哈工大讯飞联合实验室发布少数民族多语言预训练模型CINO
声明:本文转载自 哈工大讯飞联合实验室 公众号
在自然语言处理领域中,预训练语言模型已成为重要的基础技术和资源。在多语言理解相关的研究中,预训练模型的使用也愈加普遍。然而,由于国内少数民族语言语料稀缺、获取难度大等原因,相关技术研究相对匮乏,并且现有的多语言模型无法很好地处理绝大多数国内少数民族语言文字。
为了促进中国少数民族语言信息处理的研究与发展,哈工大讯飞联合实验室(HFL)发布首个面向少数民族语言的多语言预训练模型CINO (Chinese mINOrity pre-trained language model,读音同sino),弥补相关资源的空白。目前相关预训练模型和任务数据已开源,欢迎各位读者下载使用。

https://cino.hfl-rc.com
https://github.com/ymcui/Chinese-Minority-PLM
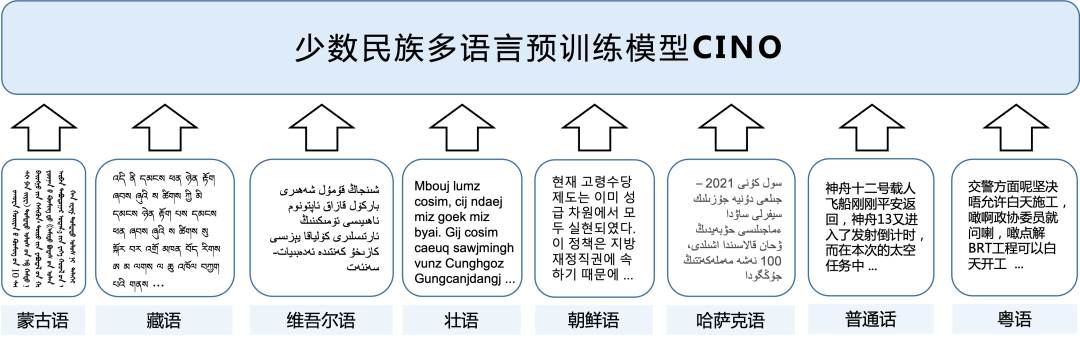
CINO模型简介
CINO基于多语言预训练模型XLM-R开发,在多种少数民族语言语料上进行了二次预训练,提供了藏语、蒙语(回鹘体)、维吾尔语、哈萨克语(阿拉伯体)、朝鲜语、壮语、粤语等少数民族语言与方言的理解能力。
为了便于评价包括CINO在内的各个多语言预训练模型在少数民族语言任务上的性能,我们构建了基于维基百科的少数民族语言分类任务数据集Wiki-Chinese-Minority(WCM)。实验结果表明,CINO在WCM数据集以及其他少数民族语言数据集上获得了最好的效果。
本次推出的CINO模型是large版本(参数量:585M),包含24层Transformer,隐层大小为1024。在未来,我们将推出更多版本的预训练模型以适应不同需求。
性能效果
我们在新构建的WCM多语言分类数据集、KLUE推出的朝鲜语文本分类YNAT、复旦大学推出的藏语文本分类TNCC上验证了模型效果。CINO相比其他基线模型获得了显著的性能提升。
1、Wiki-Chinese-Minority(WCM)多语言分类
我们基于少数民族语言维基百科语料及其分类体系标签,构建了分类任务数据集Wiki-Chinese-Minority(WCM)。该数据集覆盖了蒙古语、藏语、维吾尔语、哈萨克语、朝鲜语、粤语、中文共七种语言和方言,包括艺术、地理、历史、自然、自然科学、人物、技术、教育、经济和健康十个类别。我们在中文训练集上训练,在其他语言上做zero-shot测试,评价指标为macro-F1。
表1 少数民族多语言分类数据集WCM效果

2、朝鲜语文本分类(YNAT)
该任务选用KLUE团队发布的朝鲜语新闻主题分类数据集YNAT。训练集包含45,678条样本,分为7个类别,评价指标为macro-F1。
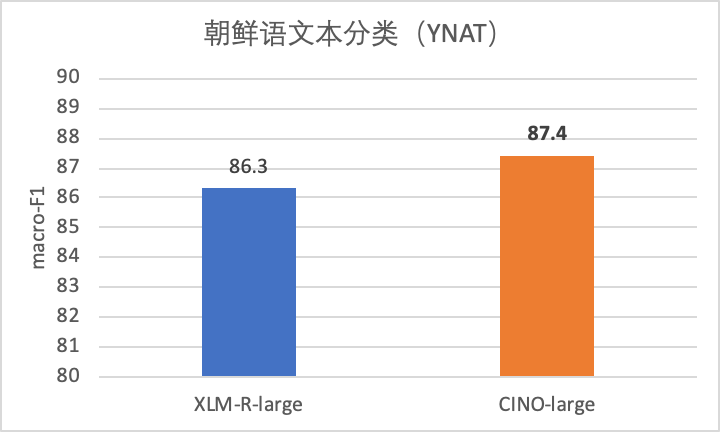
图2 朝鲜语文本分类YNAT效果
3、藏语文本分类(TNCC)
该任务选用由复旦大学自然语言处理实验室发布的藏语新闻数据集Tibetan News Classification Corpus (TNCC)。数据集包含9,203条样本,分为12个类别。我们按8:1:1的比例将其划分为训练、开发、测试集,评价指标为macro-F1。
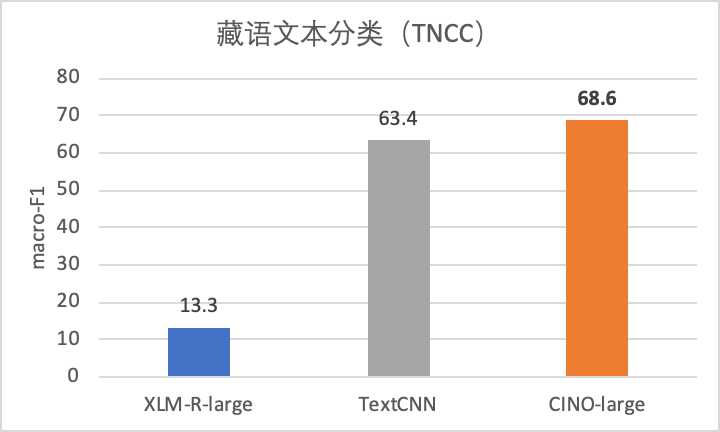
图3 藏语文本分类TNCC效果
快速加载
哈工大讯飞联合实验室发布的所有预训练语言模型均可通过🤗transformers库进行快速加载访问,目前已开源30多个预训练模型。请登录我们的模型库页面获取更多信息。
https://huggingface.co/HFL
未来展望
少数民族语言处理是中文信息处理中不可缺少的一环,也是中文信息处理多样性的一种体现。近年来,从国内外自然语言处理重要会议和期刊来看,关于国内少数民族语言的研究正稳步增多,说明越来越多的研究人员意识到少数民族语言处理的重要意义。
我们希望随着少数民族语言预训练模型CINO的推出,能够进一步促进少数民族语言相关的技术研究,推动少数民族语言相关技术的应用落地。例如,借助CINO的跨语言理解能力,将中文上的NLP能力直接迁移至少数民族语言而无需额外的训练数据,降低了开发成本。另一方面,CINO的多语言理解能力可以比较不同语言的语义,从而使得中文与少数民族语言之间的跨语言检索成为可能。未来我们将进一步优化CINO模型及配套数据和代码,为少数民族语言NLP研究提供更多基础资源。
其他相关资源
中文BERT、RoBERTa:http://bert.hfl-rc.com
中文XLNet:http://xlnet.hfl-rc.com
中文ELECTRA:http://electra.hfl-rc.com
中文MacBERT模型:http://macbert.hfl-rc.com
知识蒸馏工具TextBrewer:http://textbrewer.hfl-rc.com
本期责任编辑:丁 效
理解语言,认知社会
以中文技术,助民族复兴




