随着高性能计算 (HPC) 的出现,促使计算生物学成为不断创新和加速成熟的科学学科。近年来,机器学习领域也从 HPC 的实践应用中受益匪浅。
研究人员使用 ORNL 的 Summit 超级计算机以及 Google 的 DeepMind 和乔治亚理工学院开发的工具,以加快准确识别生物体整个基因组中蛋白质结构和功能的速度。该团队最近发布了高性能计算工具包及其在 Summit 上的部署的详细信息。
他们提出了
一种新的 HPC 方案,它结合了各种机器学习方法,用于在全基因组规模上,基于结构对蛋白质进行功能注释。
该方案广泛使用深度学习,并为针对蛋白质组学数据等高通量数据训练高级深度学习模型的最佳实践提供计算见解。
研究人员展示了该方案目前支持的方法,并详细介绍了该方案的未来任务,包括使用 SAdLSA 进行大规模序列比较和使用 AlphaFold2 预测蛋白质三级结构。
该研究以「High-Performance Deep Learning Toolbox for Genome-Scale Prediction of Protein Structure and Function」为题,于 2021 年 11 月 15 日在《2021 IEEE/ACM 高性能计算环境中的机器学习研讨会 (MLHPC)》上发布,于 2021 年 12 月 27 日添加在《IEEE Xplore》。
将遗传密码转化为有意义的功能,
蛋白质是解决这一挑战的关键组成部分。
它们也是解决有关人类、生态系统和地球健康的许多科学问题的核心。
作为细胞的主要构成,蛋白质几乎驱动着生命所必需的每一个过程——从新陈代谢到免疫防御再到细胞之间的交流。
「结构决定功能」是蛋白质研究领域的格言;复杂的 3D 形状指导着它们如何与其他蛋白质相互作用以完成细胞的工作。
基于组成DNA的字母A、C、T和G的长串核苷酸来理解蛋白质的结构和功能,长期以来一直是生命科学的一个瓶颈,因为研究人员需要依靠有根据的猜测和艰苦的实验来验证结构。
「我们现在正在处理天体物理学家处理的大量数据,这一切都是因为基因组测序革命。」ORNL 研究员 Ada Sedova 说, 「我们希望能够使用高性能计算来获取测序数据并提出有用的推论来缩小实验范围。我们想快速回答诸如『这种蛋白质有什么作用,它如何影响细胞?』之类的问题。我们如何利用蛋白质来实现目标,例如制造所需的化学品、药物和可持续燃料,或者设计有助于减轻气候变化影响的生物体?」
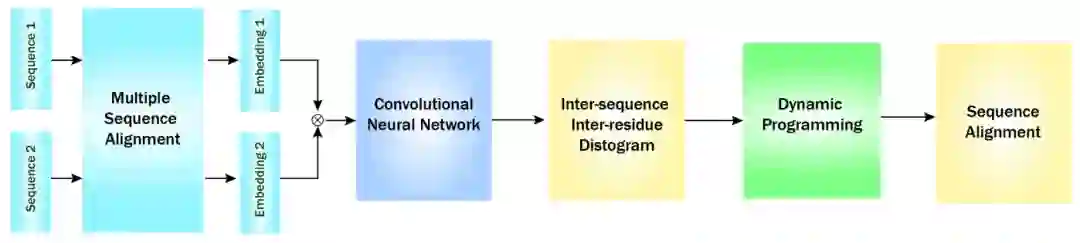
图示:SAdLSA 概述,一种用于蛋白质序列比对的深度学习算法。(来源:论文)
该研究小组专注于对 DOE 任务至关重要的生物。他们对四种微生物的完整蛋白质组(生物体基因组中编码的所有蛋白质)进行了建模,每种微生物大约有 5,000 种蛋白质。已发现其中两种微生物可产生制造塑料的重要材料。另外两种已知会分解和转化金属。结构数据可以为合成生物学的新进展和减少汞等污染物在环境中传播的策略提供信息。
该团队还生成了在泥炭藓中起作用的 24,000 种蛋白质的模型。泥炭藓在泥炭沼泽中储存大量碳方面发挥着关键作用,泥炭沼泽的碳含量比世界上所有森林都多。这些数据可以帮助科学家确定哪些基因在增强泥炭藓吸收碳和抵御气候变化的能力方面最重要。
为了寻找使泥炭藓能够耐受升高的温度的基因,ORNL 科学家首先将其 DNA 序列与模式生物拟南芥进行比较,拟南芥是一种经过彻底研究的芥菜科植物物种。
「泥炭藓与该模型相差约 5.15 亿年。」ORNL Liane B. Russell 研究员 Bryan Piatkowski 说,「即使对于与拟南芥关系更密切的植物,我们也没有很多关于这些蛋白质如何表现的经验证据。通过将核苷酸序列与模型进行比较,我们只能推断出这么多的功能。」
