的折中。
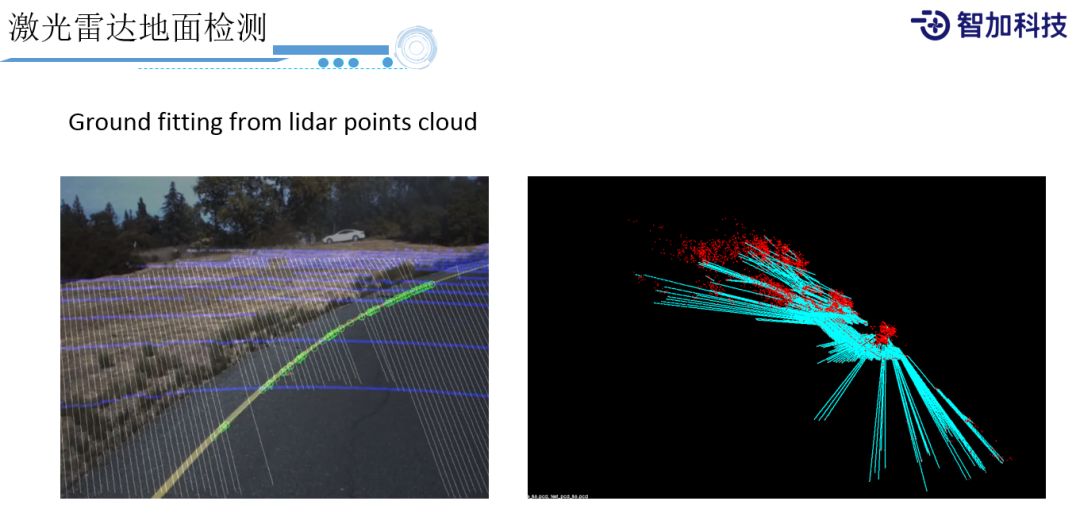
除了物体检测之外,激光雷达还有很重要一点,就是检测地面。因为激光雷达原理是遇到物体就会返回信号,所以信号大部分是地面(ground),当我们拿到地面信号之后就可以(因为它比较有规律)直接用一些传统方法来去做一个fitting,我们就可以fitting出平面,而且不见得是平面,它有可能是个曲面。比如图中这种匝道上的上坡,我们还是比较好的能够fitting出这个ground。地面预测出来之后,我们就能够把它给排除掉,帮助后面的detection做更好的处理。反过来,当地面识别出来之后,我们也可以把Object去掉,通过ground来辅助车道线做一些更好的处理,就能知道车道线的高度和深度是多少。
4. 感知在自动驾驶重卡上的挑战

刚才讲了很多感知技术,在传统自动驾驶上,会用到的一些方法。在我们的重卡自动驾驶中,还会有一些特殊的需求:
车速快。因为我们是在高速路上行驶,所以对我们的检测速度有了更高的要求。
检测距离需要更长。因为车速快,所以需要有更长的时间来防备出现一些危险的情况,这就需要更长的探测距离,保证有足够的时间刹车。
最重要的就是安全第一。这对我们的算法和系统都提了非常高的要求(稳定性、准确性、覆盖率)。

大家可以想像下,我们的机器学习技术可以解决所有问题么?大家可以看到左图是中国的高速,在中国的高速上,我们训练出来的模型,你觉得有可能在美国的高速上直接使用么?这看起来风险还是很大的,对不对?我们可以看到美国的基建跟中国比,还是落后很多的。所以说,这是机器学习的一个痛点,本质上讲它是数据驱动的一个方法,在中国的数据上积累的一些结果,在其它地方直接用还是很难的。所以关键的一点是,我们要学到数据里面的知识,或者它的方法,把这种方法泛化到别的场景上,才能适应各种场景。当然这还需要我们的AI技术走很长的路,在这之前,如果AI不知道怎样学出这种方法,还是需要我们人来教它这种方法,所以在我们系统的实践过程中,还会用一些人工的经验。

再看一些例子,我们要处理的各种corner case:像这种阳光非常强烈,曝光的情况,这也是美国那边的情况;然后是苏州这边,雨天的情况;还有在夜间当有强光或者是光线不足的情况,会有很多corner case。只依赖深度学习,还是很难解决这些长尾问题。

所以,怎么改进稳定性问题?这里有很多环节需要我们去改进,其中一个思路是从单帧过渡到多帧,更多的利用多帧历史上的数据,去提高算法和系统的稳定性。像这样的例子,我们在雨天摄像头都已经沾上雨滴了,已经很难看清前面的路和车,尤其是中间的车道线已经很难看清。但是在这种若隐若无车道线上,如果用多帧,还是能找出一些规律来,所以这也是我们很重要的、依赖的一个方向。
5. 感知技术在量产化道路上的挑战

