超级干货 :一文读懂特征工程
本文结构
1. 概述
机器学习被广泛定义为“利用经验来改善计算机系统的自身性能”。事实上,“经验”在计算机中主要是以数据的形式存在的,因此数据是机器学习的前提和基础。数据来源多种多样,它可以是结构数据,如数值型、分类型,也可以是非结构数据,如文本、语音、图片、视频。对于所有机器学习模型,这些原始数据必须以特征的形式加入到机器学习模型当中,并进行一定的提取和筛选工作。所谓特征提取,就是逐条将原始数据转化为特征向量的形式,此过程涉及数据特征的量化表示;而特征筛选是在已提取特征的基础上,进一步对高维度和已量化的特征向量进行选择,获取对指定任务更有效果的特征组合以提升模型性能。
在机器学习和模式识别中,特征是在观测现象中的一种独立、可测量的属性。选择信息量大的、有差别性的、独立的特征是模式识别、分类和回归问题的关键一步,其终极目的在于最大限度地从原始数据中提取特征以供算法和模型使用。特征工程的好坏将会影响整个模型的预测性能,另一方面,相比一些复杂的算法,灵活地处理好数据经常会取到意想不到的效益。
数据挖掘和机器学习界有这么一句广泛流传的话:数据和特征决定了机器学习的上限,而模型和算法是在逼近这个上限而已。换句话说,好的数据和特征是所有模型和算法发挥到极致的前提。
2. 数据的预处理
现实世界中数据大体上都是不完整,不一致的脏数据,无法直接进行提供给机器学习模型。为了提高数据利用的质量产生了数据预处理技术。
2.1 无量纲化
无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化、区间缩放法和正则化。标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围。数据正则化针对单个样本,将样本某个范数缩放到单位1。
2.1.1 标准化
数据标准化是将样本的属性缩放到某个指定的范围,标准化的原因在于:
某些算法要求数据具有零均值和单位方差。
样本不同特征有不同的量级和单位。所有依赖于样本距离的算法(如KNN)对于数据的数量级都非常敏感。量级大的特征属性将占主导地位,且量级的差异会导致迭代速度减慢。为了消除量级的影响,必须进行数据标准化。
标准化公式为:
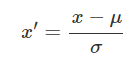
其中,
使用preproccessing库的StandardScaler类对数据进行标准化的代码如下:
from sklearn.preprocessing import StandardScaler #标准化,返回值为标准化后的数据 StandardScaler().fit_transform(iris.data)2.1.2 区间缩放法
区间缩放法的思路有多种,常见的一种为利用两个最值min、max进行缩放,公式为:
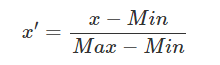
使用preproccessing库的MinMaxScaler类对数据进行区间缩放的代码如下:
from sklearn.preprocessing import MinMaxScaler #区间缩放,返回值为缩放到[0, 1]区间的数据 MinMaxScaler().fit_transform(iris.data)2.1.3 数据正则化
数据正则化将样本某个范数缩放到单位1,是针对单个样本的,对于每个样本将样本缩放到单位范数。其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准。规则为L2的正则化公式为:
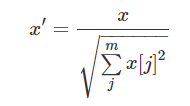
使用preproccessing库的Normalizer类对数据进行正则化的代码如下:
from sklearn.preprocessing import Normalizer #归一化,返回值为归一化后的数据 Normalizer().fit_transform(iris.data)2.2 特征二元化
特征二元化的过程是将数值型数据转换为布尔型属性。设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下:

使用preproccessing库的Binarizer类对数据进行二值化的代码如下:
from sklearn.preprocessing import Binarizer #二值化,阈值设置为3,返回值为二值化后的数据 Binarizer(threshold=3).fit_transform(iris.data)2.3 特征哑编码
