CVPR2019 | 文本检测算法综述
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文授权转自公众号小石头的码疯窝,请勿二次转载。
作者按:最近工作上比较忙,五一假期回来后到今天只休息了一个周末,知乎上有些回复和私信也没及时回复,望理解.很长时间没来分享东西了,考虑到时间问题(因为一篇篇写,我确实有点来不及写),因此今天在这里简要和大家分享一下CVPR2019关于文本检测的几个工作,如果有感兴趣的朋友,可以多交流.以下也是自己看完文章的个人理解和总结,仅供参考,若有理解错误的地方,也欢迎指正.本文未完,后期还会补充。
CRAFT

论文题目:Character Region Awareness for Text Detection,是NAVER Corp公司发表于2019CVPR
论文链接 :arxiv.org/pdf/1904.01941
代码 :暂未开源
本文的主要思路是先检测单个字符(character region score)及字符间的连接关系(affinity score),然后根据字符间的连接关系确定最终的文本行,简称CRAFT.其网络结构与EAST的网络结构相似:特征提取主干网络部分采用的是VGG-16 with batch normalization;特征decode模块与U-Net相似,也是采用自顶向下的特征聚合方式;网络最终输出两个通道特征图,即region score map和affinity score map,具体的网络结构图如下:
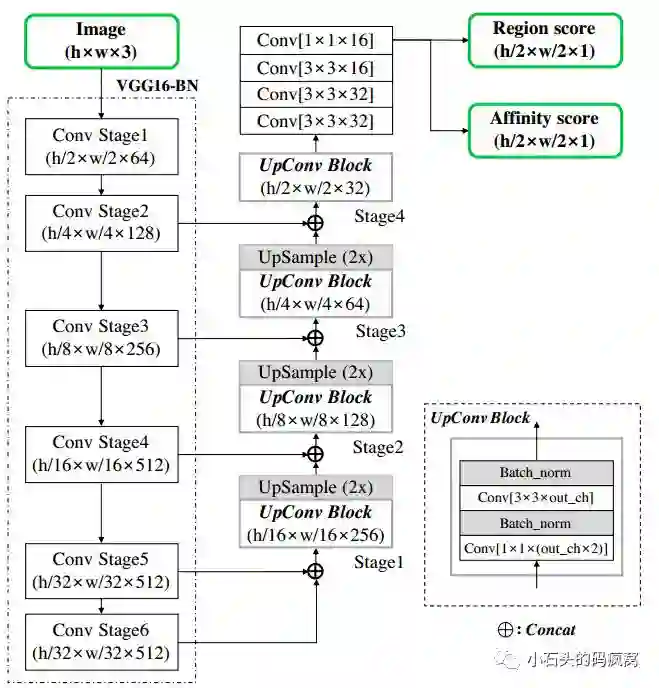
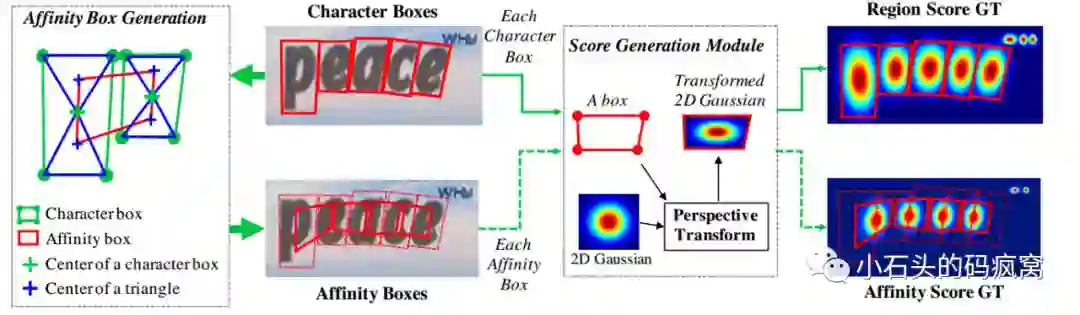
对于训练标签生成,与以往分割图(以二值化的方式离散标记每个像素的label)的生成方式不同,本文采用高斯热度图来生成region score和affinity score。
文中说采用高斯热度图的好处是它能很好地处理没有严格包围的边界区域.对于character region score标签生成,由于对bbox中的每个像素计算高斯分布值比较耗时,本文结合透视变换,采用了近似估计的方法来生成标签,具体步骤如下:
a).准备一个二维的高斯图;
b).计算高斯图区域和每个文字框的透视变换;
c).将高斯图变换到文字框区域。
而对于character affinity score标签生成,先画出每个字符框的对角线;再取每个文本对角线的上下两个三角形的中心点,将紧挨着的两个文本框中的中心点相连,得到affinity score(即下图中的红色框)。这样的标签生成可以使模型在较小感受野的情况下,也可以有效地检测很大很长的文本实例.同时使得模型只关注单个字符与字符间的联系,不需要关注整个文本行。
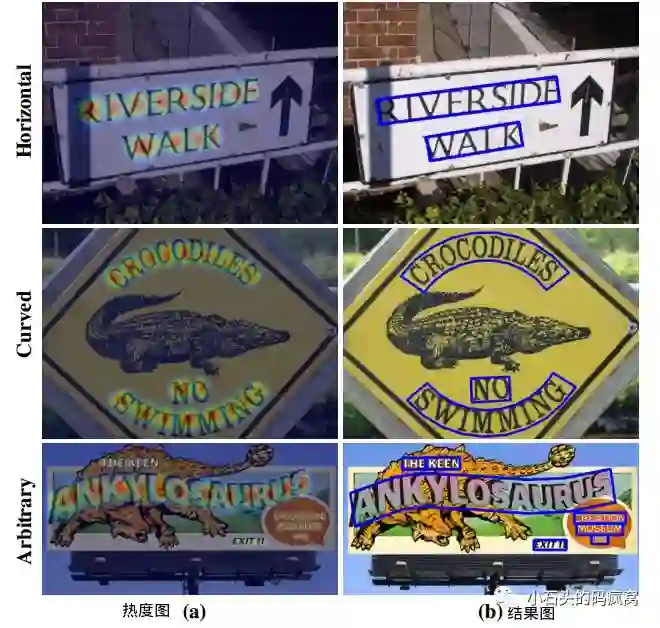
CRAFT可以用于处理任意方向文本、 曲线文本、 畸变文本等.该方法具有如下特性:
1).对尺度变换具有较好地鲁棒性,本文都是基于单尺度图像进行实验的;
2).本文模型不能适用与粘连的语言,如Bangla and Arabic characters;
3).相比于端到端的文本检测方法,该方法在训练的时候也借助了文本长度(因为在训练过程中对于合成样本可以很好地进行单个字符的标注,但是对于现有的文本数据库,其标注方式基本是基于文本行的,所以文中通过借助文本行长度来进行弱监督训练);
4).泛化能力较强
LOMO

论文题目: Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes,是百度和厦门大学共同发表在2019CVPR
论文链接 :arxiv.org/abs/1904.06535
代码 :暂未开源
受限与CNN的感受野的及文本行的表征方式(bbox或四边形),长文本行与曲线文本的检测仍存在极大的挑战.针对此,本文提出了LOMO(Look More Than Once),它由三部分组成:直接回归模块(DR)、迭代修正模块(IRM)、形状表征模块(SEM).首先由直接回归模块产生粗略的四边形表征的候选文本框;接着在提取的特征图上通过迭代修正得到完整的长文本行的四边形表征;最后通过结合文本行区域、文本行中心线及文本行边界偏移得到最终的文本行.具体的框架图如下:
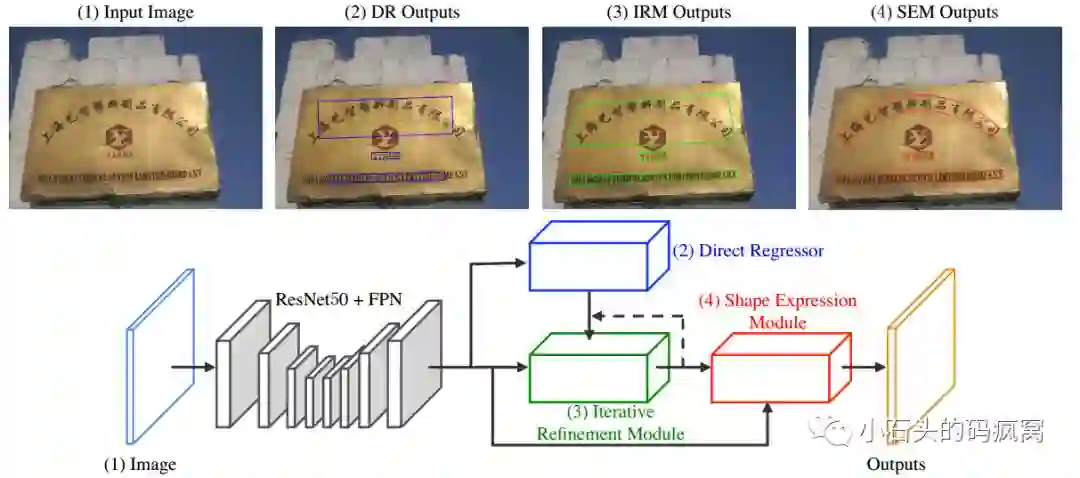
对于直接回归模块,文中参考了EAST,这里就不详细解释了.对于迭代修正模块(IRM),使用了RoI transform层来提取四边形文本行的特征块,之所以没有使用RoI Pooling或RoI Align,是因为:1).RoI transform在提取四边形文本行对应的特征块时,保持宽高比不变;2).在相同感受野的情况下,文本行的四个角点可以为文本行的边界提供更加精确的信息.因此在回归四个角点的时候,本文引入了角点注意力机制.对于形状表征模块(SEM),回归了文本行的三种几何属性:文本行区域、文本行中心线及文本行边界偏移.其中文本行区域是一个二值mask,文字区域用1表示,背景区域用0表示;文本行中心线也是一个二值mask,它是文本行多边形标注的一个向内收缩的版本(具体看EAST);边界偏移是4通道的feature map.
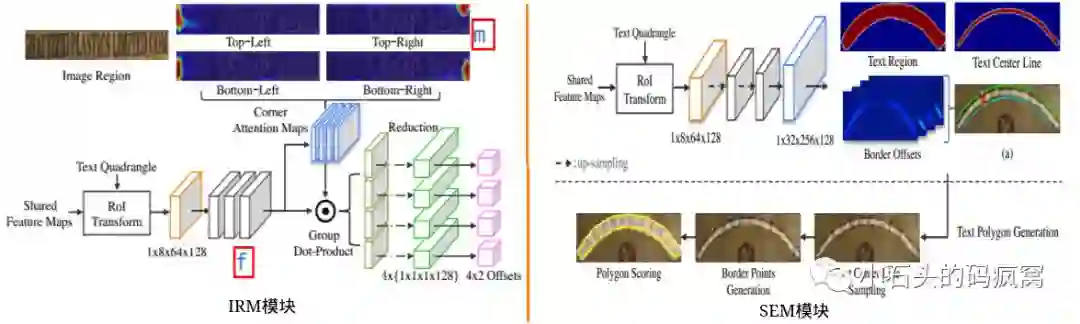
对于文本行多边形生成,具体步骤如下:
1).文本中心线采样.文中采用了n个等间距的方式对文本行中心线进行采样.对于曲线文本(多边形标注的),n=7;对于其它数据集(四边形标注的,如ICDAR2015,ICDAR2017等),n=2;
2).边界点生成.基于已采样的文本中心线,结合相同位置的4个角点的偏移maps,得到文本行的边界点,然后顺时针连接这些角点,就可以得到文本行的完整表征;
3).多边形得分,文中将多边形区域内的文本行响应均值作为最终的文本行得分.

LSAE

论文题目:Learning Shape-Aware Embedding for Scene Text Detection,是香港中文大学和腾讯优图共同发表在2019CVPR
论文链接 :jiaya.me/papers/textdetection_cvpr19.pdf
代码 :暂未开源
本文的主要思想是将文本检测当做一种实例分割,采用了基于分割框架来进行检测.具体的做法是将每个文本行看成一个连通区域,为了更好地区分不同文本实例(即挨的很近的文本或者是很大很长的文本),本文提出了将图像像素映射到嵌入特征空间中,在该空间中,属于同一文本实例的像素会更加接近彼此,反之不同文本实例的像素将会远离彼此。
特征提取主干网络采用的是ResNet-50,接着使用两个对称的特征融合模块(即两个对称的特征金字塔,这里合并的策略与PANet中的自适应特征池化相似),一个用于后续的嵌入分支(Embedding branch),另一个用于后续的分割分支(文本行前景图,包括全文本行前景图和向内收缩后的文本行前景图).通过权重共享,使得两个任务优势互补.网络输出包括嵌入特征图和文本行前景掩膜图,然后经过后处理得到最终的预测文本行总体网络结构如下图:
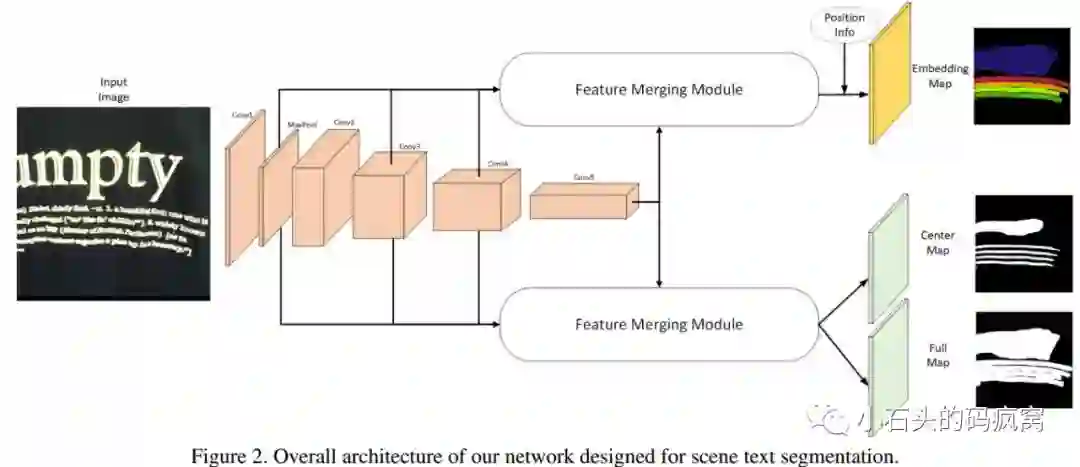
为什么要使用嵌入形状感知?
1).相比与通用的目标检测,文本检测更难根据边界确定两个挨的很近的文本实例;
2).文本行的宽高比变化太大,如从单个文字到整个文本行.
文中针对该分支提出了Shape-Aware Loss损失函数,它包括两部分的损失:方差损失和距离损失,该损失函数用于区分嵌入特征空间中的不同文本实例.具体的计算公式如下:
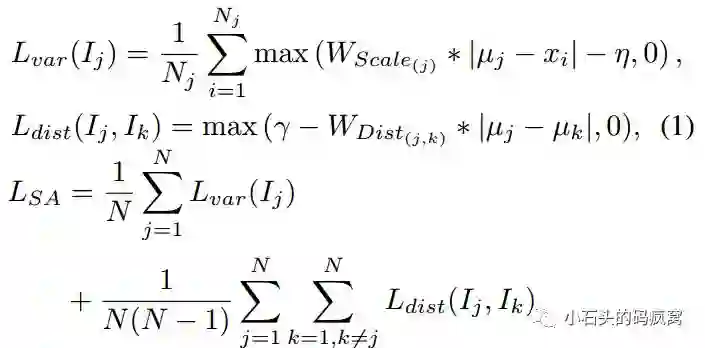
对于最终文本行的构建:论文中通过结合嵌入特征图,Full Map,Center Map三种特征图来进行聚类,得到最终的文本行.具体的聚类步骤如下:首先使用DBSCAN聚类算法得到两个聚类集合:Full Map的和Center Map的;接着对在Full Map内Center Map外的像素进行簇类划分,这里划分的规则是根据嵌入空间中当前像素的嵌入距离到每个簇类平均嵌入距离,若小于指定的阈值,则该像素归于当前簇类;反之,亦然.
接着通过上述递归,得到新的簇类集合,然后对每个簇类集合采用最小外接矩形框最为最终的文本行检测框.为什么不直接在嵌入空间中使用聚类?直接使用嵌入空间进行聚类,并不能很好地区分不同的文本实例.为什么不直接在嵌入空间中使用聚类?直接使用嵌入空间进行聚类,并不能很好地区分不同的文本实例.

PSENet

论文题目:Shape Robust Text Detection with Progressive Scale Expansion Network
论文链接:arxiv.org/abs/1903.12473
代码 :https://github.com/whai362/PSENet
形状鲁棒性文本检测存在以下挑战:
1).现有的文本检测是基于四边形或旋转矩形,很难将任意形状的文本(特别是形状文本)进行包闭操作;
2).大多数基于像素分割的方法不能很好地区分非常邻近的文本实例.
针对上述问题,本论文提出了基于语义分割的单文本实例多预测的方法(简称PSENet),它采用了前向渐进式尺度扩展的方法用来区分邻近的文本实例,可用于检测任意方向的文本.PSENet沿用了特征金字塔网络结构(简称FPN),并在此基础上增加了特征融合和渐进式尺度扩展的方式来实现自然场景中文本行的检测.
具体的步骤如下:
1).先沿用FPN中的网络结构作为特征提取主干网络,提取4个feature maps(低维度和高维度特征连接在一起),分别为;
2).将上述提取的特征进行融合得到F,F中包含了不同感受野的信息,对应融合操作为 

3).将融合后的F送入Conv3-BN-ReLu层(得到256个通道),然后再经过Conv1-Up-Sigmoid层产生n个分支,生成不同的分割结果,分别为S1, S2…. Sn,其中S1表示最小的尺度,并依次递增.每个Si表示在某个特定尺度的所有文本实例的分割掩膜图;4).使用渐进式尺度扩展的方式逐渐扩展S1中每个文本行实例的kernels,直到Sn,得到最终的检测结果.具体的网络结构如下:
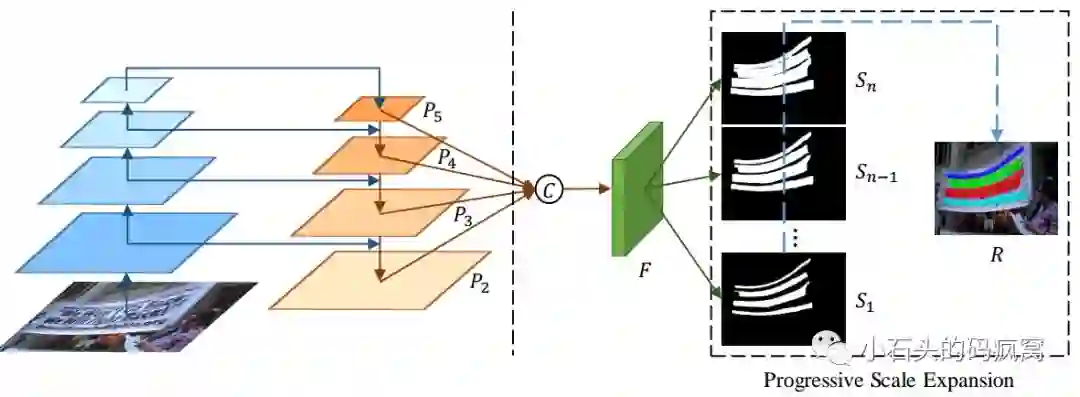
渐进式尺度扩展的具体步骤(该步骤是结合下述示例图来进行阐述的):step1.给定网络的输出集合S1, S2…Sn,对于最小尺度S1,包含4个明显的connected components为C = ( c1, c2, c3, c4 ),用于初始化;通过对当前S1求连通域,并结合对应的源图像,得到不同颜色的文字块(就是论文中说的kernels),这里用不同的颜色表示不同的文本行实例,这样就获得了每个文本行实例的中心部分;step2.通过渐进式尺度扩展方法(文中采用的是广度优先搜索算法)依次合并S2,S3,….Sn,直到网络的输出集合全部合并完毕;step3.提取图像中不同颜色的区域,得到最终的文本行.渐进式尺度扩展的步骤示例图如下:
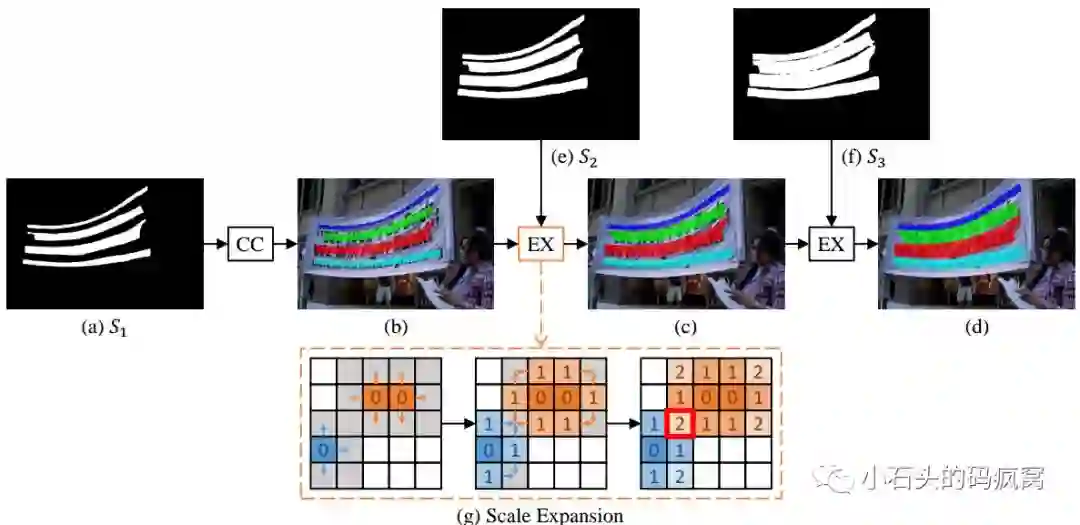
关于训练标签生成,因为PSENet输出的包含了不同尺度的分割结果S1, S2, …Sn,要想生成这些不同”kernels”的分割图就必须生成对训练的ground truths.在实际操作中,可以通过shrinking操作来生成对应的ground truths label.
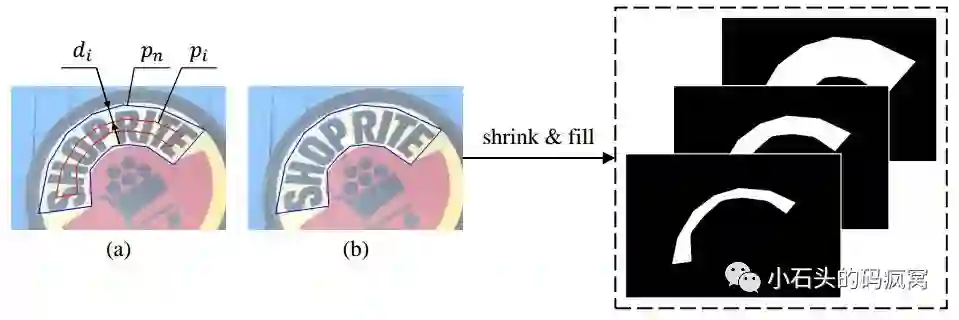
如下图所示:蓝色多边形是原始标注的文本行的ground truths,它对应的是最大的掩膜图.为了生成其它不同的”kernels”,这里通过图像多边形裁剪算法(Vatti clipping algorithm)来每次向内收缩di个像素得到对应收缩后的pi(具体计算公式详见论文).注意这里收缩是在mask操作上进行的,所以所有的ground truths都是二值图像.
检测结果如下:

PMTD(勘误:这篇工作并未发表在CVPR)
论文题目 :Pyramid Mask Text Detector,是商汤和香港中文大学联合发表并与2019.03.28挂在arxiv上,本文的方法在ICDAR2017 MIT数据集上,相比于之前最高的精确率提升了5.83%百分点,达到80.13%;在ICDAR2015数据集上,提升了1.34%个百分点,达到89.33%
论文链接 :arxiv.org/abs/1903.11800
代码 :暂未开源
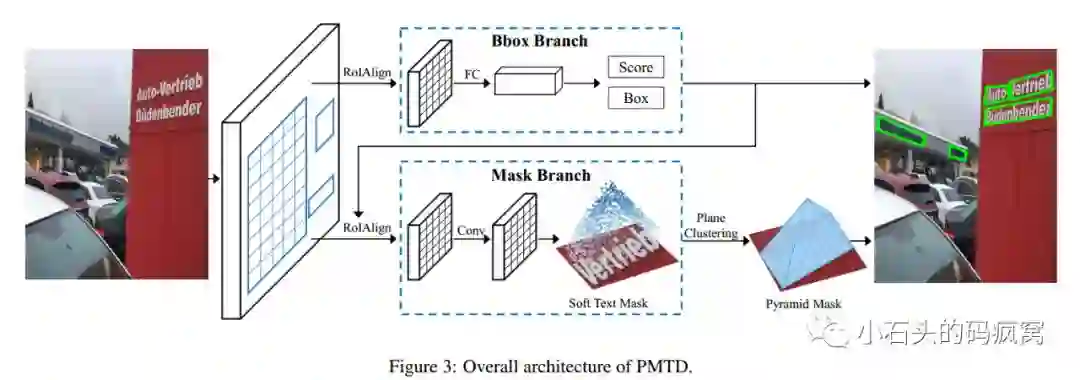
本文提出了Pyramid Mask文本检测器,简称PMTD.它主要做了如下工作:
1)提出了软语义分割的训练数据标签.与现有的基于Mask RCNN方法(文本区域内的像素标签为0或1)不同,本文针对文本区域和背景区域提出了软语义分割(soft semantic segmentation),文本行区域内的像素标签值范围在0-1之间,不同位置的像素标签值是由其当前位置到文本边界框的距离决定的,这样做的好处是可以考虑训练数据的形状和位置信息,同时可以一定程度上缓解文本边界区域的一些背景干扰.
