【矿友必读】如何用机器学习解释市值?

本文利用优矿上的财务数据与回测框架,参考东方证券《用机器学习解释市值:特异市值因子》中的研究方法,对研报的结果进行了实证分析,用以探索非线性模型在市值解释模型中的应用。主要结论如下:
本文利用OLS线性回归与xgboost回归建立了两种市值解释模型,OLS模型的R2为78.7%,xgboost模型的R2达到了95.4%,xgboost模型更好的解释了市值特性,最后利用模型的残差部分构建了特异市值因子;
非线性模型提取的因子表现较线性模型更好:从IC来看,线性模型的IC均值-0.0733,ICIR在-2.7691;xgboost模型的IC均值-0.0791,ICIR在-3.2847。并且在剔除掉传统的估值、成长、反转等因子后,特异市值因子仍有较强选股能力;
从选取TOP100股票的回测结果看出,非线性模型提取的因子更有优势。xgboost模型提取的因子IR在1.45左右、年化收益20.03%,线性回归模型提取的因子IR为1.34、年化收益17.4%。
本文共分为4个部分,具体如下:
一、数据准备,主要是加载财务数据,及部分因子数据;
二、市值解释模型,主要是建立OLS线性回归及xgboost回归模型来解释市值,最后取模型残差作为特异市值因子;
