可定制算法和环境,这个开源强化学习框架火了
强化学习框架怎么选?不如自己定制一个。

提供 20 + 种强化学习算法和多种强化学习环境;
算法和环境可定制;
可以添加新的算法和环境;
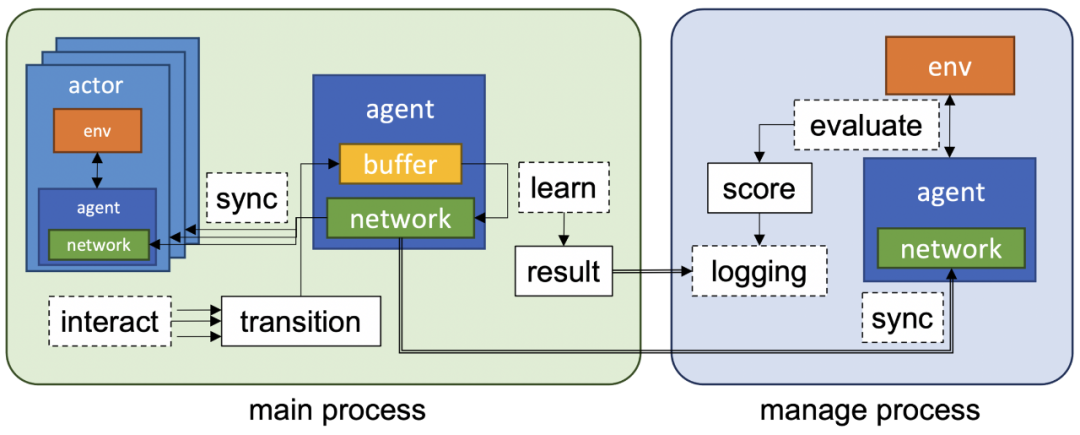
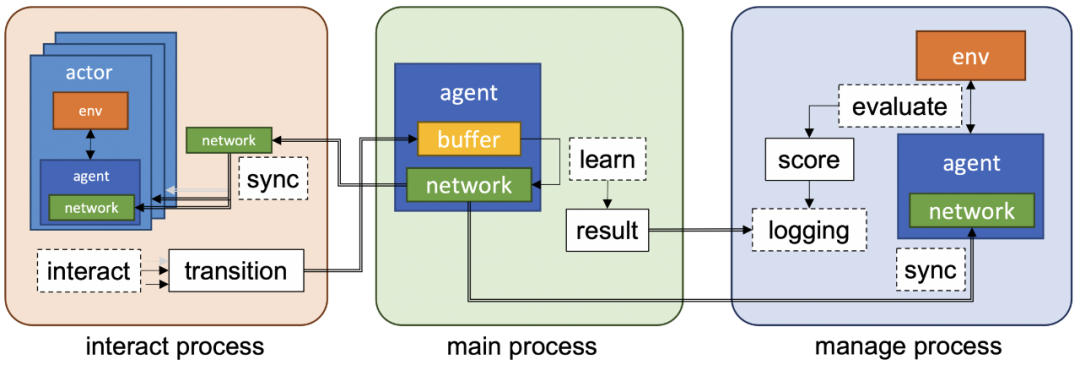
使用 ray 提供分布式 RL 算法;
算法的基准测试是在许多 RL 环境中进行的。


git clone https://github.com/kakaoenterprise/JORLDY.gitcd JORLDYpip install -r requirements.txt# linuxapt-get updateapt-get -y install libgl1-mesa-glx # for opencvapt-get -y install libglib2.0-0 # for opencvapt-get -y install gifsicle # for gif optimize
cd jorldy# Examples: python [script name] --config [config path]python single_train.py --config config.dqn.cartpolepython single_train.py --config config.rainbow.atari --env.name assault# Examples: python [script name] --config [config path] --[optional parameter key] [parameter value]python single_train.py --config config.dqn.cartpole --agent.batch_size 64python sync_distributed_train.py --config config.ppo.cartpole --train.num_workers 8
详解NVIDIA TAO系列分享第2期:
基于Python的口罩检测模块代码解析——快速搭建基于TensorRT和NVIDIA TAO Toolkit的深度学习训练环境
-
NVIDIA TAO Toolkit的独到特性 -
TensorRT 8.0的最新特性 -
利用TAO Toolkit快速训练人脸口罩检测模型 -
利用TensorRT 快速部署人脸口罩检测模型


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容

强化学习(RL)是机器学习的一个领域,与软件代理应如何在环境中采取行动以最大化累积奖励的概念有关。除了监督学习和非监督学习外,强化学习是三种基本的机器学习范式之一。
强化学习与监督学习的不同之处在于,不需要呈现带标签的输入/输出对,也不需要显式纠正次优动作。相反,重点是在探索(未知领域)和利用(当前知识)之间找到平衡。
该环境通常以马尔可夫决策过程(MDP)的形式陈述,因为针对这种情况的许多强化学习算法都使用动态编程技术。经典动态规划方法和强化学习算法之间的主要区别在于,后者不假设MDP的确切数学模型,并且针对无法采用精确方法的大型MDP。

相关VIP内容
相关资讯
相关论文