2).提出通过平面聚类的方法构建最终的文本行.通过像素坐标及对应像素点的得分构建3D点集合,然后通过金字塔平面聚类的迭代方法得到最终的文本行.
文中做了两个实验:baseline和PMTD.baseline是基于Mask RCNN的,主干提取特征网络采用的是ResNet50,网络结构采用了FPN.相比原生的Mask RCNN,做了3方面的修改:1)数据增广;2).RPN anchor;3).OHEM.具体的修改细节详见论文.
那么baseline存在什么问题呢?1).没有考虑普通文本一般是四边形,仅按照像素进行分类,丢失了与形状相关的信息;2).将文本行的四边形的标定转换为像素级别的groundtruth会造成groundtruth不准的问题;3).在Mask R-CNN中是先得到检测的框,然后对框内的物体进行分割,如果框的位置不准确,这样会导致分割出来的结果也不会准确.
PMTD是针对baseline中存在的问题提出的改进,主要包括:1).网络结构的改进.PMTD采用了更大的感受野来获取更高的准确率,为了获取更大的感受野,本文通过改变mask分支,将该分支中的前4个卷积层改成步长为2的空洞卷积,因为反卷积操作会带来棋盘效应,所以这里采用双线性采样+卷积层来替换反卷积层;2).对于训练标签生成部分,使用了金字塔标签生成,具体做法是:文本行的中心点为金字塔的顶点(score=1),文本行的边为金字塔的底边,对金字塔的每个面中应该包含哪些像素点采用双线性插值的方法.
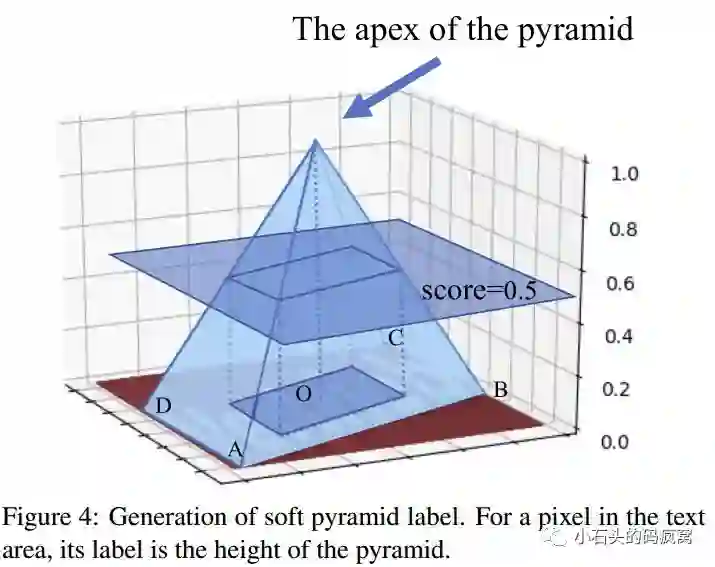
那么如何得到最终的文本行呢?文中使用了平面聚类的方法,用于迭代回归从已学习到的soft text mask寻找最佳的文本行的边界框.在具体操作时,可以看成与金字塔标签生成的反过程.

*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个在看啦~