哑编码(One Hot Encoding)采用N位状态寄存器对N个可能的取值进行编码,每个状态都由独立的寄存器位来表示,并且在任意时刻只有其中一位有效。假设某个属性的取值为非数值的离散集合[离散值1,离散值2,…,离散值m],则针对该属性的编码为一个m元的元组,且该元组的分量有且只有一个为1,其余都为0。
One Hot Encoding能够处理非数值属性;在一定程度上也扩充了特征,如性别本身是一个属性,经过One Hot Encoding后变成了男或女两个属性;编码后的属性是稀疏的,存在大量的零元分量。
使用preproccessing库的OneHotEncoder类对数据进行哑编码的代码如下:
from sklearn.preprocessing import OneHotEncoder #哑编码,对IRIS数据集的目标值,返回值为哑编码后的数据 OneHotEncoder().fit_transform(iris.target.reshape((-1,1)))2.4 缺失值处理
2.4.1 删除缺失值
直接删除缺失值,这是最简单最直接的方法,有的时候也是最有效的方法,但这种方法可能会导致信息丢失。
当某列特征的缺失值较多时,一般选择舍弃该特征,否则较多的缺失值反会引入过多的噪声,对预测结果造成不利影响。
2.4.2 数据补全
用规则或模型将缺失数据补全,这种做法的缺点是可能会引入噪声:
均值插补
采用同类值插补
建模预测
高维映射
多重插补
极大似然估计
压缩感知及矩阵补全
2.4.3 忽略缺失值
一些机器学习模型(如决策树算法)能够直接处理数据缺失的情况,在这种情况下不需要对缺失数据做任何的处理,这种做法的缺点是在模型的选择上有局限。
3. 特征选择
不同的特征对模型的准确度的影响不同,有些特征与要解决的问题不相关,有些特征是冗余信息,这些特征都应该被移除掉。
对于当前学习任务有用的属性称为相关特征(relevant feature)
对于当前学习任务无用的属性称为无关特征(irrelevant feature)
特征选择是自动地选择出对于问题最重要的那些特征子集的过程。进行特征选择有两个重要原因:
首先维数灾难问题就是由于属性过多造成的。若挑选出重要特征,使得后续学习过程仅仅需要在这一小部分特征上构建模型,则维数灾难问题会大大减轻。
其次去除不相关特征通常会降低学习任务的难度。
特征选择必须确保不丢失重要信息,若重要信息缺失则学习效果会大打折扣。常见的特征选择方法大致分为三类:过滤式(filter)、包裹式(wrapper)、嵌入式(embedding)。
3.1 过滤式选择
过滤式特征选择按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
3.1.1 方差选择法
方差很小的属性,意味着该属性的识别能力很差。极端情况下,方差为0,意味着该属性在所有样本上都是一个值,可以通过scikit-learn提供的VarianceThreshold来剔除。
from sklearn.feature_selection import VarianceThreshold #方差选择法,返回值为特征选择后的数据 #参数threshold为方差的阈值 VarianceThreshold(threshold=3).fit_transform(data)threshold:一个浮点数,指定方差的阈值,低于此阈值的将被剔除。
data:样本数据。
fit_transform:从样本数据中学习方差,然后执行特征选择。
3.1.2 单变量特征提取
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。用feature_selection库的SelectKBest类结合相关系数来选择特征的代码如下:
from sklearn.feature_selection import SelectKBest,f_classif X=[[1,2,3,4,5], [5,4,3,2,1], [3,3,3,3,3], [1,1,1,1,1]] ] y=[0,1,0,1] selector = SelectKBest(score_func=f_classif,k=3) selector.fit(X,y)SelectKBest:保留在该统计指标上得分最高的K个特征。