大家可以现在脑海里想一下,感知技术在量产道路上会遇到哪些挑战?
① 成本
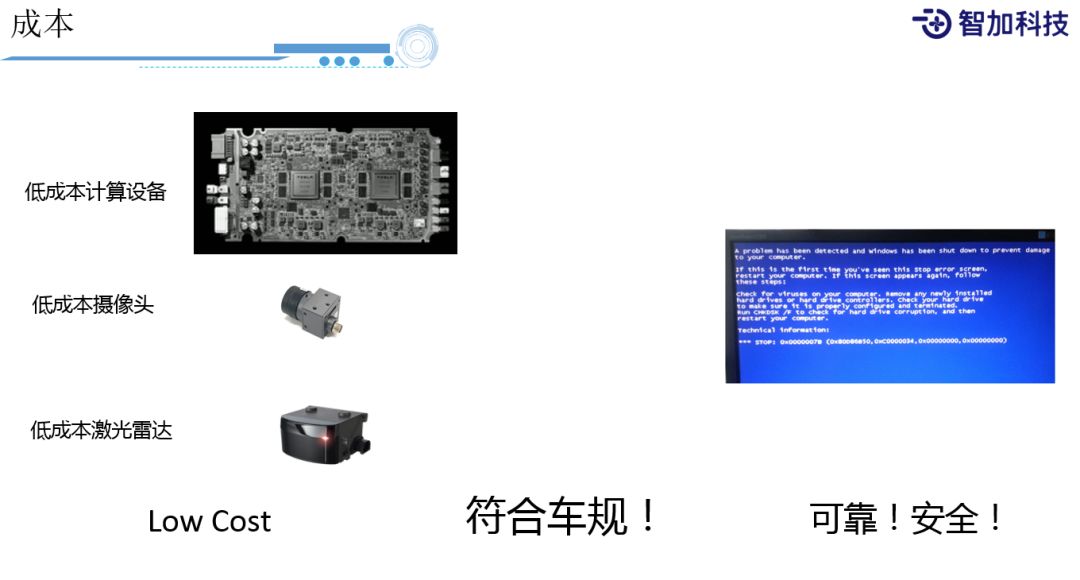
首先第一点是成本,因为我们要量产的话,首先要讲究经济效益,毕竟是做生意,需要尽量在低成本的设备上实现我们的自动驾驶。所以,我们需要选用低成本的计算设备,低成本的摄像头,低成本的激光雷达等等。
一方面是为了经济效益,另一方面也是为了符合车规,大家可以去网上搜一下,知道车规的标准是什么样的,车规会对我们设备的电流、电压、功耗等等有非常严格的要求。
另外一点就是可靠性和安全性。对系统和算法的可靠性要求都是非常高的,尤其是在我们的系统上,不能跑着跑着,突然蓝屏了。所以,一些我们可能觉得很稳定,或者是很常见的操作系统和开源的软件,实际上是没法直接去用的,需要做一些专门的定制。
② 性能
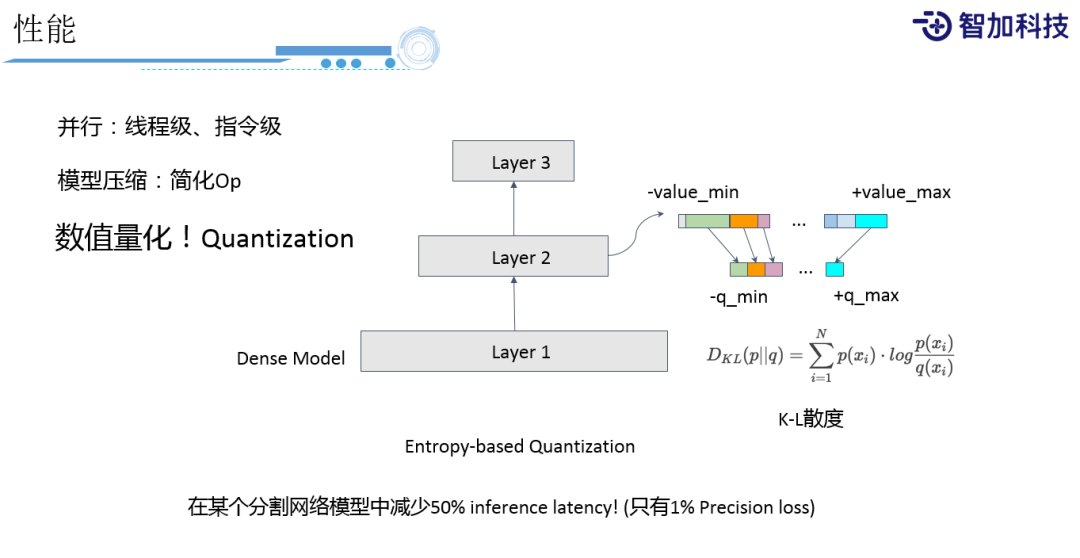
第二就是性能,我们在性能上除了会用一些特定的硬件,去做硬件加速。还包括软件上的一些传统方法,比如并行化这种优化,还有模型压缩的一些方法等等。还有一个很有效的一点,就是做数值量化,这里只是介绍一些我们的经验,因为大家知道我们在处理浮点数据,对GPU和CPU而言,它的性能要求还是非常高的,但实际上从整个数据的分布上来看,也不见得非得用这么高精度来表示数据。所以我们常用的方法就是量化,量化简单来做的话,可以做一个平均的量化,把一个0到100区间的数据,压缩到0到10区间,平均分成十份就可以了,这是最简的方法。但是,如果0到100区间中,这个数据的分布不是平均分布的话,这样做就会存在信息损失。