【重磅】Gym发布 8 年后,迎来第一个完整环境文档,强化学习入门更加简单化!
深度强化学习实验室
OpenAI Gym是一款用于研发和比较强化学习算法的环境工具包,它支持训练智能体(agent)做任何事——从行走到玩Pong或围棋之类的游戏都在范围中。 它与其他的数值计算库兼容,如pytorch、tensorflow 或者theano 库等。现在主要支持的是python 语言
以前官方提供的gym文档主要包含两部分:
测试问题集,每个问题成为环境(environment):可以用于强化学习算法开发,这些环境有共享的接口,允许用户设计通用的算法,例如:Atari、CartPole等。
OpenAI Gym服务: 提供一个站点和api ,允许用户对自己训练的算法进行性能比较。
其中Gym以界面简单、pythonic,并且能够表示一般的 RL 问题,而在强化学习领域非常知名。

Gym发布 8 年后,迎来第一个完整的环境文档:https://www.gymlibrary.ml/
整个文档主要包含以下几部分:
API
Vector API
Spaces
Environments
Environment Creation
Third Party Environment
Wrappers
Tutorials
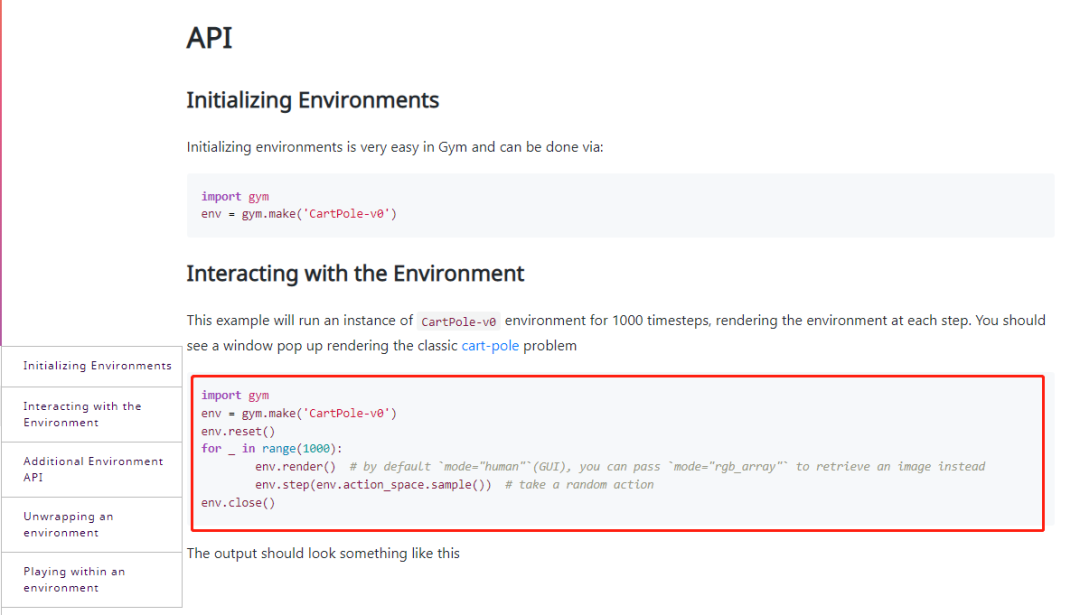
API
此示例将运行 CartPole-v0 环境实例 1000 个时间步,在每一步渲染环境。您应该会看到一个弹出窗口,呈现经典的推车杆问题

Vector API
矢量化环境(Vectorized Environments)是运行多个(独立)子环境的环境,可以按顺序运行,也可以使用多处理并行运行。矢量化环境将一批动作作为输入,并返回一批观察结果。这特别有用,例如,当策略被定义为对一批观察结果进行操作的神经网络时。其中Vector API包含了:

Gym 提供两种类型的矢量化环境:
gym.vector.SyncVectorEnv,其中子环境按顺序执行。
gym.vector.AsyncVectorEnv,其中子环境使用多处理并行执行。这会为每个子环境创建一个进程。
与gym.make 类似,您可以使用gym.vector.make 函数运行已注册环境的矢量化版本。这会运行同一环境的多个副本(默认情况下是并行的)。以下示例并行运行 3 个 CartPole-v1 环境副本,将 3 个二进制动作的向量(每个子环境一个)作为输入,并返回沿第一维堆叠的 3 个观察值数组,数组为每个子环境返回的奖励,以及一个布尔数组,指示每个子环境中的情节是否已经结束。
>>> envs = gym.vector.make("CartPole-v1", num_envs=3)
>>> envs.reset()
>>> actions = np.array([1, 0, 1])
>>> observations, rewards, dones, infos = envs.step(actions)
>>> observations
array([[ 0.00122802, 0.16228443, 0.02521779, -0.23700266],
[ 0.00788269, -0.17490888, 0.03393489, 0.31735462],
[ 0.04918966, 0.19421194, 0.02938497, -0.29495203]],
dtype=float32)
>>> rewards
array([1., 1., 1.])
