2019年,这8款自动语音识别方案你应该了解!

从本质上讲,我们通过存储人声与训练自动语音识别系统以发现语音当中的词汇与表达模式。在本文中,我们将一同了解几篇旨在利用机器学习与深度学习技术解决这一难题的重要论文。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
本文作者来自百度研究所的硅谷人工智能实验室。Deep Speech 1 不需要音素字典,而是使用经过优化的 RNN 训练系统,旨在利用多个 GPU 实现性能提升。该模型在 Switchboard 2000 Hub5 数据集上实现 16% 的错误率。之所以使用 GPU,是因为其需要投入数千小时进行模型数据训练。此外,该模型还能够有效应对嘈杂的语音采集环境。
Deep Speech: Scaling up end-to-end speech recognition
https://arxiv.org/abs/1412.5567v2
Deep Speech 的主要构建单元是一套递归神经网络,其已经完成训练,能够摄取语音频谱图并生成英文文本转录结果。RNN 的目的在于将输入序列转换为转录后的字符概率序列。RNN 拥有五层隐藏单元层,前三层为非递归性质。在各个时间步中,这些非递归层分别处理独立数据。第四层为具有两组隐藏单元的双向递归层。其中一组进行正向递归,另一组则为反向递归。在预测完成之后,模型会计算 connectionist temporal classification(CTC)损失函数以衡量预测误差。训练则利用 Nesterov 的加速梯度法完成。
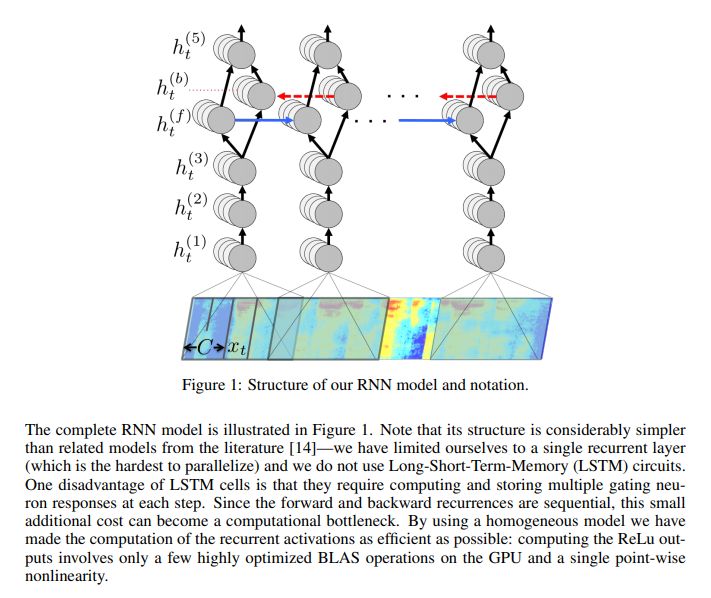
为了减少训练期间的方差,作者们在前馈层当中添加了 5% 到 10% 的弃用率。然而,这并不会影响到递归隐藏激活函数。此外,作者还在系统当中集成了一套 N-gram 语言醋,这是因为 N-gram 模型能够轻松利用大规模未标记文本语料库进行训练。下图所示为 RNN 转录示例:

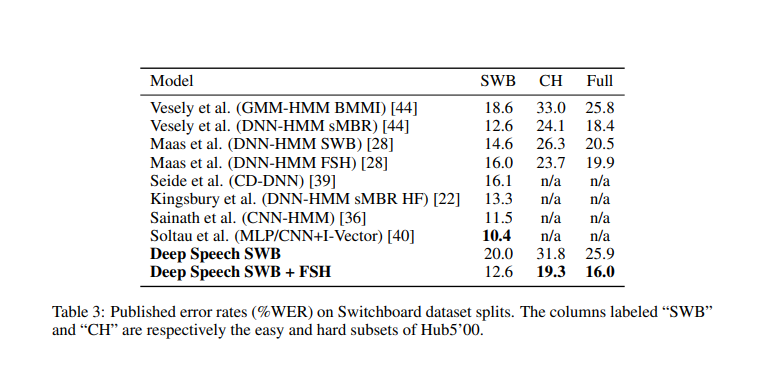
下图为本模型与其它模型的性能比较结果:
在 Deep Speech 的第二次迭代当中,作者利用端到端深度学习方法识别普通话与英语语音。此次提出的模型能够处理不同的语言以及其中的重音,且继续保持对嘈杂环境的适应能力。作者利用高性能计算(HPC)技术实现了 7 倍于上代模型的速度增量。在他们的数据中心内,作者们利用 GPU 实现 Batch Dispatch。
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
https://arxiv.org/abs/1512.02595v1
其英语语音系统利用 11940 个小时的语音音频训练而成,而普通话系统则使用 9400 小时的语音音频训练而成。在训练过程中,作者们利用数据合成来进一步增加数据量。
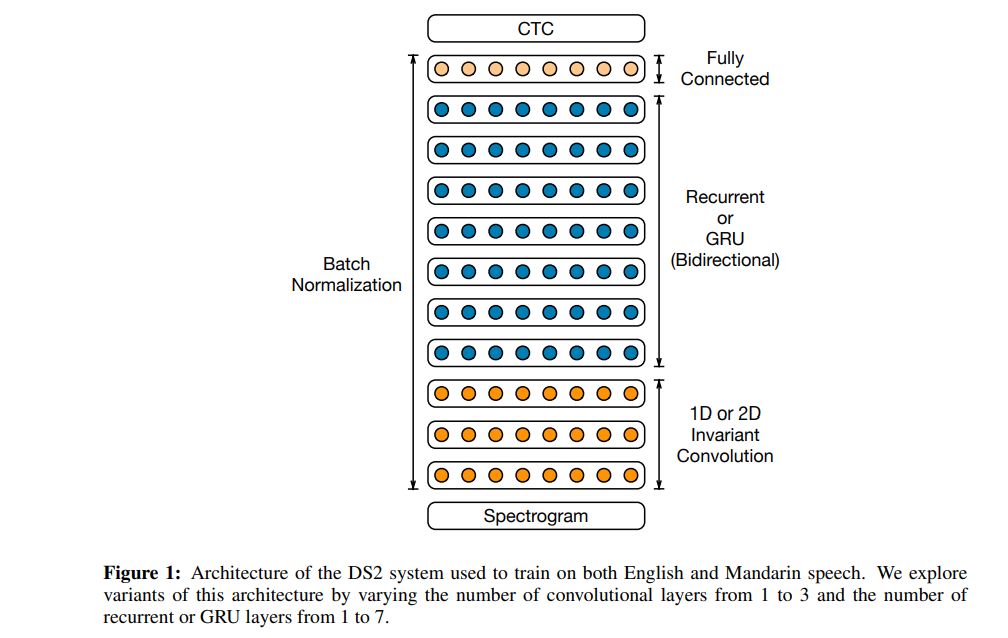
这套模型中使用的架构多达 11 层,由双向递归层与卷积层组成。该模型的计算能力比 Deep Speech 1 快 8 倍。作者利用 Batch Normalization 进行优化。
在激活函数方面,作者们使用了限幅整流线性(ReLU)函数。从本质上讲,这种架构与 Deep Speech 1 类似。该架构是一套经过训练的递归神经网络,用于摄取语音音频谱图与输出文本转录。此外,他们还利用 CTC 损失函数进行模型训练。
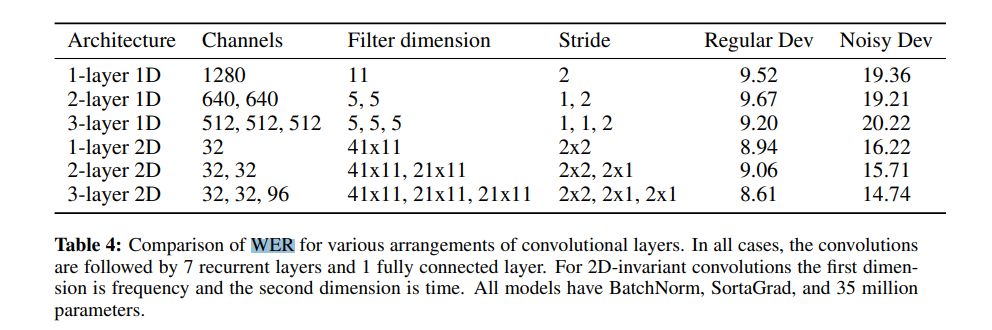
下图所示为各种卷积层排列情况下的单词错误率比较结果。
下图所示为 Deep Speech 1 与 Deep Speech 2 的单词错误率比较结果。Deep Speech 2 的单词错误率明显更低。

作者们使用《华尔街日报》新闻文章组成的两套测试数据集对系统进行了基准测试。该模型在四分之三的情况下实现了优于人类的单词错误率。此外,系统中还使用到 LibriSpeech 语料库。
本篇论文的作者来自斯坦福大学。在本文中,他们提出一种利用主意模型与神经网络执行首过大词汇量语音识别的技术。
First-Pass Large Vocabulary Continuous Speech Recognition using Bi-Directional Recurrent DNNs
