![]()
整理 | 晶晶
西周的印纸造文、三国的木牛流马、希腊古城的黄金机器女仆……吴飞的演讲,一下子将人工智能的历史拉到了2000年前……原来用机器替代劳动的想法古已有之,不得不说古代人民如此智慧!
那么智慧的古代劳动人民究竟是如何定义人工智能的呢?我们翻出国学经典,在荀子《正名》中就提出了“知有所合者谓之智、人知在人者谓之能、人有所合者谓之本正”,形象生动地将人工智能的精髓表达了出来。
俗话说,不识庐山真面目,只缘生在此山中。很多时候,我们过多沉溺技术,只是通过五花八门的资讯让头脑装满了人工智能的碎片,却忘了站在高处,更加全面地思考。
吴飞就是站在更高处,从人工智能的学科发展、方法研究以及历史低谷等几个角度出发,把问题剖析得更深刻。
在讲到人工智能的“沉浮历史”时,他旁征博引……从英国人工智能发展的偏激调查,到日本“第五代机器人研发”的功败垂成,再到斯坦福大学+谷歌合作带来的CYC知识系统……我们不禁思考,发展到今天的人工智能,究竟该如何分类、到底该怎样学习……
吴飞强调,无论是规则、数据还是经验,我们并不能判断谁比谁好,谁可以取代谁,其实它们彼此各有优点和不足。举个例子,用规则教,确实和人的思维非常契合,逻辑很强,但我们确实很难把人类所有的规则和理念用来指导或者决策整个过程……
探寻新技术,我们除了了解方法和规则之外,更重要的还要联系实际,现在火热的人机博弈除了给人们带来“AI 改变世界”的兴奋激动以及“AI 比人类更clever”的精神焦虑外,还有什么特殊的意义吗?这不,吴飞又理论联系实践,给我们上了一堂“人机博弈”的大课……
以下为AI科技大本营针对浙江大学计算机学院副院长、人工智能研究所所长吴飞进行的主题为“新一代人工智能的思考与挑战”演讲所做的编辑整理,部分内容稍作删节。
今天,我简单给大家介绍一下人工智能的发展历史,以及从人机博弈的角度看人工智能现在以及即将面临的一些挑战。
一直以来,人类对人类以外的智能都怀有崇高的梦想。
从西周周穆王的印纸造文到三国的木牛流马,再到希腊古城的黄金机器女仆……实际上,这三个都是人类自己幻想出来能够替代人类全部劳动的机械装置。
事实上,自从人工智能在被写入规划的过程中,大家就都想了解中国的人工智能是从什么时候被提出来的。后来发现,原来中国的人工智能早在荀子时代,就已经提出来了。荀子在《正名》中有四句话表述了人工智能的脉络。
![]()
荀子说:“知之在人者谓之知”,这里的知就是咨询的意思。人有视觉、听觉、触觉、味觉和压力这些感知能力,我们会对身体所处的环境进行多通道、多模态的感知。
“知有所合者谓之智”,而感知得到的不同通道的多种类型的大数据,在大脑中形成概念,形成对象,就产生了智慧。这种智慧的来源,是我们人对大数据一种综合的思考得到的一种结果。
“人知在人者谓之能”,这里讲的是人的一些本能。例如,在路上你碰到前面一辆疾驶而来的汽车,你马上就能感知出来并认知出来这是一辆汽车,而且快速向你冲过来,如果你不做避让的话,就可能吾命不久矣。那这个时候人们就会开始趋利避害。人类有一些本能,可以做到对感知或者认知的结果快速地做出处理。