>>> dones
array([False, False, False])
>>> infos
({}, {}, {})
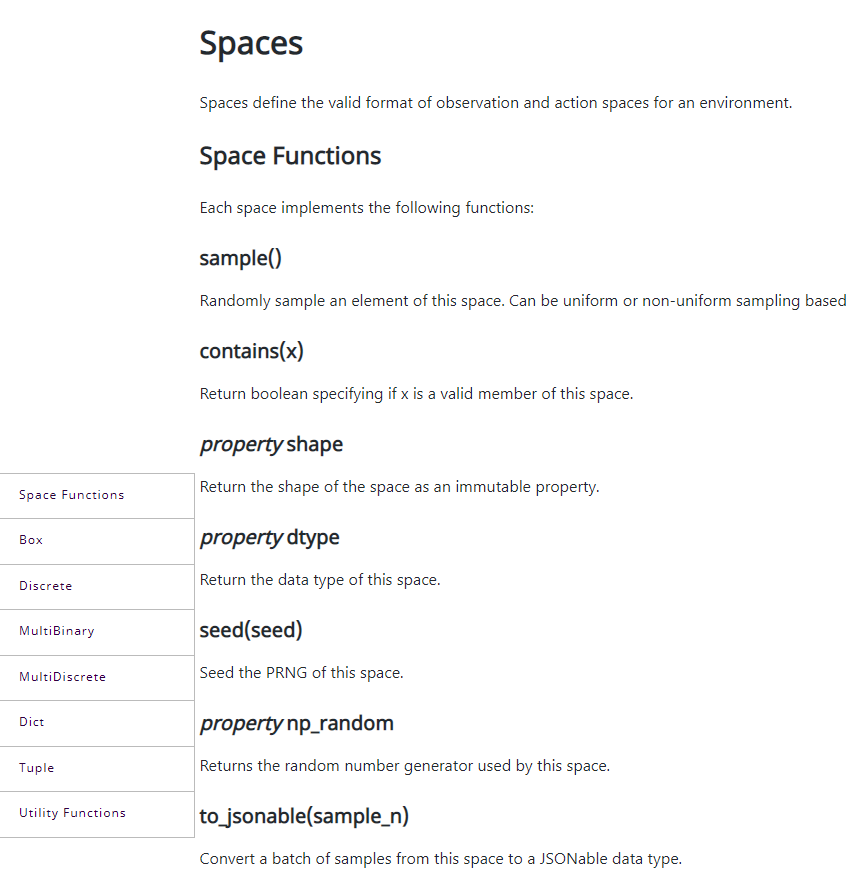
Space
Space主要定义了环境的观察和行动空间的有效格式。包含了Seed函数、Sample等各种各样的函数接口:
Environments
环境部分是Gym的核心内容,其中整体分为以下几大类:
具体的包括如下:
Toy Text
所有玩具文本环境都是由我们使用原生 Python 库(例如 StringIO)创建的。这些环境被设计得非常简单,具有小的离散状态和动作空间,因此易于学习。 因此,它们适用于调试强化学习算法的实现。所有环境都可以通过每个环境文档中指定的参数进行配置。

Atari
Atari 环境通过街机学习环境 (ALE) [1] 进行模拟。
Mujoco
MuJoCo 代表带接触的多关节动力学。它是一个物理引擎,用于促进机器人、生物力学、图形和动画以及其他需要快速准确模拟的领域的研究和开发。
这些环境还需要安装 MuJoCo 引擎。截至 2021 年 10 月,DeepMind 已收购 MuJoCo,并于 2022 年将其开源,对所有人免费开放。可以在他们的网站和 GitHub 存储库中找到有关安装 MuJoCo 引擎的说明。将 MuJoCo 与 OpenAI Gym 一起使用还需要安装框架 mujoco-py,可以在 GitHub 存储库中找到该框架(使用上述命令安装此依赖项)。