score_func:给出统计指标的函数,其参数为数组X和数组y,返回值为(score,pvalues)。
f_classif:根据方差分析,ANOVA的原理,依靠F-分布为概率分布的依据,利用平方和与自由度所计算的组间与组内均方估计出F值,适用于分离问题。
3.2 包裹式选择
包裹式特征选择根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。这类方法的核心思想在于,给定了某种模型,及预测效果评价的方法,然后针对特征空间中的不同子集,计算每个子集的预测效果,效果最好的,即作为最终被挑选出来的特征子集。注意集合的子集是一个指数的量级,故此类方法计算量较大。故而针对如何高效搜索特征空间子集,就产生了不同的算法。其中有一种简单有效的方法叫贪婪搜索策略,包括前向选择与后向删除。在前向选择方法中,初始化一个空的特征集合,逐步向其中添加新的特征,如果该特征能提高预测效果,即得以保留,否则就扔掉。后向删除即是说从所有特征构成的集合开始,逐步删除特征,只要删除后模型预测效果提升,即说明删除动作有效,否则就还是保留原特征。要注意到,包裹式方法要求针对每一个特征子集重新训练模型,因此计算量还是较大的。
通常,将过滤式方法的高效与包裹式方法的高准确率进行结合,可得到更优的特征子集。混合特征选择过程一般由两个阶段组成:
1)使用Filter方法初步剔除大部分无关或噪声特征,只保留少量特征,从而有效地减小后续搜索过程的规模。
2)将剩余的特征连同样本数据作为输入参数传递给Wrapper选择方法,以进一步优化选择重要的特征。
优点:准确率高。
缺点:为选择出性能最好的特征子集,Wrapper算法需要的计算量巨大;该方法所选择的特征子集依赖于具体学习机;容易产生“过适应”问题,推广性能较差。
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。使用feature_selection库的RFE类来选择特征的代码如下:
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression #递归特征消除法,返回特征选择后的数据 #参数estimator为基模型 #参数n_features_to_select为选择的特征个数 RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(data, target)estimator: 一个学习器,它必须提供一个fit方法和一个coef_属性。
n_features_to_select:一个整数或None,指定要选出几个特征。如果为None,默认选取一半的特征。
3.3 嵌入式选择
嵌入式特征选择先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于过滤式方法,但是是通过训练来确定特征的优劣。
优点:相对于包裹式方法,不用将训练数据集分成训练集和测试集两部分,避免了为评估每一个特征子集对学习机所进行的从头开始的训练,可以快速地得到最佳特征子集,是一种高效的特征选择方法。
缺点:构造一个合适的函数优化模型是该方法的难点。
scikit-learn提供了SelectFromModel来实现嵌入式特征选取。SelectFromModel使用外部提供的estimator来工作。当某个特征对应的coef或者feature_importance低于某个阈值时,该特征将被移除。也可以不指定阈值,而使用启发式的方法,如指定均值mean,指定中位数median或者指定这些统计量的倍数。
3.3.1 基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel from sklearn.linear_model import LogisticRegression #带L1惩罚项的逻辑回归作为基模型的特征选择 SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(iris.data, iris.target)3.3.2 基于树模型的特征选择法
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel from sklearn.ensemble import GradientBoostingClassifier #GBDT作为基模型的特征选择 SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)4. 降维