“人有所合者谓之本正”,就可以被理解为是现在我们说的人工智能。就是要把所有从前端感知得到的数据,激发出智慧,再形成与之相关的行动或者决策。这样来看,整个人工智能脉络就已经被清晰得勾勒出来了。
这是我在中国古文中寻找出来的有关人工智能的蛛丝马迹。
再看西方,西方就比较讲究学科层面。
历史上学科层面的人工智能可不是荀子提出来的。
学科历史上,人工智能是由4位学者早1955年提出来的,其中有两位是当时非常年轻的,也就是年龄仅仅31、32岁的学者。一个是时任达特茅斯数学系的助理教师麦卡锡,另一个是时任哈佛大学数学系和神经学系的马文明斯基,他们两位后来都获得了计算机界的最高奖项(图灵奖)。另外两位分别是信息论之父叫香农和IBM第一代通用计算机701的总设计师罗彻斯特。
1955年的8月,四位学者给美国的一个洛克菲勒私人基金会写了一个提案,这个提案中的题目出现了Artificial Intelligence,这也是AI 这个单词在人类学科历史上的首次出现。
建议书中,主要是向美国的洛克菲勒的私人基金申请一笔资金,用于支付十几个人通过一个半月的工作来完成一个研究。这样的一笔开支,希望通过建议书得到洛克菲勒的私人基金会的赞助。很顺利,这个基金会很快批准了这个提案,但是把提建议书上提出的金额有所缩减。
几位科学家说,想做一个AI,这个AI是一台机器,能够像人那样认知、思考和学习,也就是用计算机来模拟人的智能。在这个报道中,他们为了突出难点,列举了7个准备去攻克的难点问题:
1、系统计算机。
2、用程序对计算机进行编程。
3、神经网络。
4、计算的复杂性。
5、自我学习与提高。
6、抽象。
7、随手创造力。
事实上我们可以看到,列举出来的七个问题,后三个问题到现在仍然是人工智能面临的巨大挑战。
举个例子,我们说自我学习与提高,人确实具备这样的能。人类从幼儿园、小学、初中到高中,就已经形成了这个能力。参加高考的时候,很多高考题目并不是之前完全做过的,但是人们可以通过运用自己的一些知识和数据去处理新的问题。
所以我们很难想象,如果有一个机器人,他也和我们的儿子或者女儿一样,手牵手坐在了所谓的幼儿园中的课堂里上课,然后经历了幼儿园、小学、初中、高中的学习过程,又去参加竞赛和比赛……总之很难想象机器可以具备人的自我学习和提升能力。
从1955年提案提出,人工智能就迈上了它的征途,按照当时的提议,人工智能是部分地替代人类的部分劳动。
例如我们制造一个机器,它能够定义和证明取代人类的某个工作;制造一个机器翻译,它能替代人类的翻译家;制造一个专家系统,它能帮人看病、会诊等。那时候的人工智能就是按照这样的思路发展的,也就是试图取代人的一部分工作、劳动。
随着时间的发展,在这个过程中,人工智能逐渐延展出符号阻力、连接阻力和行为阻力这三种仿人,或者仿脑的思路。
接着上面的话题,讲一讲人工智能一直以来延续而生的三种分类。
第一类,语义相关的人工智能
一直以来我们都给这个类别起了一个不太好的名字,叫弱人工智能。这种人工智能指的音符换调、导向,也可以说是它实际执行的任务。
由于机器具有很强的记忆功能和存储能力,它可能在依照葫芦画瓢的过程中,比人类画得更快、更棒,但是它也只能按照葫芦画瓢,并不能创作出精美的山水画。