所以我们会用基于Entropy的方法做量化,我们会看哪些数据,比较集中在多个区间上的,还是哪些数据,它在区间上是分布非常少的,这样在不同区间上,我们就可以有不同的在新的空间上的粒度,然后信息的损失,我们可以用K-L散度来计算出在老的区间上和新的区间上,它的熵的一个差值,去min、max差值来算出,这样一个新的区间应该怎样划分。图中是我们在数值量化上的一个应用,在我们的某个分割网络上的实践中,它能够减少50%的inference时间,而且精度上,在我们内部测只有1%精度的损失。这只是系统优化方法中的一点,还有很多环节需要优化。
③ 可靠性
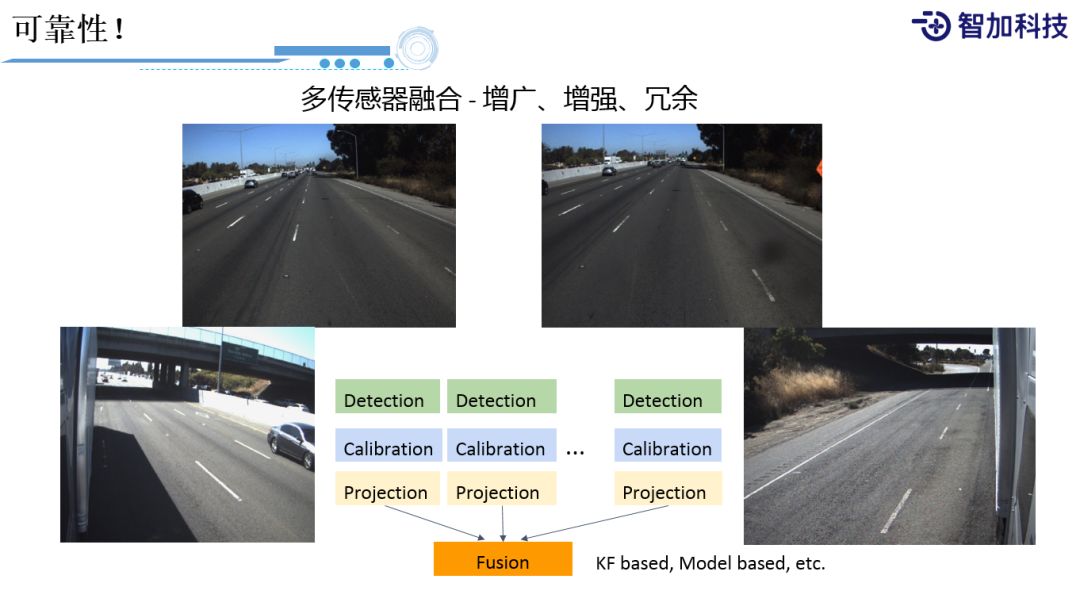
最后一点就是可靠性。刚才前面也介绍过,我们会有多个传感器,多个摄像头来提高它的冗余。有多个传感器之后,我们需要去想怎么把它们一起用起来,所以这里面我们还会有融合这样一个过程。比如,我们在测试车辆上装了前视的双目摄像头,还有后视的双目摄像头,只有当我们把多个传感器的数据映射到同一个空间上,并且把它们做一个融合处理,我们才能真正的把多个传感器的数据用起来。在这里面会有KF based的传统做法,也会有Model based的方法,受限于篇幅,这里就不做过多的展开了。
本次分享就到这里,谢谢大家。
欢迎加入 DataFunTalk 自动驾驶交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:DataFunTalker ),回复:自动驾驶,逃课儿会自动拉你进群。

分享嘉宾
▬

王超
智加科技 | 技术专家
友情推荐:
智加科技多岗位热招中,关注“智加科技AI”,即刻投递简历:

——END——
文章推荐:
一个在看,一段时光!👇



