哈工大讯飞联合实验室发布可解释性阅读理解评测集ExpMRC
声明:本文转载自 哈工大讯飞联合实验室 公众号

项目地址:http://expmrc.hfl-rc.com/
•••
研究背景
随着大规模预训练语言模型的出现,使得机器阅读理解系统在答题准确率上有了很大幅度的提升。然而,在实际应用中,机器只给出答案是不能够足以信服用户的。因此,这些系统的可解释性研究显得尤为必要。人工智能系统的可解释性涉及方方面面,但主要分为两大类:1)从内部机制上探究模型的运作方式;2)寻求post-hoc解释方法,例如生成文本解释。本文主要聚焦于后者,希望机器阅读理解系统能够给出精准答案的同时给出答案的依据。通常,我们可以借助带有标注证据的机器阅读理解数据来完成这一目标。然而,对于每个机器阅读理解任务去标注新的证据文本代价太大,所以我们进一步希望能够利用现有数据,不进行额外人工标注的情况下完成可解释阅读理解系统的设计。
主要贡献:
我们提出了一个新的可解释性阅读理解评测数据集ExpMRC,用于评测机器阅读理解系统的后验可解释性;
围绕该数据集,我们提出了若干个无监督系统,在不利用额外有标注证据的情况下完成可解释性阅读理解系统的设计与训练;
实验结果表明,目前机器在ExpMRC上相比人类平均水平仍然有较大差距,证明ExpMRC具有一定的挑战性。
基本情况
ExpMRC数据集包含4个子集,并在相应数据的基础上增加了证据标注。
SQuAD:知名的篇章片段抽取型阅读理解数据集(英文)。机器需要从给定的一篇维基百科文章中抽取出问题对应的答案;
CMRC 2018:同样是篇章片段抽取型阅读理解数据集(中文),由哈工大讯飞联合实验室推出;
RACE+:选择型阅读理解数据集(英文)。机器需要从若干个选项中选出问题的答案。需要注意的是,我们采用的并不是原始的RACE数据集,而是使用了内部新标注的选择型阅读理解数据;