你提供给它大量的数据,它就可以通过数据进行一定范围内的“创作”。但这种“创作”是具备导向性的,要和既定的领域相关,不能算作是跨域机器的人工智能。
第二类,通用的人工智能或者跨域人工智能
人具有很强的举一反三能力,从一种行为快速地跨越到另外的领域,而不是一味地通过数据驱动或者完成任务导向式地学习。
如果说刚刚提到的第一类任务导向或者说弱人工智能,是数据和规则驱动,那么通用的人工智能,则是掌握“学习”这个能力。
第三类,混合增强的人工智能
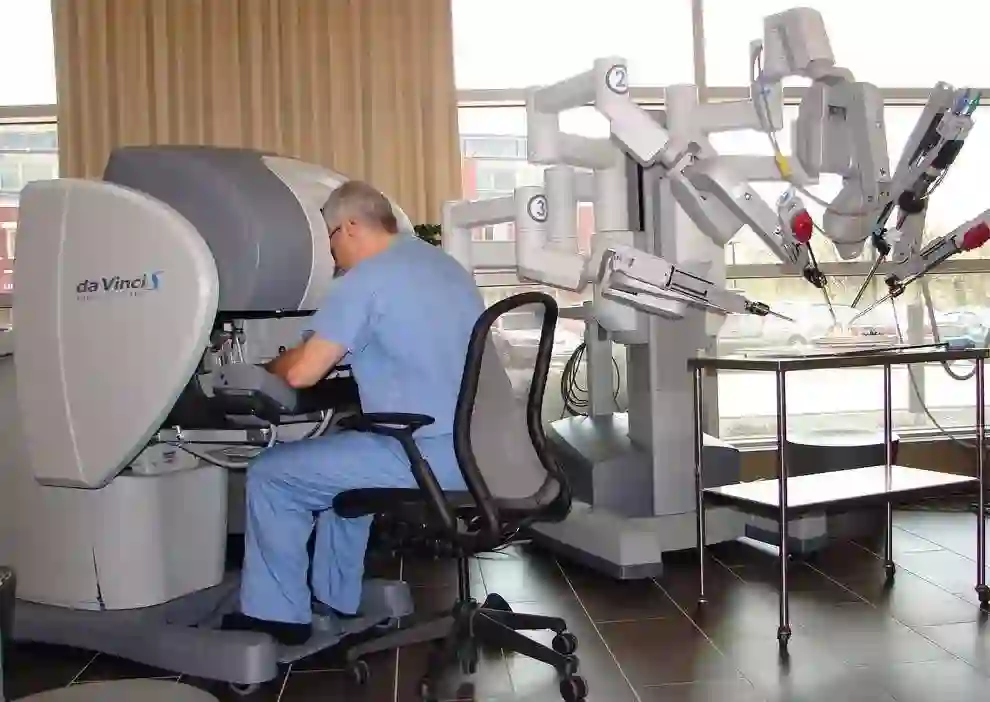
这一类举例的话,例如达芬奇手术机器人。
曾经在互联网流传一段视频,达芬奇手术机器人以灵巧的外科机械臂做到将一个葡萄的皮划开,然后把它缝补好。原理就是,人类的医生坐在机器后面来操纵机器人用灵巧的手臂完成高端、复杂的外科手术。在这个过程中,如果缺少了人类医生或者这种复杂、高端的临床外科手术的机械臂,都不能完成这样一个高难度的任务。
据说,现在的达芬奇手术机器人已经可以做到将一个神经纤维切开,并且把它缝补成功。虽然这项工作是人类医生不能完成的,但必须依靠人类医生来指导完成这件事是确定无疑的。
![]()
我们通常认为,人、机器和互联网的结合就变成了一个更加复杂的智能系统,例如智慧城市。因此,任何一种智能活动将自己的长处与另外一个智能系统的长处进行有机协调,我们就可以在一定程度上让智能的程度增强。但我们一定要强调,在这种增强的智能体中,人永远是智能的开发者,从目前的情况来看,应该不可能产生机器来独立命名的这种情况出现。
尽管如今人工智能发展急剧升温,但在它的发展历史上也经历了三次低谷。
第一次低谷爆发在英国。
1973年在英国,一个皇家科学院院士,原本从事航空动力学,而不是计算机科学,他叫James Lighthill。他做了一件事情,带领一帮人对当时英国的人工智能发展进行了一次全面的评估,然后就把这个评估结果出版了。
他们说英国关于人工智能的研究主要集中在自动机、机器人和神经网络。其中自动机和神经网络的研究虽然有价值,但进展令人失望;机器人的研究是没有价值的,进展也非常令人失望,建议直接取消机器人的研究。
实际上这个结论是比较偏激的,和现在人工智能的现状不符。但这样的一篇报道使得整个英国的人工智能进入了低谷,很多做人工智能研究的专家从此就不敢说自己是做人工智能的了。
第二次低谷发生在日本。
这次变化源于日本的第五代机器人研发,也就是日本想造一个人工大脑,尽管通过10年努力宣告失败,但这项活动为日本积累了一大批半导体、机械和计算机方面的人才。
从这件事情上我们得到的结论是,驱动人工智能的发展,不单单是硬件的极大丰富,其更重要的是内部的数据、知识和软件的有机集成等。因为人的大脑是数以千万、数以亿计的神经原的相联,其中海马体中有非常多的数据和知识来指导我们的推理。
第三次低谷来自知识百科。
传统的人工智能总是局限在规则和知识的推理中,因此我们希望把所有的知识装入知识库系统,这样就能进行很好的推理,于是我们就开始选择把所有的规则以及理念全装到数据库中。
斯坦福大学就是这么干的!
他们在1984年想把所有的规则和知识装到一个CYC的知识系统中去。经过20多年的努力还是宣告失败了,因为人的很多知识是不确定,或者是有一定界限的。
例如“两个知识”的例子。所有的鸟都会飞,这个结论是正确的,所以被放进去;鸵鸟是鸟,这个结论也是正确的,放进去了,这样看来两个知识一旦同时被放进去后,就会顺理成章地推导出鸵鸟会飞,但是这样的结论明显是错误的。
因为“所有的鸟都会飞”这句话本身就是不够精确的,如果我们就为了说明这一概念,那又该怎么去阐释它?我想必须要说出几万种鸟说,来列举这些鸟不会飞。
现实中,人和人的交流可没那么麻烦,因为人具备一些常识性的知识,可以快速地进行一些不精确的表达,但这些表达可以完成常规的知识传递或者交流。
这也说明了,想把所有的知识通过手工工作的形式装在一个推理的知识库中,这是一个非常不可取的任务。
例如,如今我们要了解一个新概念的时候,我们可能会经常访问百度百科怎么说,维基百科怎么说,知乎上又是怎么说的,但是我们并不会去查新华字典怎么说的,十万个为什么上是怎么说的……主要是因为知识在不断地、持续地演化,只有互联网技术所创造出来的“互联网百科”才是非常重要的知识领域群。
说完人工智能的低谷,来讲讲在人工智能历史上,了解和学习人工智能通常采用的三种方法。
第一种,用规则去教
也就是将所有的知识和规则以逻辑的形式编码成功。
例如水利工程是工程的一种,三峡大坝是个水利工程,这样一个程序化的概念体就出来了。为了刻画三峡大坝,我们要说它的功能是什么,它的定位是什么,由于三峡大坝和葛洲坝都位于长江领域,所以彼此之间具有管调节的关系等。
如果我们知道这些知识的话,我们又知道旦布利水畔和达纳斯水畔都位于哥伦比亚这个河域,那我们就可以推理出来它们也具有反调节的关系。给定一些知识,我们基于一个强大的推理引擎,就可以不断地扩充这个知识体系中的概念、属性以及关系,不断地进行知识学习。
IBM的沃森就是很贴切的一个例子。
沃森是一个人机对话的系统,当时有人考了这样一个题目,这个题目是人类选手回答不出来的,请问哪个城市是美国的钢产量和铁产量平均量第一?
沃森通过一定的计算,很快回答出来是匹斯堡,后来从后台的程序发现沃森把美国所有的城市的钢产量和铁产量的数据都从互联网上找到了,要做的就是简单的累加并除二,然后做了一个排序,现在是匹斯堡排在第一位,于是就输出了匹斯堡这个答案。
很难想象,如果人类专家可以回答出这种问题,显然是不可想象的。因为人的大脑不可能记下这么海量的知识,而且这些知识可能与自身无关。通常情况下,很多知识,我们可能在平时要用的时候就去翻翻书,查查互联网就可以了,不会刻意地去记这种庞大的数据知识。
第二种,用数据去学
这个就是现在深度学习的一个大行其道的方法。因为我们很难去刻画一个概念,例如海盗船。你怎么用文字、逻辑去描述这个海盗船?答案是很难去描述。
于是我们就选择很多被标注成海盗船的图片,提供给计算机,让计算机不停地学习,学习之后计算机就会铭记海盗船图像像素点空间分布的模式,进而就学会了海盗船的这种模式。如果你再给它一张图片是海盗船的话,空间分布的模式和之前学习的模式是一样的,于是就可以自动识别为海盗船。
这个就是大数据驱动,在大数据驱动的前提下,要把这个数据标注成它本身明确的语义,或者概念,才能做更好的学习与提高。
关于这方面有几个例子。
例子一,2012年纽约时报发表了一篇文章,题目叫多少台计算可以识别一只猫,答案是16000台。
例子二,特斯拉第一次造成车毁人亡现象。
特斯拉的无人汽车上有非常多的传感器(例如雷达、视觉等)。在风和日丽的环境下,竟然发生了直接撞击相驰火车的事故,大家都觉得不可思议。
事后分析才发现,特斯拉汽车一直向前开的过程中,司机正在看《哈利波特》的VCD,因为眼睛离开了前方,手和脚也都离开了操作的仪器,一辆白色的箱式大货车在它的对象车道行驶时有一个左转弯,本来一般情况下是不会发生装车事故的,但这次却直接撞上去了。
分析整个过程,特斯拉前面配有雷达,这个雷达的电磁波就直接扫过去了。主要是由于白色箱式火车的底盘过高,雷达汇报前方无障碍物,同时摄像头在不断地捕获前方图像,捕获回来其实就是白色的背景,这样的视觉图像汇报,让系统误认为前方是白云,就直接撞上去了,从而发生了非常惨烈的事件。
例子三,是谷歌公司发布的一个叫做图像的标注的系统。
只要上传一张图片,就可以打标签,打上了标签就可以对这个图片进行一次搜索。因为很多时候我们需要用文本信息或者单词来进行搜索图片,一旦打标签的话,我们就可以更好地进行文搜图的体验。
有这样的一件事情,一个黑人朋友上传了 一张图片,却被打上了黑猩猩的标签,于是他就状告了谷歌公司,说对他是人格上的侮辱,谷歌公司花了很大一笔钱才把这个官司给平息。
平息的过程中,谷歌就关闭了标注系统,不再打标签。过一段时间再开放的时候,就把黑猩猩从标注词典库里移除了,即使再上传的图片是黑猩猩,也不会被打上黑猩猩的标签。说明用数据驱动方法,实际在某些领域可以得到很好的应用,但可能在其它领域还会有很大的误读。
第三种,从经验中学
前面我们通过了用知识去教、用数据去学,第三种方法就是用问题引导学习,这就是我们经常说的强化学习。就是把一个智能体放到一个环境里面,它对这个环境做出一定的反应,这个环境对它奖励或者惩罚的一个结果。假如说我这里放了一台扫地机,它直接撞到一个桌子上,撞翻了,它就知道这是一个不可撞的东西,那它再做下一个调整的时候,它往左转、往右或往后走,它不停地从失败走向失败,最后又从失败走向了成功,它就对这种环境能够很好地感知到。
这种方法,我们叫做强化学习,或者是叫做从经验中学习,也就是没有任何知识和数据,就把它放在一个环境中进行感知以及认知。
像波士顿公司的两轮机器人以及中国电科院提供的67架固定翼的集群系统,还有美军103架的固定翼集群系统,就是在开放的环境中不停地进行感知和认知的学习,从而得到经验的提升。
这三种学习方法,并能够被判断为谁比谁好,谁要取代谁,其实它们彼此各有优点和不足。例如用规则教,确实和人的思维非常契合,逻辑很强,但我们确实很难把人类所有的规则和理念用来指导或者决策这个过程。
用数据去学的方法一定要依赖于标注的大数据。如果我们对于某个概念不能提供给它一个表示的大数据的话,它就无法学习。
如果可解读性不强,就算给它一张图片,它可以识别出是人脸,当你疑问知道它是人脸的原因,它同样也是无法得出,但是并不知道人脸的分布是否合适,例如说鼻子是对称的,眼睛是对称的,这样的知识在机器的学习系统中很难做到契合。
最后一种方法似乎也很不错,没有知识和数据,只要放在环境中进行交互就可以了。但是我们可以想象一下,当一个智能体撞到墙的时候,它可以采取的策略是无穷多的,它可以发呆、发萌、哭泣、愤怒,也可以不工作,有几万种选择,那到底从几万种选择中选择哪一种来应对撞墙的行为,这又是一个很难的问题。
因此,这三种方法其实各有各的优点,也有它的不足,但它体现了从数据到知识,从知识到能力的过程,最终能力并不重要。我们界定一个人工智能程序是否成功,不在于提供给它的是1TB还是10TB的数据,不在于是10万条的知识还是20万条的知识,而在于它已经生成了一种能力,这种能力可以指导它去处理新的数据和知识,以及构成新的知识的能力,这是非
常重要的。
从火热的人机博弈中,我们能看出什么?
用最近比较火热的Alpha Go来做解释。
我们知道Alpha Go是比较符合1955年提出的关于人工智能的理解。
Alpha Go首先选用了16万棋局,大约3000万盘的棋谱,通过黑白相间的棋子,凭借策略网络和一个快速走子网络进行训练。由于每盘棋我们都已经知道了是执黑会赢还是执白会赢,所以就会按照标准数据去训练,也就是说当遇到白棋的时候,我的黑棋落在哪儿,就是训练了这样一个人工智能的系统。
如果没有后面的故事,现在的Alpha Go也只能战胜人类选手的垄断棋手,但是如果可以实现两台机器自己和自己下棋,那技能就突飞猛进了,突飞猛进的结果就在2016年3月战胜李世石的那场比赛。
![]()
基于产生了大量数据做训练的价值网络,这种网络就可以有效预测整盘棋的下法。简单来说就是架构网络来预测这个棋子落下去后,整盘棋和剩下的棋况怎么样。今年4月在乌镇的那场较量,也就是战胜柯洁的那次,其实就是两台机器自己和自己博弈,进一步带来了能力的提升,也是完全基于这个强化学习的成果。
我们可以想到,Alpha Go中实质上有一个叫做利用探索的绑定。什么是利用探索呢?它是19×19的黑白相间的棋盘,里面只放黑棋和白棋,总共有多少种摆放的方法?
答案是2的381次方。2的381次方等于宇宙所有原子的数量,所以Alpha Go不可能把2的381次方都分辨一次,它只能尽量去判断哪一种摆放的方式是最好的。
在这个过程中,它就会把所有的信息都利用起来,也就意味着会尽量去研究或者实践人类没有下过的棋局,所以很多时候我们看到Alpha Go下的棋局很怪,因为人类选手从来没有尝试过。
每下一个棋子的时候,Alpha Go已经预测出这个棋谁胜。
大家可以看到,Alpha Go挑战的过程中,它失去了信心,因为已经预测自己获得整盘棋的胜利的概率一直下降,它没有了战胜对手的勇气,这个很危险。
通常来讲,人类才会有置之死地而后生,背水一战的勇气。有些情况下是可以扳回一局的,但人工智能已经失去了它的斗志,只有三种网络都被利用的时候,它才会取得胜利。
2的381次方可能比宇宙的原子还多,如果量子计算机被制造出来,MIT说100个量子进行纠缠,就等于人类所有计算能力的综合,所以那个时候就不用某个模式搜索,也可以做到辨别所有的可能。
上面说的情况被称为完全机器人架构博弈,当然还存在非完全机器人架构博弈。就像泰利美工大学的德州扑克,其实就是一个非完全机器下的博弈。对于我们来说,围棋都是规则已知、策略已知 、胜负已知,相对来说比较明白直观,但是打扑克的话很多信息就不是很清楚了。
我们做了一个总结,像迭代辅助,Alpha Go,Alpha Go Zero……它们都有非常多的数据支持或者各种算法模型。可以看到,有些是利用知识,有些是利用数据,有些是利用经验去学习,其实这种智能学习的算法需要不停地交会、融合。
人工智能是不断往前发展的,我们希望把大数据虚拟的人工智能方法,从利用知识的人工智能,转变为从环境中获得学习能力进而提升效率的人工智能,如果能很好地协调和统一,可能就会形成一种更好的齿轮咬合能力。
从九轮计算到深度推理,从单纯计算到数据驱动的模型,再发展到数据驱动与引导相结合,从领域任务驱动的人工智能过渡到通用条件下的强人工智能,我们说强人工智能就是放到一个环境中能够自己不断学习的人工智能类型。科学杂志在今年 7 月 7 号推出了人工智能专刊,人工智能在大数据洪流里面会发生变革性的因素,也有很玄的东西。
实际上人工智能并没有那么强大,即使像阿尔法狗 ZERO,也有需要提升的空间。但是从中学到的东西,却能很好的帮助人类发展。据说整个宇宙有百分之一的东西是我们已经知道的,这么分析人工智能已经很不容易, 尽管现在的人工智能还没有全覆盖。
硬货 | 一文解读完五篇重磅ACL2017 NLP论文
资源 | 盘点国外NLP领域40大高校及相关知名学者
在阿里AI实验室做NLP高级算法工程师是一种什么样的体验?
CSDN创始人蒋涛:中国智能音箱大战,我为何看好小米
一文看尽深度学习RNN:为啥就它适合语音识别、NLP与机器翻译?
专访 | 德国大神Hans Uszkoreit:语言才是AI的关键,深度学习无法解决NLP的核心问题
智能音箱大战全面开火,那么问题来了:如何成为一名全栈语音识别工程师?
![]()