能够看到蛋白质的结构增加了另一层,可以帮助科学家找到最有希望的基因候选进行实验。
例如,Piatkowski 一直在研究从缅因州到佛罗里达州的苔藓种群,目的是确定它们基因中可能适应气候的差异。它有一长串可能调节耐热性的基因。一些基因序列只有一个核苷酸不同,或者在遗传密码的语言中,只有一个字母不同。
「这些蛋白质结构将帮助我们寻找这些核苷酸变化是否会导致蛋白质功能发生变化,如果是,如何改变?这些蛋白质变化最终会帮助植物在极端温度下生存吗?」Piatkowski 说。
寻找序列中的相似性以确定功能只是挑战的一部分。DNA序列被翻译成构成蛋白质的氨基酸。通过进化,一些序列会随着时间的推移而发生突变,将一种氨基酸替换为具有相似特性的另一种氨基酸。这些变化并不总是导致功能上的差异。
直到最近,科学家们还没有能够根据基因序列可靠地预测蛋白质结构的工具。应用这些新的深度学习工具会改变游戏规则。
尽管蛋白质的结构和功能仍需要通过物理实验和 X 射线晶体学等方法来确认,但深度学习正在改变范式,将候选基因的广阔领域迅速缩小到最有趣的少数基因以供进一步研究。
深度学习方案中的一种工具称为结构对齐深度学习中的序列对齐,或 SAdLSA;其训练方式与其他预测蛋白质结构的深度学习模型类似。SAdLSA 能够通过隐含地理解蛋白质结构来比较序列,即使序列只有 10% 的相似性。
「SAdLSA 可以检测可能具有或不具有相同功能的远缘相关蛋白质。」ORNL 计算化学家和小组组长 Jerry Parks 说, 「将其与提供蛋白质 3D 结构模型的 AlphaFold 相结合,您可以分析活性位点以确定哪些氨基酸正在发挥化学作用以及它们如何促成该功能。」
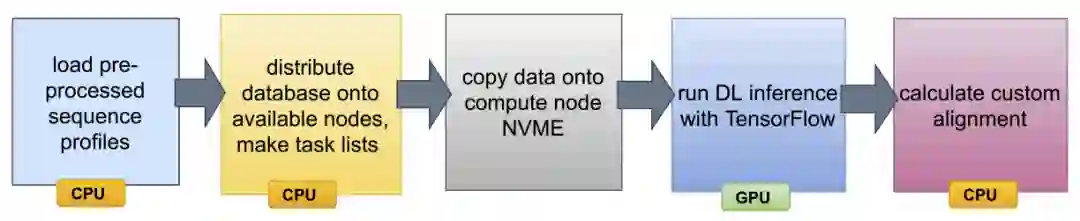
图示:在大规模部署 SAdLSA 的计划。(来源:论文)
研究人员展示了使用基于结构的深度学习方法进行蛋白质功能注释的新 HPC 工具箱。同时,展示了使用基于 SAdLSA DL 的对齐方法大规模部署推理,以及开发利用多个 GPU 的分布式训练方 和Summit 节点,接下来将进一步扩大规模以适应更大的训练数据集。
研究人员还报告了在 Summit 上使用 Singularity 容器和在 PACE 资源上使用原型小型基因组规模测试用例对 AlphaFold 结构预测程序的重组和部署。
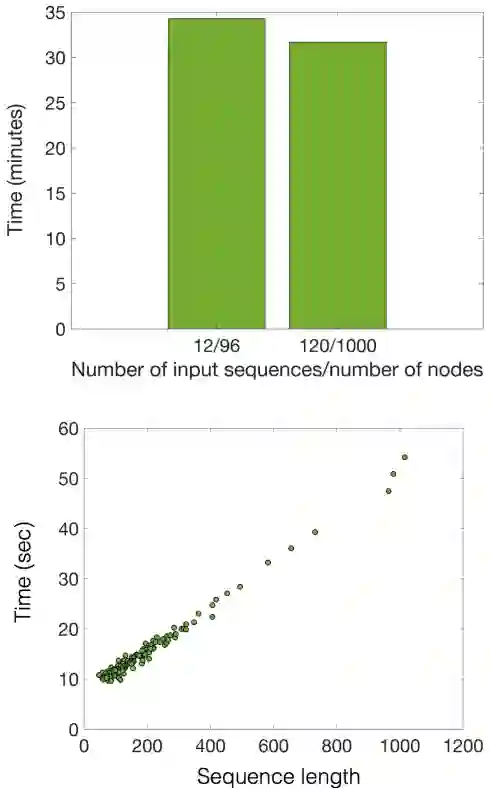
图示:SAdLSA 在 Summit 上的 PDB70 数据库上的性能。(来源:论文)
工具箱包含多种用于基于结构的功能注释的方法,将被用于方案中,为功能未知或低置信度注释的大型蛋白质组生成此类注释,甚至帮助验证已知功能的蛋白质,预测其结构特性,以提供有关这些蛋白质可能参与的催化机制和代谢途径的更详细信息。
在未来的工作中,研究人员希望在工具箱的基础上,支持生物信息学中新出现的任务,包括蛋白质三级和四级结构的大规模预测,以及使用各种工具开发新的方案,以提供高置信度假设,为台架实验提供信息和指导。
论文链接:https://ieeexplore.ieee.org/document/9652872/authors
相关报道:https://phys.org/news/2022-01-scientists-summit-supercomputer-deep-protein.html
人工智能 × [ 生物 神经科学 数学 物理 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。