https://arxiv.org/abs/1408.2873v2
利用 connectionist temporal classification(CTC)损失函数训练神经网络。CTC 使得作者们得以训练出一套神经网络,并在预测《华尔街日报》LVCSR 语料库中的语言字符序列时,获得低于 10% 的字符错误率(CER)。
他们将 N-gram 语言模型与 CTC 训练而成的神经网络相结合。该模型的架构为反应扩散神经网络(RDNN)。利用整流器非线性的一套修改版本,新系统修剪了大型激活函数以防止其在网络训练期间发生发散。以下为 RDNN 得出的字符错误率结果。
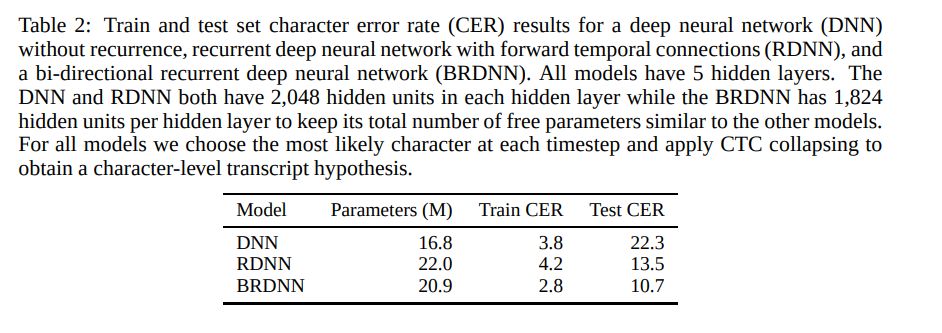
来自 IBM 研究院的作者们希望验证目前的语音识别技术是否已经能够与人类相媲美。他们还在论文中提出了一套声学与语言建模技术。
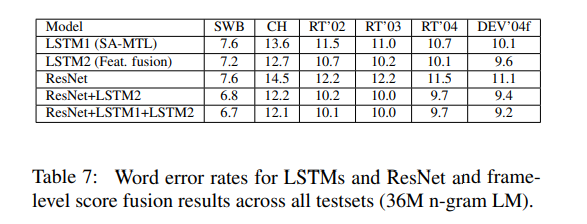
声学侧涉及三大模型:其一为具有多个特征输入的 LSTM,其二为利用说话者对抗性多任务学习训练而成的 LSTM,其三则为具有 25 个卷积层的残差网络。
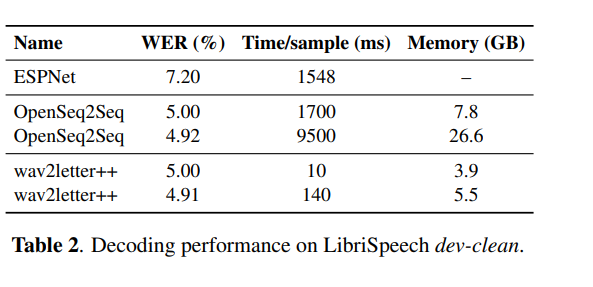
该语言模型利用字符 LSTM 与卷积 WaveNet 式语言模型。作者们的英语会话电话 LVCSR 系统在 Switchboard/CallHome 子集(SWB/CH)上分别获得了 5.5%/10.3% 的单词错误率。
English Conversational Telephone Speech Recognition by Humans and Machines
https://arxiv.org/abs/1703.02136v1
本文使用的架构包括 4 到 6 个双向层,每层 1024 个单;外加一个线性瓶颈层,包含 256 个单元;一个输出层,包含 32000 个单元。训练则涵盖 14 次交叉熵,而后使用强化 MMI(最大互信息)标准进行 1 轮随机梯度下降(SGD)序列训练。