三、因子分析,主要分析两种模型提取的因子选股效用,并考察了特异市值因子与传统的估值、成长、反转等因子的相关性;
四、因子回测,利用回测框架对正交化后的两种模型抽取的因子进行了回测。
1数据准备
该部分内容包括:
1.1 加载财务数据,包括净资产、净利润、负债、营业收入,开发支出等数据;
1.2 加载因子数据与下月收益数据,因子包括PB, PE, 反转、换手因子。
1.1 加载财务数据
本文仿照研报数据,首先加载后续模型中需要用到的相关财务数据, 包括净资产、净利润、负债、营业收入,开发支出等数据。
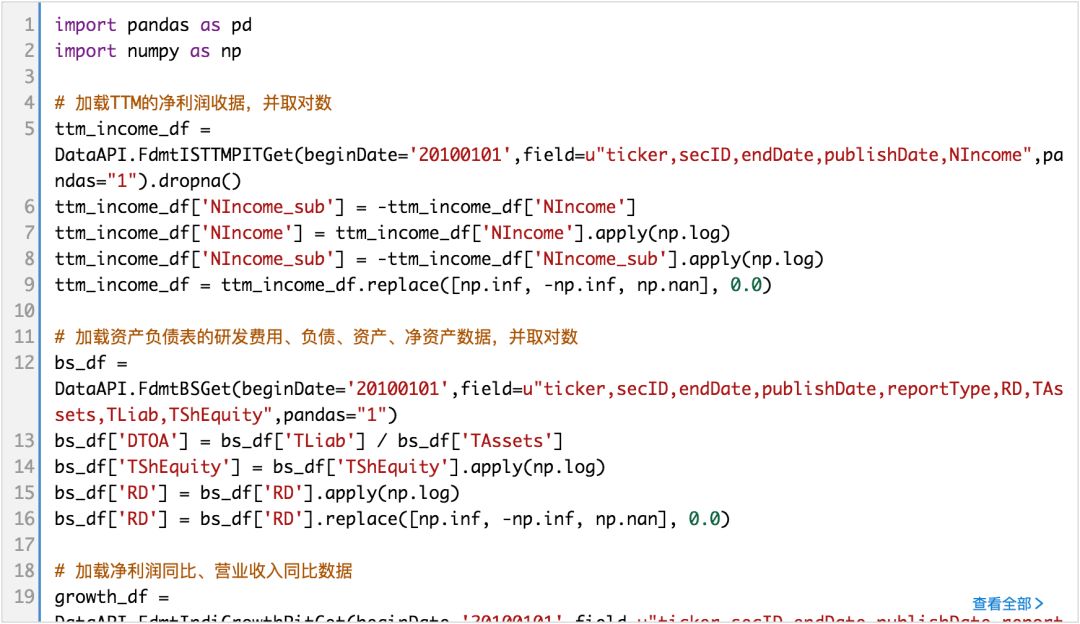
(完整版可点击文末“阅读原文”获取)
1.2 加载因子数据与下月收益数据
加载部分常见因子数据,为后续正交化特异市值因子做准备。因子包括PB, PE, 反转、换手因子;
加载下月收益数据,便于计算IC。
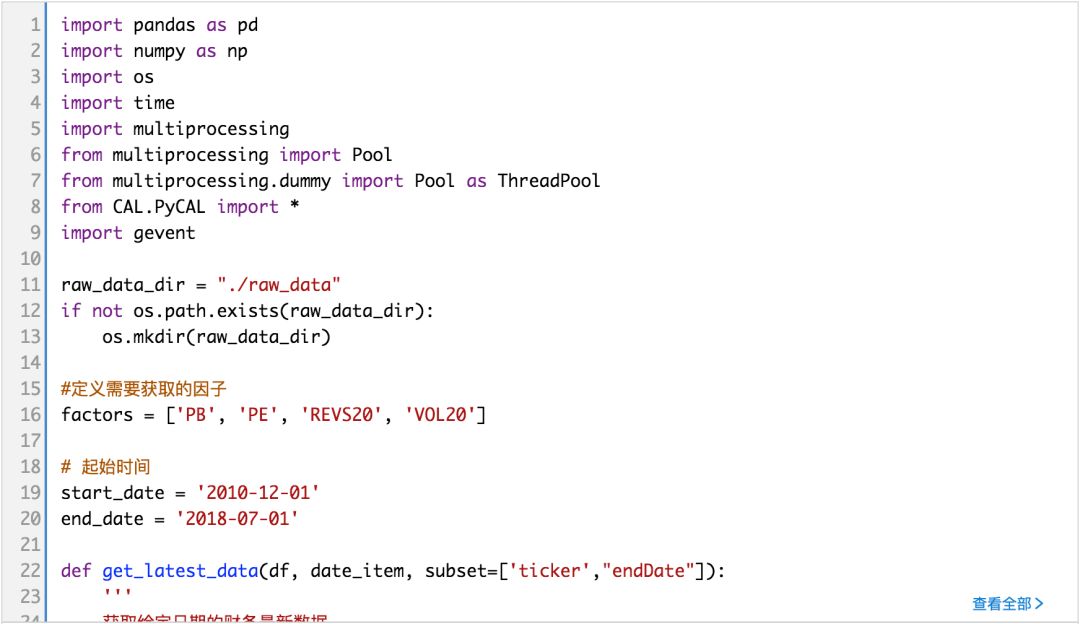
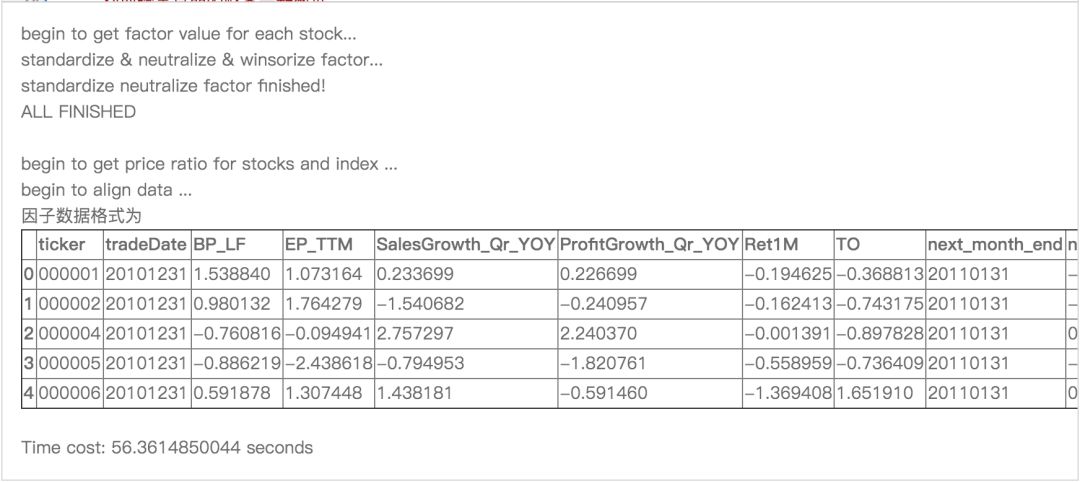
(完整版可点击文末“阅读原文”获取)
2市值解释模型
