学界 | 一文概览语音识别中尚未解决的问题
选自Awni
机器之心编译
参与:Nurhachu Null、路雪
深度学习应用到语音识别领域之后,词错率有了显著降低。但是语音识别并未达到人类水平,仍然存在多个亟待解决的问题。本文从口音、噪声、多说话人、语境、部署等多个方面介绍了语音识别中尚未解决的问题。
深度学习被应用在语音识别领域之后,词错率有了显著地降低。然而,尽管你已经读到了很多这类的论文,但是我们仍然没有实现人类水平的语音识别。语音识别器有很多失效的模式。认识到这些问题并且采取措施去解决它们则是语音识别能够取得进步的关键。这是把自动语音识别(ASR)从「在大部分时间对部分人服务」变成「在所有时间对每个人服务」的唯一途径。
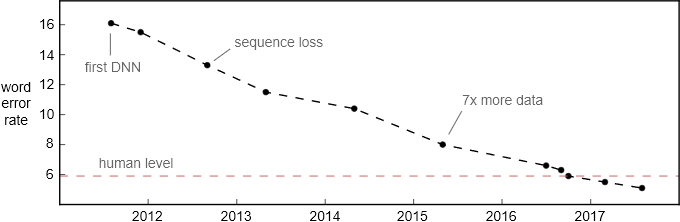
词错率在 Switchboard 对话语音识别基准上的提升。该测试集于 2000 年收集,包括 40 个电话录音,每段对话都发生在随机抽取的两个英语母语者之间。
如果说基于 Switchboard 的对话语音识别结果达到了人类水平,这无异于说自动驾驶在阳光明媚、交通顺畅的小镇上达到了人类的驾驶水平。尽管语音识别在对话语音上的进步很明显。但是认为其达到人类水平的说法终究太宽泛了。以下是语音识别领域仍待提升的一些方面。
口音和噪声
语音识别最明显的一个缺陷在于对口音和背景噪声的处理。最直接的原因就是:绝大多数训练数据都由具有高信噪比的美式英语组成。例如,Switchboard 对话语音训练和测试集都是英语母语者(大部分是美国人)在几乎无噪声的环境中录制的。
但是,更多训练数据本身也没有克服这个问题。很多语言都是有方言和口音的。对每一种情况都收集足够多的标注数据是不可行的。开发一款仅仅针对美式英语的语音识别器就需要 5 千多个小时的转录音频数据!
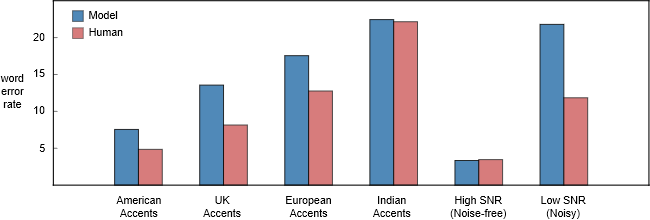
不同类型的语音数据上,百度 Deep Speech 2 模型和人类听写员的词错率对比。我们注意到在非美国口音的语音上,人类听写员表现得要差劲一些。这可能是因为听写员大多数是美国人。我希望在某个区域的本地听写员要有更低的错误率。
至于背景噪声,一辆行驶的汽车内的噪声几乎不可能有-5dB 那么低。人类在这种环境中能够轻易理解彼此所说的话,然而语音识别器的性能则会因为噪声的存在而急剧下降。从上图中我们可以发现,人类和模型的词错率差距在低信噪比和高信噪比音频之间存在巨大的差距。
语义错误
通常,词错率并不是一个语音识别系统的实际目标。我们所关心的是语义错误率,即未正确理解含义的话语片段所占的比例。
举一个例子:如果某人说「let's meet up Tuesday」(周二见),而语音识别器理解成了「let's meet up today」(今天见)。在没有语义错误的情况下也会出现词错率。在这个例子中,如果语音识别器丢掉了「up」,将语音识别成了「let's meet Tuesday」,则这个句子的语义并没有发生改变。
在使用词错率作为标准的时候我们必须谨慎一些。5% 的词错率大约对应每 20 个单词会有一个出错。如果一个句子共有 20 个单词(英文句子平均就是这个长度),那么在这种情况下句错率就是 100%。我们希望出错的单词不会改变句子的意思,否则即使词错率只有 5%,语音识别器也有可能把整句的意思都弄错。
将模型与人类相比较的时候,很重要的一点是要去检查错误的本质,而不是仅仅关注词错率(WER)这个结论性的数字。从我的经验来看,人类转录的时候一般会比识别器较少出错,尤其是严重的语义错误。
微软的研究者最近对比了人类和微软人类级别语音识别器所犯的错误 [3]。他们发现二者的一个差异是:模型比人类更频繁地混淆「uh」(嗯)和「uh huh」(嗯哼)。这两个词组的语义有很大不同:「uh」只是一个语气填充词,而「uh huh」表示附和和认同。人类和模型都犯了不少类似的错误。
单声道、多个说话人
Switchboard 对话语音识别任务比较容易,因为每个说话人都使用独立的麦克风进行录音。在同一段音频流中不存在多个说话人的语音重叠。然而,人类即使在多个说话人同时说话的时候也能够理解说话内容。
一个好的对话语音识别器必须能够根据正在说话的人(音源)来分割音频。它还应该理解多个说话人语音重叠的音频(声源分离)。这应该在无需给每个说话人嘴边安装一个麦克风的情况下实现,这样对话语音识别就能够在任意位置奏效。
域变化
口音和背景噪声只是语音识别器增强鲁棒性以解决的两个问题。这里还有其他一些因素:
变化的声学环境中的回音
硬件的缺陷
音频编解码和压缩的缺陷
采样率
说话人的年龄
大多数人甚至分不清 mp3 文件和 wav 文件的差异。在我们宣称语音识别器的性能达到人类水平之前,它需要对这些问题足够鲁棒。
语境
你会注意到人类水平的错误率在类似于 Switchboard 的基准测试集上实际是很高的。如果在和朋友交谈的时候,他在每 20 个词中误解一个词,那么你是很难与他交流下去的。
其中的原因是,这个测评是在不考虑语境的情况下进行的。在现实生活中,有很多其他的线索帮助我们理解某人在说什么。人类使用但是语音识别器不使用的语境包括:
谈话的历史过程和正在讨论的话题。
人在说话时的视觉线索,例如面部表情和唇部运动。
对谈话对象的了解。
现在,Android 的语音识别器掌握你的通讯录,所以它能够准确地识别你朋友的名字。地图类产品中的语音搜索会使用你的地理定位来缩小你想要导航的位置的范围。
自动语音识别(ASR)系统的准确度确实在这类信号的帮助下得到了提升。但是,这里我们仅对可以使用的语境类型和如何使用又有一个初步了解。
部署与应用
对话语音识别的最新进展都是不可部署的。在思考什么让一个新的语音识别算法变得可部署的时候,衡量其延迟和所需算力是有帮助的。这二者是有关联的,一般情况下,如果一个算法所需要的计算力增加,那么它带来的延迟也会随之增加。但是为了简单起见,我将分开讨论它们。
延迟:我所指的「延迟」指从用户说话结束到转录完成所经历的时间。低延迟是 ASR 中的一个常见产品约束。它能够显著地影响用户体验。ASR 系统中数十毫秒的延迟需求是很常见的。虽然这听起来很极端,但是请别忘记,产生转录结果通常是一系列昂贵计算中的第一步。例如在语音搜索中,实际的网络规模搜索必须在语音识别之后才能进行。
双向循环层是消除延迟的改进中的很好的例子。所有最新的对话语音识别的先进结果都使用了它们。问题在于:在用户结束语音之前,我们不能用第一个双向层计算任何东西。所以延迟会随着话语长度的增加而增加。
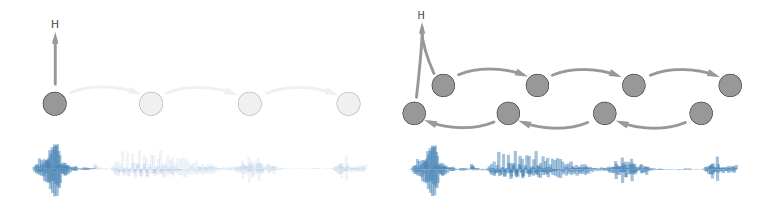
左图:出现前向循环的时候我们可以立即开始转录。
右图:出现双向循环的时候,我们必须等待所有语音都到达之后才能开始转录。
在语音识别中结合未来信息的有效方式仍待研究和发现。
计算:转录一个话语所需的计算力是一种经济约束。我们必须考虑语音识别器准确率提升的性价比。如果一项改进未能满足经济阈值,那么它是无法部署的。
下一个五年
语音识别领域仍然存在不少开放性挑战问题,包括:
将语音识别能力扩展至新的领域、口音,以及远场、低信噪比的语音中。
在语音识别过程中结合更多的语境信息。
音源和声源分离。
语义错误率和新型的语音识别器评价方法
超低延迟和超高效的推理
我期待语音识别未来五年能够在这些方面取得进展。

原文链接:https://awni.github.io/speech-recognition/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