C3:同样是选择型阅读理解数据集(中文)。需要注意的是,这里我们只使用了非对话型子集C3(M)。
以下是ExpMRC数据集的样本示例,其中蓝色代表答案,下划线代表证据标注。

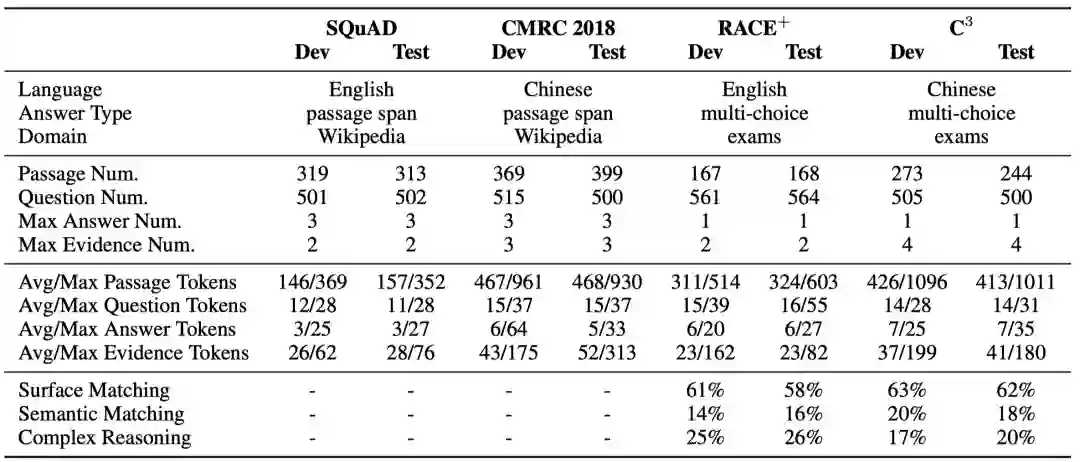
ExpMRC数据集的相关统计信息如下。需要注意的是,ExpMRC并不包含有标注的训练集。这样设计的目的是促使研究人员利用现有的数据(例如SQuAD)来同时完成答案输出和证据输出,而不需要利用额外的有证据标注的训练集。
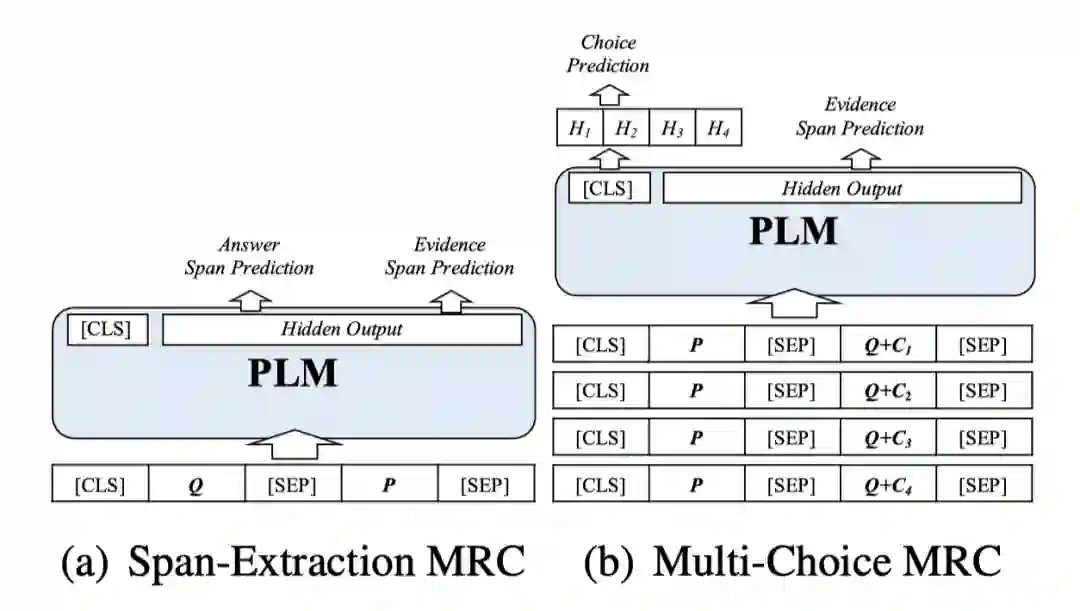
基线系统
我们设计了两组不同的基线系统:非学习类基线系统和机器学习类基线系统。
非学习类基线系统主要是依靠预测出的答案从篇章中抽取出相似片段作为证据。以下我们都是以句子为单位抽取答案。
最相似句子:抽取与答案相似度(F1)最高的句子作为证据。
最相似句子(包含问题):与上面类似,但同时考虑问题文本作为搜索依据。
答案句:对于篇章片段抽取型阅读理解,我们可以直接将预测答案所在的句子抽取出来作为证据。
机器学习类基线系统主要是利用伪训练数据(pseudo-data)训练出一个可以同时生成答案和证据的系统。伪训练数据中的<篇章、问题、(选项)、答案>可以利用对应子集原始的训练集,而证据文本可通过非学习类基线系统获取。
评价方法
ExpMRC提供了三种评价方法,分别对答案、证据以及两者综合进行评价。F1指标用来计算正确答案(证据)和预测答案(证据)之间的重叠程度。
篇章片段抽取型阅读理解:答案F1、证据F1、综合F1
选择型阅读理解:答案准确率、证据F1、综合F1
其中综合F1是答案精度和证据精度的综合考量。
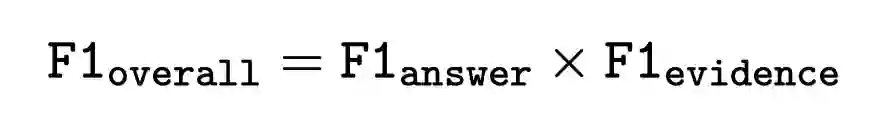
想要在ExpMRC获得更好的效果,系统不仅需要获得较好的答题精度,而且能够同时给出精准的证据文本,为机器阅读理解系统提出了新的挑战。
