【ACL2020-Allen AI】预训练语言模型中的无监督域聚类

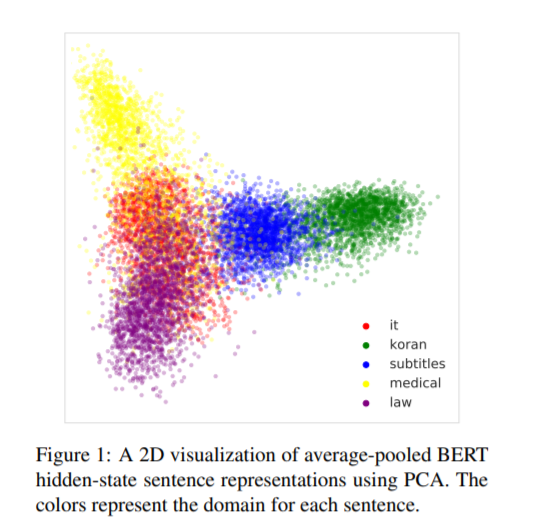
在NLP中,“域内数据”的概念常常过于简单和模糊,因为文本数据在许多细微的语言方面存在差异,比如主题、风格或正式程度。此外,域标签很多时候是不可用的,这使得构建特定于域的系统变得很困难。我们证明了大量的预先训练的语言模型隐式地学习句子表示,这些句子表示在没有监督的情况下由域进行聚类——这表明文本数据中域的简单数据驱动定义。我们利用这一特性,提出了基于这些模型的域数据选择方法,这些方法只需要少量的域内单语数据。我们评估了我们的神经机器翻译的数据选择方法在五个不同的领域,在这些领域中,它们的表现优于现有的方法,包括BLEU和句子选择的精确度以及对oracle的召回率。
https://www.zhuanzhi.ai/paper/5062ad19e073eefacbe9497a201f71d6
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“UDC” 就可以获取《【ACL2020-Allen AI】预训练语言模型中的无监督域聚类》专知下载链接



登录查看更多
相关内容
专知会员服务
99+阅读 · 2020年7月3日
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
专知会员服务
36+阅读 · 2020年4月14日
Arxiv
4+阅读 · 2019年5月6日
Arxiv
3+阅读 · 2018年7月6日


相关VIP内容
专知会员服务
99+阅读 · 2020年7月3日
【ACL2020】不要停止预训练:根据领域和任务自适应调整语言模型,Don't Stop Pretraining: Adapt Language Models to Domains and Tasks
专知会员服务
46+阅读 · 2020年4月25日
专知会员服务
36+阅读 · 2020年4月14日
相关资讯
相关论文
Arxiv
4+阅读 · 2019年5月6日
Arxiv
3+阅读 · 2018年7月6日