有十个 Mujoco 环境:Ant、HalfCheetah、Hopper、Hupper、Humanoid、HumanoidStandup、IvertedDoublePendulum、InvertedPendulum、Reacher、Swimmer 和 Walker。所有这些环境的初始状态都是随机的,为了增加随机性,将高斯噪声添加到固定的初始状态。Gym 中 MuJoCo 环境的状态空间由两个部分组成,它们被展平并连接在一起:身体部位 ('mujoco-py.mjsim.qpos') 或关节的位置及其对应的速度 ('mujoco-py.mjsim. qvel')。通常,状态空间中会省略一些第一个位置元素,因为奖励是根据它们的值计算的,留给算法间接推断这些隐藏值。
此外,在 Gym 环境中,这组环境可以被认为是更难通过策略解决的环境。可以通过更改 XML 文件或调整其类的参数来配置环境。

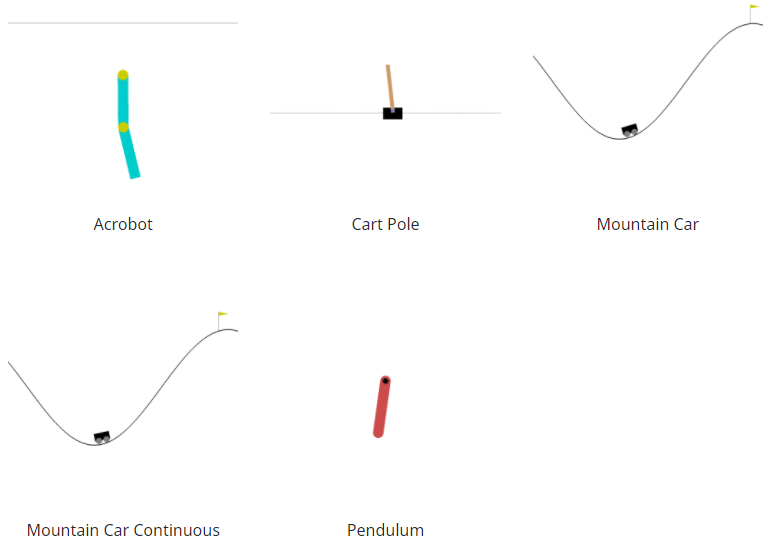
Classic Control