作者们通过添加交叉熵损失函数的扩展梯度来实现平滑效果。LSTM 利用 Torch 配合 CuDNN 5.0 版本后端实现。各模型的交叉熵训练则在单一英伟达 K80 GPU 设备上完成,且每轮 700 M 样本训练周期约为两周。

对于卷积网络声学建模,作者们训练了一套残差网络。下表所示为几种 ResNet 架构及其在测试数据上的实际性能。
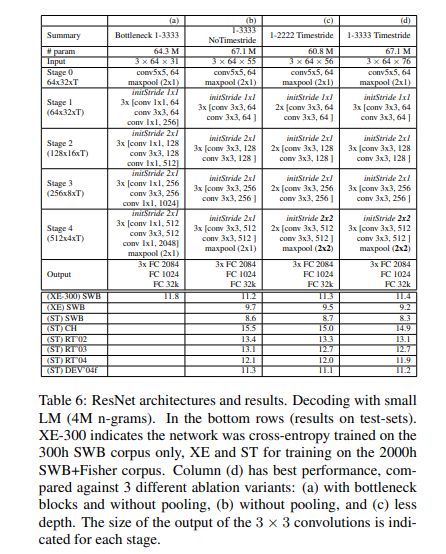
下图所示为残差网络如何适应声学建模。该网络包含 12 个残差单元,30 个权重层以及 6710 万个参数,利用 Nesterov 加速梯度进行训练,学习率为 0.03,动量为 0.99。CNN 同样采用 Torch 配合 cuDNN 5.0 版本后端。交叉熵训练周期为 80 天,涉及 15 亿个样本,采用一块英伟达 K80 GPU,每 GPU 64 个批次。
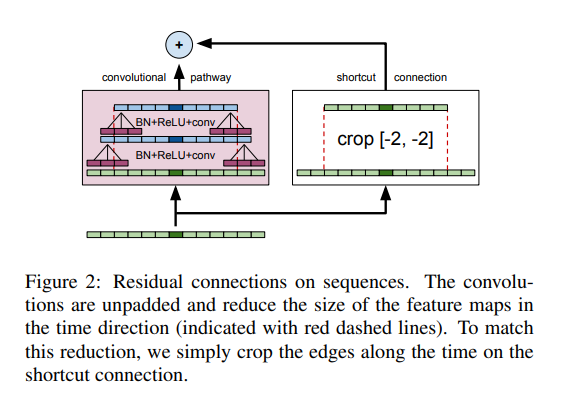
通过下图,可以看到 LSTM 与 ResNets 的错误率:
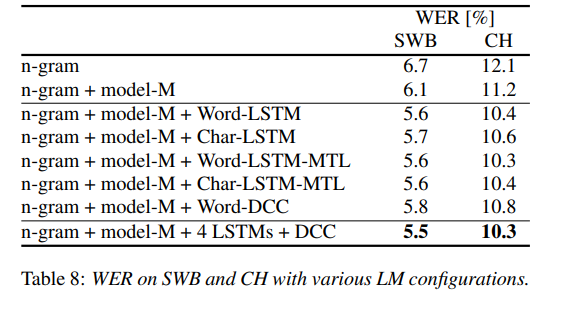
作者们还尝试了四种 LSTM 语言模型,分别为 WordLSTM、Char-LSTM、Word-LSTM-MTL 以及 Char-LSTM-MTL。下图所示为这四种模型的架构。
其中 Word-LSTM 拥有一个字嵌入层,两个 LSTM 层,一个全连接层,以及一个 softmax 层。Char-LSTM 则拥有一个用于通过字符序列估算嵌入的 LSTM 层。Word-LSTM 与 Char-LSTM 都使用交叉熵损失函数来预测下一个单词。顾名思义,Word-LSTM-MTL 与 Char-LSTM-MTL 当中引入了多任务学习(MTL)机制。
WordDCC 由一个单词嵌入层、多个具有扩张的因果卷积层、卷积层、完全连接层、softmax 层以及残差连接共同组成。
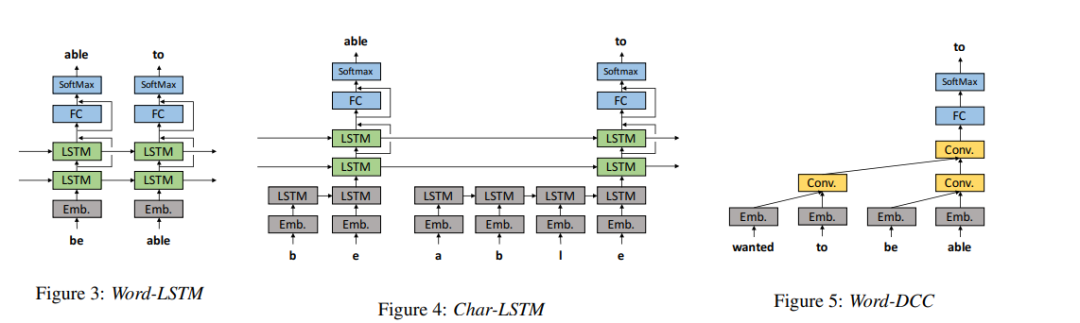
来自 Facebook AI Research 的作者们提出一套开源深度学习语音识别框架——Wav2Letter。该框架由 C++ 编写,并使用 ArraFire 张量库。
wav2letter++: The Fastest Open-source Speech Recognition System
https://arxiv.org/abs/1812.07625v1
之所以使用 ArrayFire 张量库,是因为它能够在多个后端上执行,包括 CUDA GPU 后端与 CPU 后端,从而显著提升执行速度。与其它 C++ 张量库相比,在 ArrayFire 中构建及使用数组也相对更容易。图左所示为如何构建及训练具有二进制交叉熵损失函数的单层 MLP(多层感知器)。
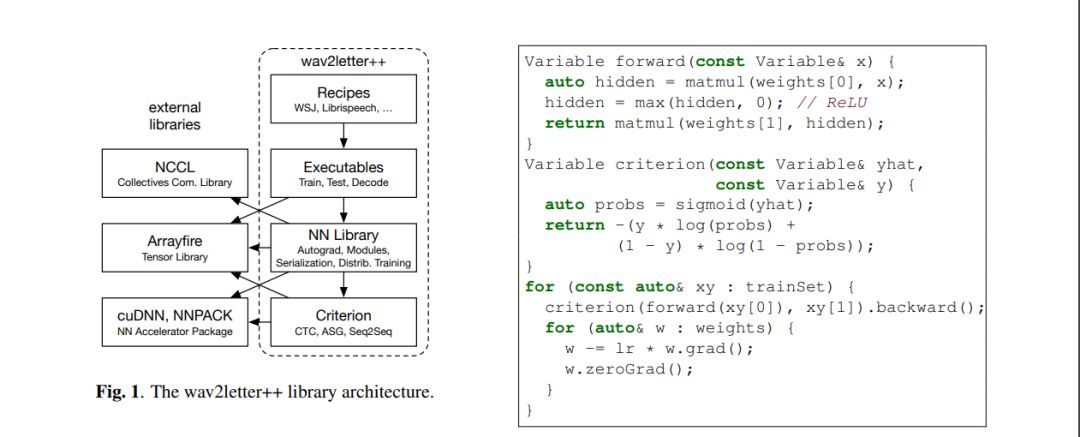
该模型利用《华尔街日报》(WSJ)数据集进行了测试,共使用两种类型的神经网络架构进行训练时间评估:递归,包含 3000 万个参数;纯卷积,包含 1 亿个参数。下图所示为该模型在 LibreSpeech 上的单词错误率。
Google Brain 的作者们预设了一种简单的语音识别数据增强方法,并将其命名为 SpecAugment。该方法能够对输入音频的对数谱图进行操作。
在 LibreSpeech test-other 集中,作者们在无需语言模型的前提下实现了 6.85% 的 WER(单词错误率),而使用语言模型后 WER 进一步改善至 5.8%。对于 Switchboard,该方法在 Switchboard/CallHome 上分别得到 7.2%/14.6% 的单词错误率。
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
https://arxiv.org/abs/1904.08779v2
利用这种方法,作者们得以训练出一套名为 Listen, Attend and Spell (LAS) 的端到端 ASR(自动语音识别)网络。其中使用到的数据增强策略包括 time warping、frequency masking 以及 time masking 等等。

在这套 LAS 网络当中,输入对数谱图被传递至一个双层卷积神经网络(CNN)当中,且步长为 2。该 CNN 的输出则进一步通过具有 d 个堆叠的双向 LSTM 编码器——其中单元大小为 w,用以生成一系列 attention 向量。
各 attention 向量被馈送至一个单元维度为 w 的双层 RNN 解码器中,并由其输出转录标记。作者们利用一套 16 k 的 Word Piece Model 对 LibriSpeech 语料库以前主一套 1 k 的 Word Piece Model 对 Switchboard 进行文本标记化。最终转录结果由集束搜索获取,集束大小为 8。
下图所示为 LAS + SpecAugment 得出的单词错误率性能。
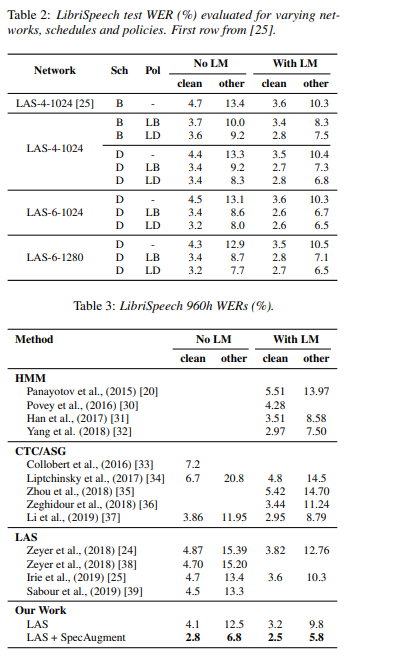
来自 Facebook AI Research 的作者们通过学习原始音频的表达,来探索如何以无监督方式实现语音识别的预训练。由此产生的结果就是 Wav2Vec,一套在大规模未标记音频数据集上训练得出的模型。
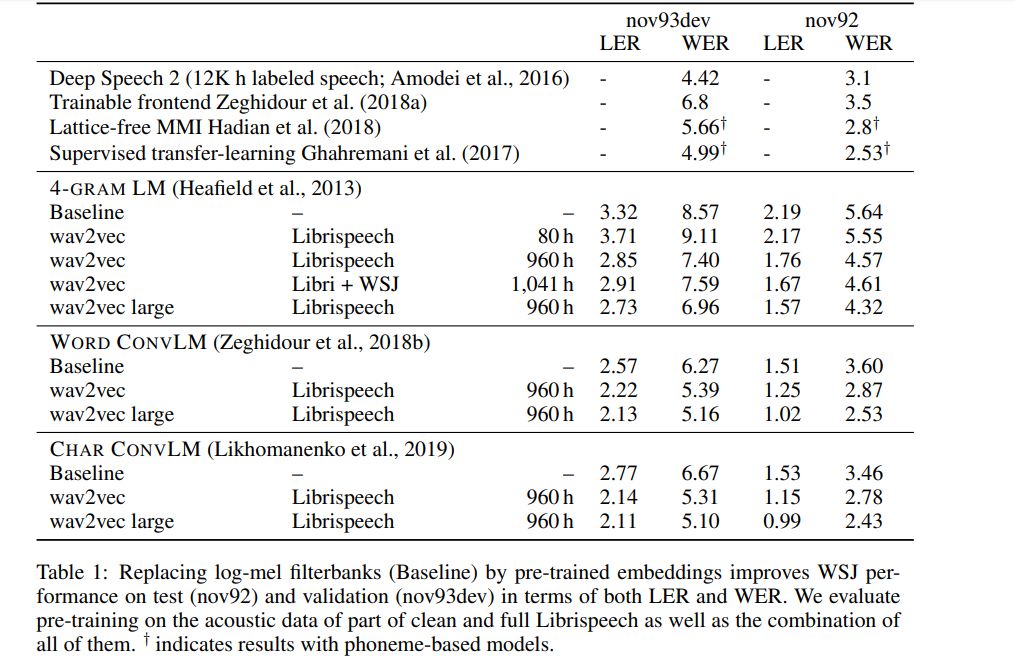
由此获得的表示将用于改进声学模型训练。通过噪声对比二进制分类任务对一套简单的多层卷积神经网络进行预训练及优化,得出的 Wav2Vec 成功在 nov92 测试数据集上达到 2.43% 的 WER。
wav2vec: Unsupervised Pre-training for Speech Recognition
https://arxiv.org/abs/1904.05862v3
预训练中使用的方法,是优化该模型以实现利用单一上下文进行未来样本预测。该模型将原始音频信号作为输入,而后应用编码器网络与上下文网络。
编码器首先将音频信号嵌入潜在空间中,且上下文网络负责组合该编码器的多个时间步,从而得出完成上下文化的表示。接下来,从两套网络当中计算出目标函数。
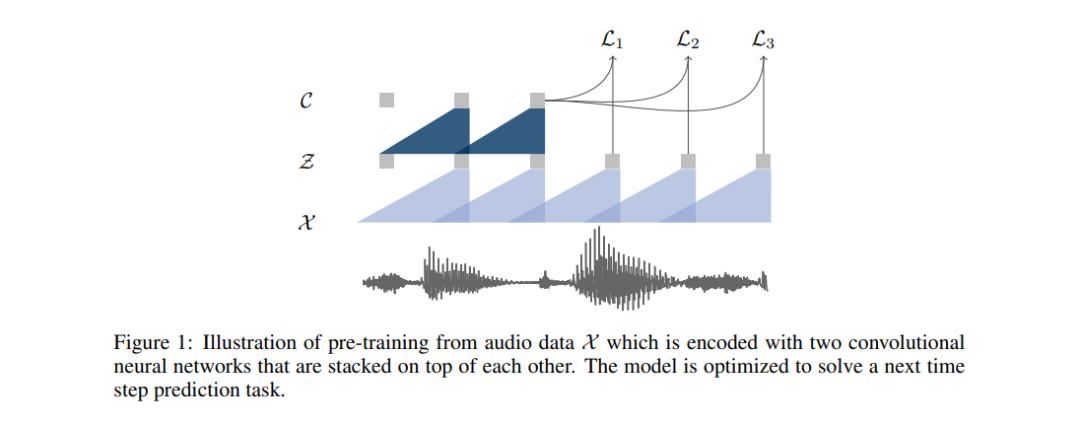
编码器与上下文网络中的各层包括具有 512 个信道的因果卷积层,一个组归一化层以及一项 ReLU 非线性激活函数。在训练期间,由上下文网络生成的表示被馈送至声学模型当中。声学模型的训练与评估利用 wav2letter++ 工具包完成。在解码方面,作者们使用由 WSJ 语言建模数据集上训练得出的字典与单独的语言模型实现。
下图所示,为此模型与其它语音识别模型的单词错误率比较结果。