实验结果
我们使用预训练语言模型作为基底,搭建了ExpMRC的基线系统。
英文:BERT-base / BERT-large-wwm
中文:MacBERT-base / MacBERT-large
实验结果如下所示,其中括号内B表示base级别模型,L表示large级别模型。
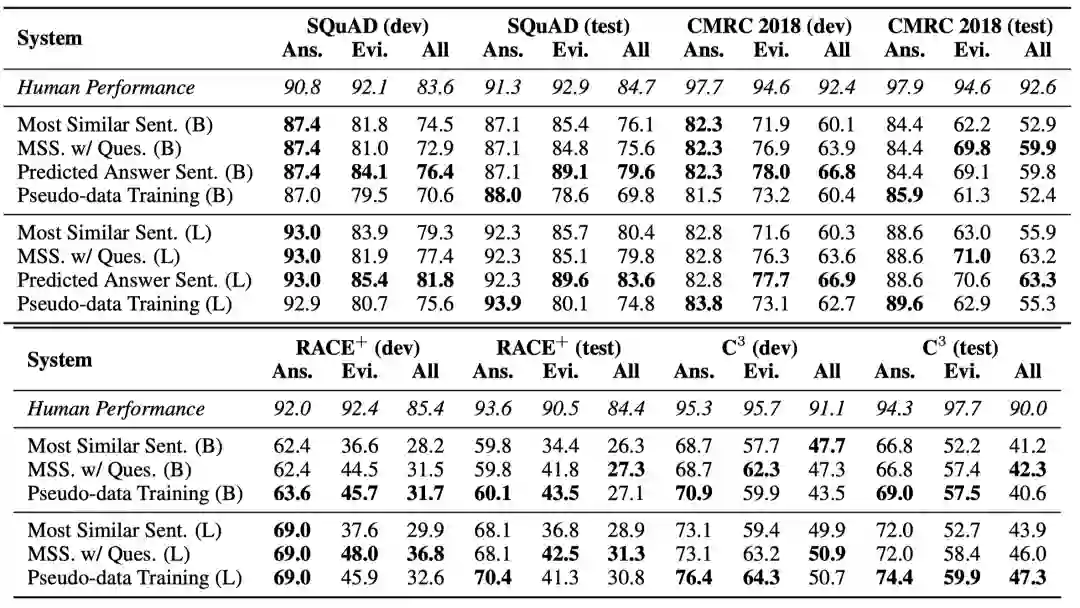
从实验结果可以看到,
对于篇章片段抽取型阅读理解,预训练模型在答案准确率上已经非常接近于人类平均水平,而在证据抽取上还有一定的差距。同时也可以看到,中文CMRC 2018的效果相比于英文SQuAD要低一些,说明不同语种之间在同一任务上存在较大差异。
对于选择型阅读理解,不论是答案准确率还是证据精度都要显著低于篇章片段抽取型阅读理解数据集的效果。说明抽取型阅读理解数据集的难度相对较低,而且证据通常是与答案重叠度比较高的句子或片段。
总的来说,不论是篇章片段抽取型阅读理解还是选择型阅读理解,这些基线系统相比人类水平都有一定的差距,促使研究人员去设计出更好的可解释性阅读理解系统。
提交方法

我们欢迎大家在隐藏的测试集上进行评测。期待有更好的可解释性阅读理解系统突破人类平均水平。
引用文献
Yiming Cui, Ting Liu, Wanxiang Che, Zhigang Chen, Shijin Wang. ExpMRC: Explainability Evaluation for Machine Reading Comprehension[J]. 2022. Heliyon 8, e09290. Cell Press. doi: 10.1016/j.heliyon.2022.e09290
编辑:HFL编辑部

本期责任编辑:刘 铭
哈尔滨工业大学社会计算与信息检索研究中心
理解语言,认知社会
以中文技术,助民族复兴