有五种经典控制环境:Acrobot、CartPole、Mountain Car、Continuous Mountain Car 和 Pendulum。所有这些环境在给定范围内的初始状态都是随机的。此外,Acrobot 已将噪声应用于所采取的操作。另外,对于这两种山地车环境,爬山的车都动力不足,所以要爬到山顶需要一些努力。在 Gym 环境中,这组环境可以被认为是更容易通过策略解决的环境。所有环境都可以通过每个环境文档中指定的参数进行高度配置。
Box2D
这些环境都涉及基于物理控制的玩具游戏,使用基于 box2d 的物理和基于 PyGame 的渲染。这些环境是由 Oleg Klimov 在 Gym 早期贡献的,从那时起就成为流行的玩具基准。所有环境都可以通过每个环境文档中指定的参数进行高度配置。
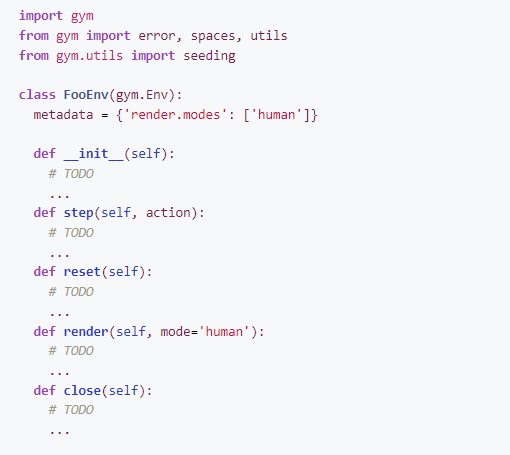
Environment Creation
如何为Gym创造新环境
本文档概述了为创建新环境而设计的 OpenAI Gym 中包含的创建新环境和相关有用的包装器、实用程序和测试。
示例自定义环境
这是包含自定义环境的 Python 包的存储库结构的简单骨架。更完整的例子请参考:https://github.com/openai/gym-soccer。

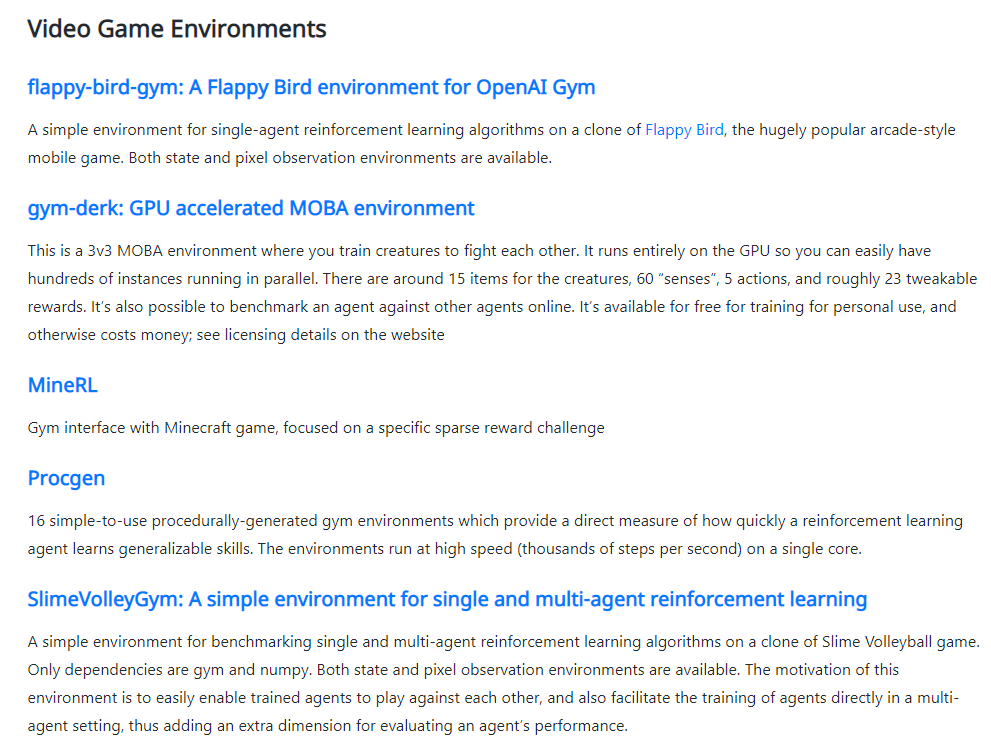
Third Party Environments
第三方环境主要包括了61种:
最后提供了部分入门教程