在本文当中,Amazon Alexa 的作者们为使用大规模 ASR 系统的神经语言模型时出现的一些挑战带来解决方案。
Scalable Multi Corpora Neural Language Models for ASR
https://arxiv.org/abs/1907.01677
作者们试图解决的挑战包括:
在多个异构语料库上训练 NLM
通过将首过模型中的联系人名称等类传递给 NLM,以建立个性化神经语言模型(NLM)
将 NLM 纳入 ASR 系统,同时控制延迟影响
对于立足异构语料库实现学习这项任务,作者们利用随机梯度下降的变种估计神经网络的参数。这种方法要取得成功,要求各小批次必须为学习数据集的独立且相同(iid)样本。通过以相关性为基础从各个语料库中抽取样本以随机构建小批次数据子集,这套系统得以为各个数据源构建 N-gram 模型,并在开发集上对用于相关性权重的线性插值权重进行优化。
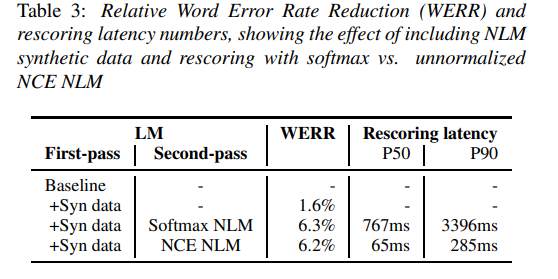
通过从 NLM 上采样大文本语料库并利用该语料库估算 N-gram 模型,这套系统得以构建起 NLM 的 N-gram 近似模式,从而为首过 LM 生成合成数据。另外,作者们利用一套子单词 NLM 生成合成数据,从而确保由此获得的语料库不受限于当前 ASR 系统版本中的词汇储备。模型中使用的书面文本语料库总计包含超过 500 亿个单词。NLM 架构由两个长 - 短期记忆投射递归神经网络(LSTMP)层组成,每个层包含 1024 个隐藏单元,投向至 512 维度。各层之间存在残差连接。
下图所示为该模型给出的一部分结果。其通过从 NLM 生成的合成数据获得了我 1.6% 的相对 WER。

到这里,我们已经回顾了最近一段时间常见于各类环境中的自动语音识别技术。
以上提到的论文 / 摘要当中也包含其代码实现链接,期待大家发布您自己的实际测试结果。
原文链接:
https://heartbeat.fritz.ai/a-2019-guide-for-automatic-speech-recognition-f1e1129a141c

你也「在看」吗?👇