本章节利用线性模型与Xgboost模型来解释市值
1、线性市值解释模型
模型形式为:
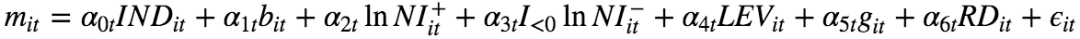
其中, mit为股票i在t时候的对数市值,INDit为行业哑变量,bit为股票对数净资产,NI为公司净利润,这里根据净利润的正负拆分了两个变量,LEVit为公司财务杠杆,即负债除以资产, git为季度同比的营业收入增长率, RDit为开发支出。
2、xgboost非线性市值解释模型
将线性模型的自变量作为xgboost模型的输入特征,对数市值作为数据的标签,进行训练;


(完整版可点击文末“阅读原文”获取)
利用上述定义的函数及常量,分别训练两种模型,取其残差经过去极值、行业中性化、标准化后作为特异市值因子;
最后,分析线性模型与xgboost模型的拟合程度。
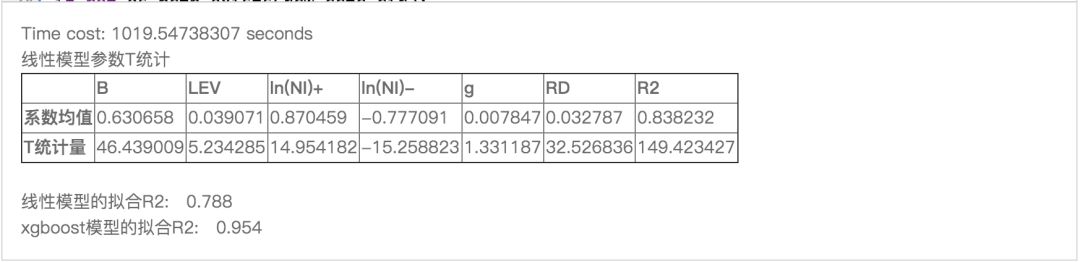
(完整版可点击文末“阅读原文”获取)
可以看出,线性模型的系数均显著,拟合R2均值78.8%左右;非线性模型拟合R2高达95.4%,与线性模型相比提升了16.6%的解释程度,因此非线性模型的残差部分基本面信息更少,信号的纯净度更高。
3因子分析
本章节有如下内容:
因子测试,主要是测试线性模型与xgboost模型的特异市值因子表现情况,主要查看分组超额收益与IC。注意:此处回测采取了简易回测,节省时间,没考虑交易费用,涨跌停等;
查看特异市值因子与常见财务面、技术面因子(包括BP, EP, 反转、换手率等)的相关性,正交化特异市值因子后,再进行因子测试。
3.1 因子回测
首先,合并第一章节读取的因子文件与第二章节训练的两个模型信号文件,方便后续分析。

(完整版可点击文末“阅读原文”获取)
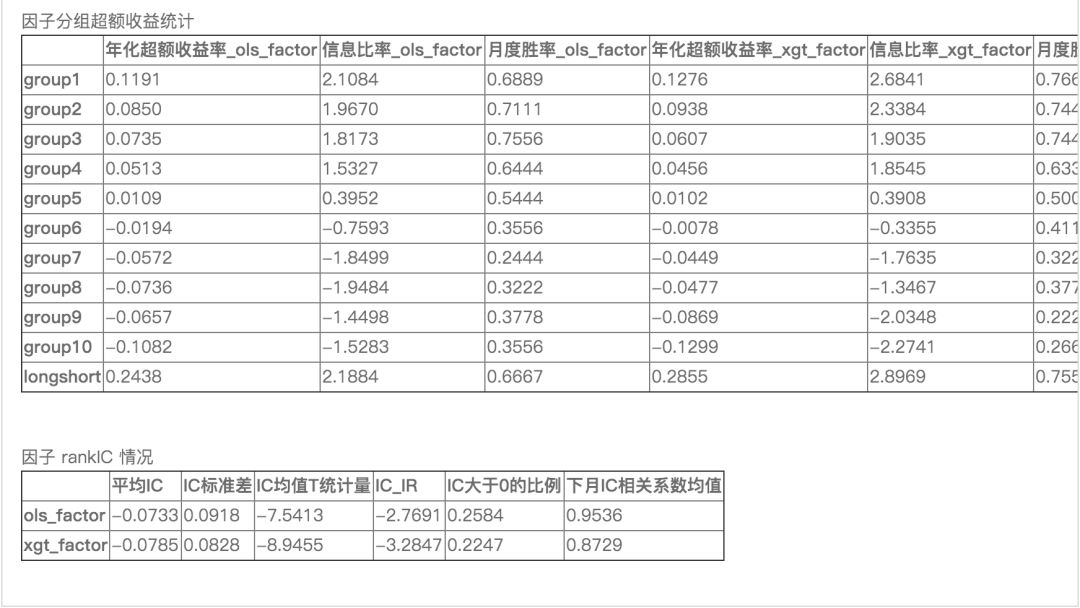
进行特异市值因子的分组测试,并查看IC。
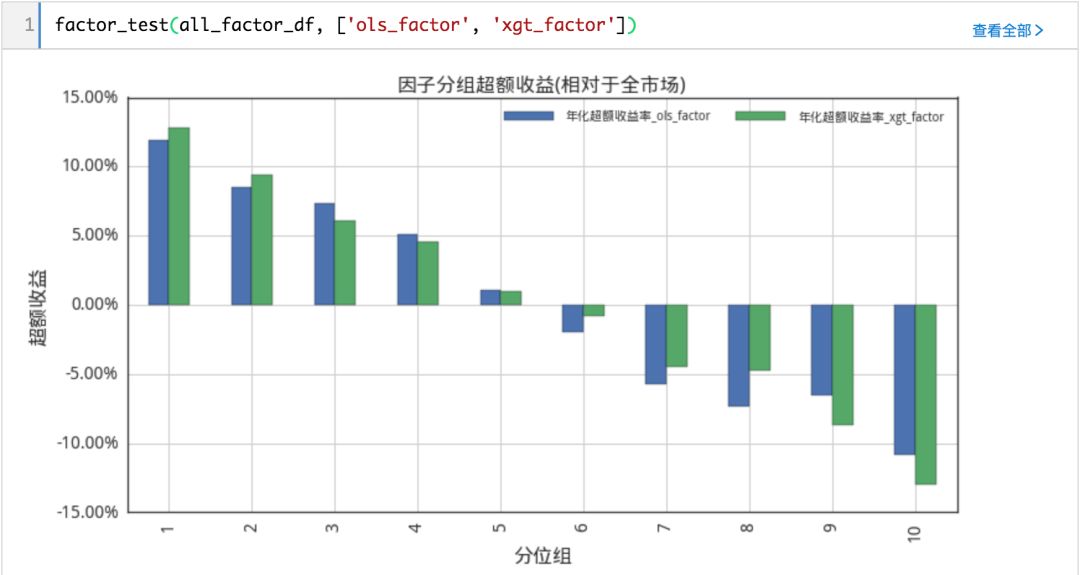
(完整版可点击文末“阅读原文”获取)
可以看出,xgboost模型表现较线性模型更好
从分组回测来看,线性模型提取的因子long-short年化收益24.3%,信息比率2.19;而xgboost模型提取的因子long-short年化收益28.5%,信息比率2.89;
从IC来看,线性模型的IC均值-0.0733,ICIR在-2.7691;xgboost模型的IC均值-0.0791,ICIR在-3.2847。
3.2 相关性分析及正交化特异市值因子
首先,查看特异市值因子与一些常见财务、技术面因子的相关性情况。

(完整版可点击文末“阅读原文”获取)
从上表可知,特异市值因子与BP因子有很强的相关性,所以需要剔除掉这些相关因子后,再次查看特异市值因子的选股效用。
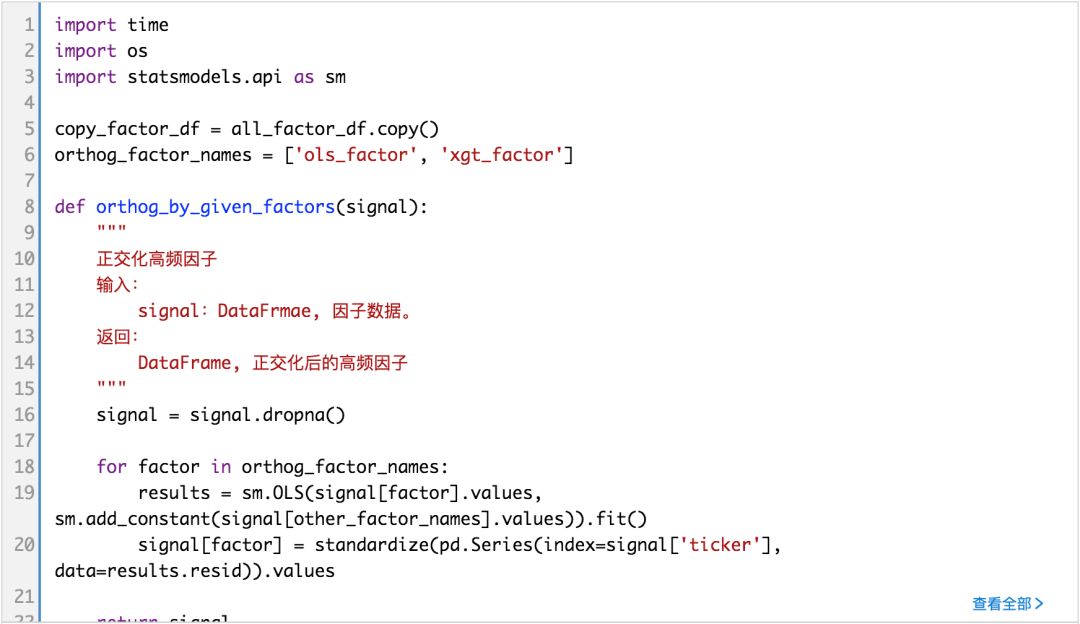
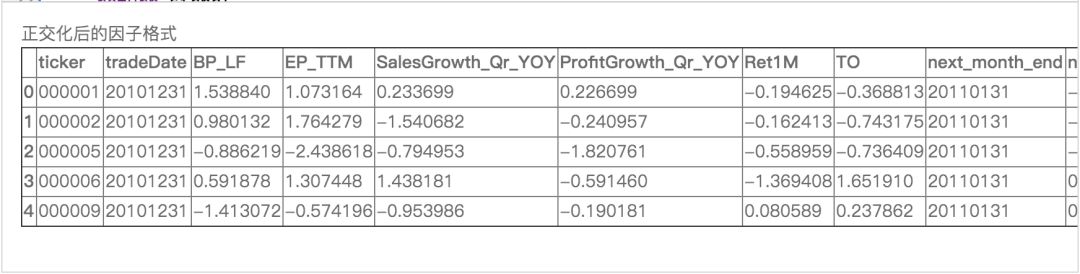
(完整版可点击文末“阅读原文”获取)
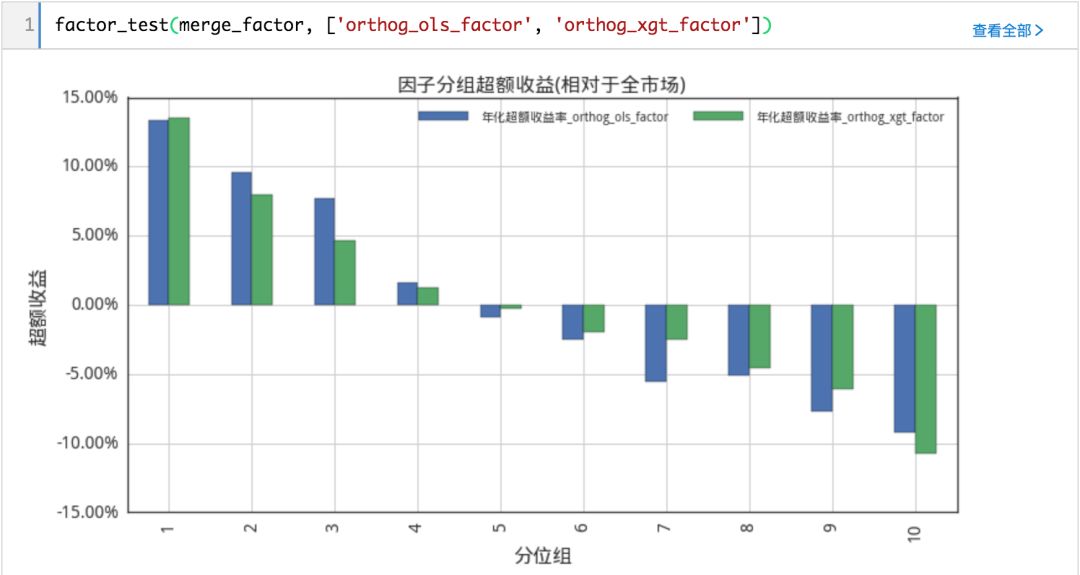
对正交化后的特异市值因子进行测试。
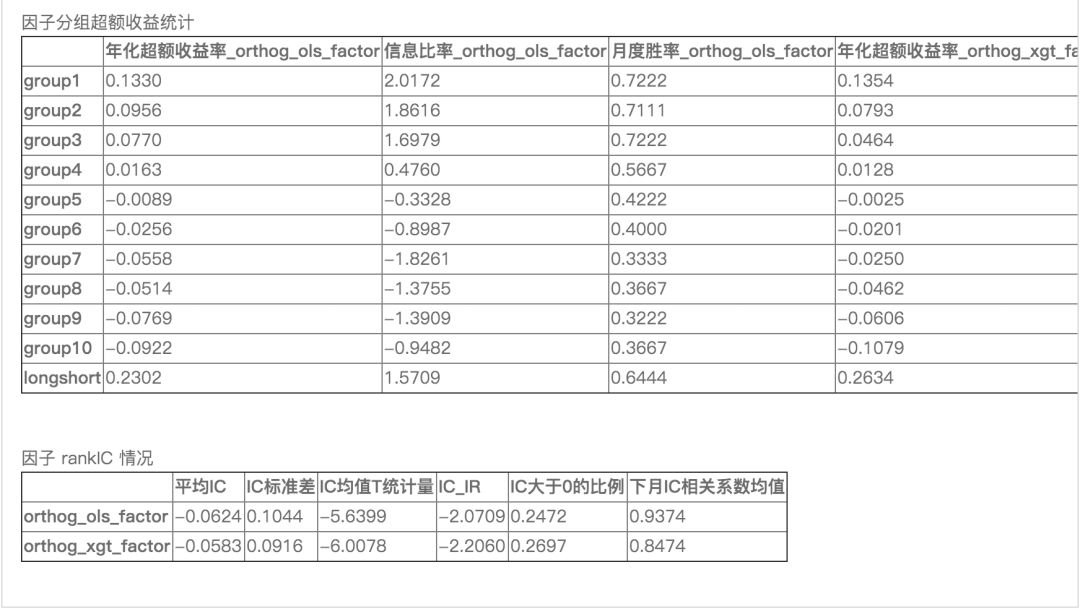
(完整版可点击文末“阅读原文”获取)
可以看出,正交化后特异市值因子的效果有些减弱,但xgboost模型提取的因子效果依然强于线性模型。
4因子回测
4.1 回测框架
对正交后的两种模型抽取的特异市值因子进行回测,选取中证全指为基准,每次选取100个股票。选取的股票等权分配。
(完整版可点击文末“阅读原文”获取)
4.2 回测结果分析

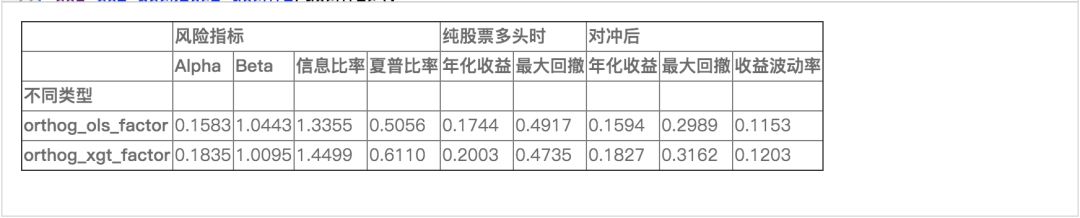
(完整版可点击文末“阅读原文”获取)
回测结果看出,非线性模型提取的因子更有优势。xgboost模型提取的因子IR在1.45左右、年化收益20.03%,线性回归模型提取的因子IR为1.34、年化收益17.4%。
另外,本文只是选取了TOP100的股票进行回测,只用了因子的头部信息,读者也可以尝试其他方法进行测试。
参考
1、 东方证券 《用机器学习解释市值:特异市值因子》——《因子选股系列研究之二十八》
-- the end --
利用平台强大的资源,优矿特推出2018量化精英养成计划,培养最优秀的Quants,寻找夜空中最亮的那颗星!来自毕业于牛津大学、北京大学、香港大学等高校的地表最强量化金工团队,手把手带你从0到1玩转量化。点击下图了解详情

(点击图片了解详情)
优矿是由通联数据出品,覆盖研究、回测、模拟、实盘交易全流程的量化平台。优矿不仅拥有通联海量的金融数据、动态丰富的策略框架,同时还通过知识库信号库提供持续的知识输出,满足用户在研究过程中高效获取、迅速验证、多维度挖掘、多策略并行的迫切需求,为投资决策提供重要支持。

扫二维码,立即预约试用!
↓↓↓ 点击"阅读原文" 【查看源码】