当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。常见的降维方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
4.1 主成分分析法(PCA)
4.1.1 PCA原理
Principal Component Analysis(PCA)是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中表示,并期望在所投影的维度上数据的方差最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性。
通俗的理解,如果把所有的点都映射到一起,那么几乎所有的信息(如点和点之间的距离关系)都丢失了,而如果映射后方差尽可能的大,那么数据点则会分散开来,以此来保留更多的信息。可以证明,PCA是丢失原始数据信息最少的一种线性降维方式。(实际上就是最接近原始数据,但是PCA并不试图去探索数据内在结构)
设n维向量w为目标子空间的一个坐标轴方向(称为映射向量),最大化数据映射后的方差,有:
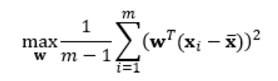
其中m是数据实例的个数,
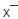
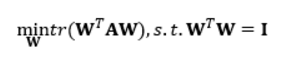
其中tr表示矩阵的迹,
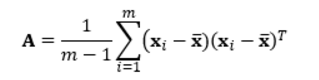
A是数据协方差矩阵。
容易得到最优的W是由数据协方差矩阵前k个最大的特征值对应的特征向量作为列向量构成的。这些特征向量形成一组正交基并且最好地保留了数据中的信息。
PCA的输出就是Y = W‘X,由X的原始维度降低到了k维。
PCA追求的是在降维之后能够最大化保持数据的内在信息,并通过衡量在投影方向上的数据方差的大小来衡量该方向的重要性。但是这样投影以后对数据的区分作用并不大,反而可能使得数据点揉杂在一起无法区分。这也是PCA存在的最大一个问题,这导致使用PCA在很多情况下的分类效果并不好。具体可以看下图所示,若使用PCA将数据点投影至一维空间上时,PCA会选择2轴,这使得原本很容易区分的两簇点被揉杂在一起变得无法区分;而这时若选择1轴将会得到很好的区分结果。
4.1.2 PCA代码实现
使用decomposition库的PCA类选择特征的代码如下:
from sklearn.decomposition import PCA #主成分分析法,返回降维后的数据 #参数n_components为主成分数目 PCA(n_components=2).fit_transform(iris.data)4.2 线性判别分析法(LDA)
4.2.1 LDA原理
Linear Discriminant Analysis (也有叫做Fisher Linear Discriminant)是一种有监督的(supervised)线性降维算法。与PCA保持数据信息不同,LDA是为了使得降维后的数据点尽可能地容易被区分。
假设原始数据表示为X,(m*n矩阵,m是维度,n是sample的数量)
既然是线性的,那么就是希望找到映射向量a,使得 a’X后的数据点能够保持以下两种性质:
同类的数据点尽可能的接近(within class)
不同类的数据点尽可能的分开(between class)
举一个直观的例子,如下图:红色和蓝色点代表数据分别属于两个不同类,与PAC最大化保持数据信息的思想不同,LDA会这样降维这两堆点
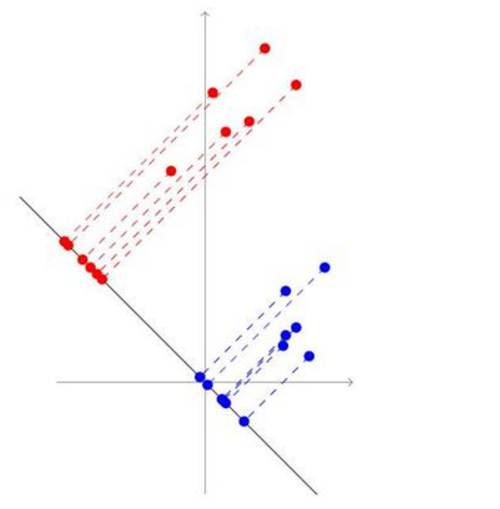
可以看到,虽然降维之后数据更加聚集了,但是更好区分了。
一般地,设有数据集D,投影向量为,则点xi经过投影后为
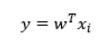
投影前的样本中心点为,投影后的中心点为
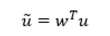
我们希望投影后不同类别的样本尽量离得较远,使用度量值:
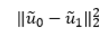
我们同时希望投影后相同类别的样本之间尽量离得较近,使用度量值:
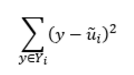
所以总的优化目标函数为:
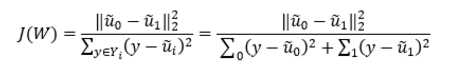
J(W)自然是越大越好。
定义类内散度矩阵为:
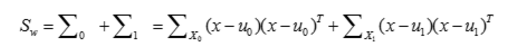
定义类间散度矩阵:
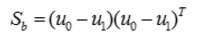
所以
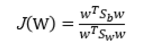
因为向量w的长度成比例改变不影响J的取值,所以我们令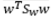
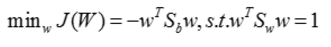
使用拉格朗日乘子法,解得:
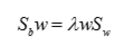
进一步解得:
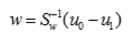
4.2.2 LDA代码实现
使用lda库的LDA类选择特征的代码如下:
from sklearn.lda import LDA #线性判别分析法,返回降维后的数据 #参数n_components为降维后的维数 LDA(n_components=2).fit_transform(iris.data, iris.target)4.3 PCA与LDA的对比
PCA与LDA降维的对比:
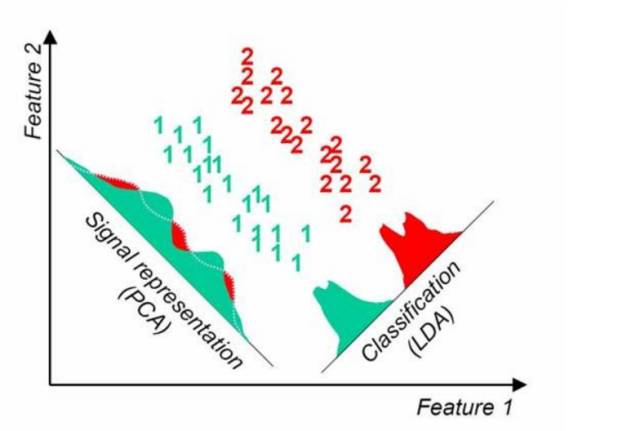
PCA选择样本点投影具有最大方差的方向,LDA选择分类性能最好的方向。
PCA技术的一个很大优点在于,它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关,与用户是独立的。但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
LDA以标签类别衡量差异性的有监督降维方式,相对于PCA的模糊性,其目的更明确,更能反映样本间的差异。缺点在于局限性大,受样本种类限制,且至多可生成C-1维子空间(C为类别数量),也就是说LDA降维后的维度空间在[1,C-1],与原始特征无关。因此,对于二分类问题,最多投影到1维。另外,LDA不适合对非高斯分布样本进行降维。
参考资料
博客/文档:
http://www.cnblogs.com/jasonfreak/p/5448385.html
http://www.cnblogs.com/LeftNotEasy/archive/2011/01/08/lda-and-pca-machine-learning.html
https://www.zybuluo.com/gump88/note/402479
https://wenku.baidu.com/view/37055bd4a300a6c30d229f30.html
书籍:
Python大战机器学习 (华校专 等著)

数据挖掘实用机器学习工具与技术 (Ian H Witten 等著,李川 等译)

机器学习 (周志华 著)

机器学习及实践 (范淼 等著)

教程:
数据前处理:http://scikit-learn.org/stable/modules/preprocessing.html
特征选择:http://scikit-learn.org/stable/modules/feature_selection.html
PCA:http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
LDA:http://scikit-learn.org/0.15/modules/generated/sklearn.lda.LDA.html
作者介绍:
姚易辰:数据派研究部志愿者,清华大学工程力学系博士生。天池大数据平台top10选手,曾获天池大数据IJCAI16口碑实体商户推荐赛冠军和菜鸟网络最后一公里极速配送冠军,擅长数据分析及图像处理。
本文转自:数据派THU 公众号;

END
优秀人才不缺工作机会,只缺适合自己的好机会。但是他们往往没有精力从海量机会中找到最适合的那个。100offer 会对平台上的人才和企业进行严格筛选,让「最好的人才」和「最好的公司」相遇。
扫描下方二维码或点击“ 阅读原文 ”,注册 100offer,谈谈你对下一份工作的期待。一周内,收到 5-10 个满足你要求的好机会!

关联阅读
原创系列文章:
数据运营 关联文章阅读:
数据分析、数据产品 关联文章阅读:



