世界模型在通用人工智能(AGI)发展的过程中受到越来越多的关注,作为一种计算框架,用于学习外部世界的表征并预测未来状态。早期的研究主要集中在二维视觉感知与模拟上,而近年来具备三维感知能力的生成式世界模型已能够合成在几何上保持一致的可交互三维环境,标志着研究重心正逐步转向三维空间认知。尽管该领域发展迅速,尚缺乏系统性的分析来对新兴技术进行分类,并阐明其在推动三维认知世界模型中的作用。为填补这一空白,本文引入了一个概念框架,对世界模型从二维感知向三维认知的演进过程进行了结构化且前瞻性的综述。在该框架下,我们重点突出了两项关键技术驱动力,尤其是三维表征技术的进步与世界知识的引入,作为其基本支柱。在此基础上,我们进一步剖析了支撑三维世界建模的三项核心认知能力:三维物理场景生成、三维空间推理与三维空间交互。此外,本文还探讨了这些能力在实际应用中的部署情况,包括具身智能体、自动驾驶、数字孪生以及游戏/虚拟现实等。最后,我们总结了当前在数据、建模与部署方面面临的挑战,并提出了推动更加稳健且具泛化能力的三维世界模型未来发展的方向。
1.1 技术演化 世界模型的概念可追溯至认知科学中的“心理模型”(Mental Models)理论 [69]。心理学家 Kenneth Craik 提出,人类通过抽象外部世界为基本元素及其相互关系以实现认知与推理。系统动力学先驱 J. W. Forrester 将类似原理用于建模复杂系统,进一步验证了抽象表征在理解与预测系统行为中的效用 [37]。这套理论也为早期强化学习与机器人控制研究奠定了哲学基础,使智能体能够学习环境动态的内部模型。 2018 年,D. Ha 和 J. Schmidhuber 提出了一种影响深远的世界模型方法 [46, 47],通过将变分自编码器(VAE)用于高维感知输入的空间压缩,与循环神经网络(RNN)用于时间动态建模相结合,构建了分层架构。类似方法 [17, 48, 49, 134] 使智能体能够通过时空潜在表示模拟环境动态,并预测假设性动作序列的结果,在如赛车导航等复杂决策任务中超越传统的模型驱动强化学习方法。
2022 年,Yann LeCun 提出 Joint Embedding Predictive Architecture(JEPA)[79],受生物学习机制启发,允许机器以类似人类与动物的方式观察和理解世界。JEPA 通过非生成式预测学习方式,在多层次抽象与时间尺度上分解复杂任务。首先,JEPA 将多模态感知输入投射到联合嵌入空间,生成抽象的环境状态,该空间对世界动态实现高效编码,有助于从有限观测中学习稳健表征并预测未来状态。随后,JEPA 通过三个操作层建模多尺度时间依赖性:高层预测器负责长期目标规划,中层协调动作序列,低层实现精确动作控制,从而缓解传统模型在长依赖建模中的局限性并提升可解释性。V-JEPA [7] 将该架构扩展至视频数据,实现对视觉表征中多尺度时间依赖的分层建模。另一项值得关注的抽象推理研究是对比预测编码(CPC)[153],通过自监督对比学习获取紧凑的潜在表征,支持时间抽象与状态压缩。 相对于抽象结构化建模路径,另一类世界模型依赖于生成式 AI 范式,如自回归模型与扩散模型,通过显式重构数据来学习世界知识。这类模型可生成包括文本 [29]、图像 [6, 111, 120, 132, 181] 和视频 [11, 33, 41, 42, 44, 51, 75, 182] 等多模态数据。典型实例包括大型语言模型(LLMs)[2, 12, 130, 131] 和 Sora [114]。基于 Transformer 全局注意机制的自回归架构可有效捕捉长程时空依赖,实现世界状态的多步学习与预测;扩散模型则通过逐步添加噪声并学习逆向去噪过程以模拟数据分布,从而生成高保真视觉内容。OpenAI 将 Sora 定义为“世界模拟器”,并认为其有潜力作为构建全面世界模拟的基础工具。一些研究分析 [23] 表明,Sora 具备世界模型的特性,在建模基本物理现象方面展现出涌现能力。
1.2 从二维视觉表征迈向三维认知
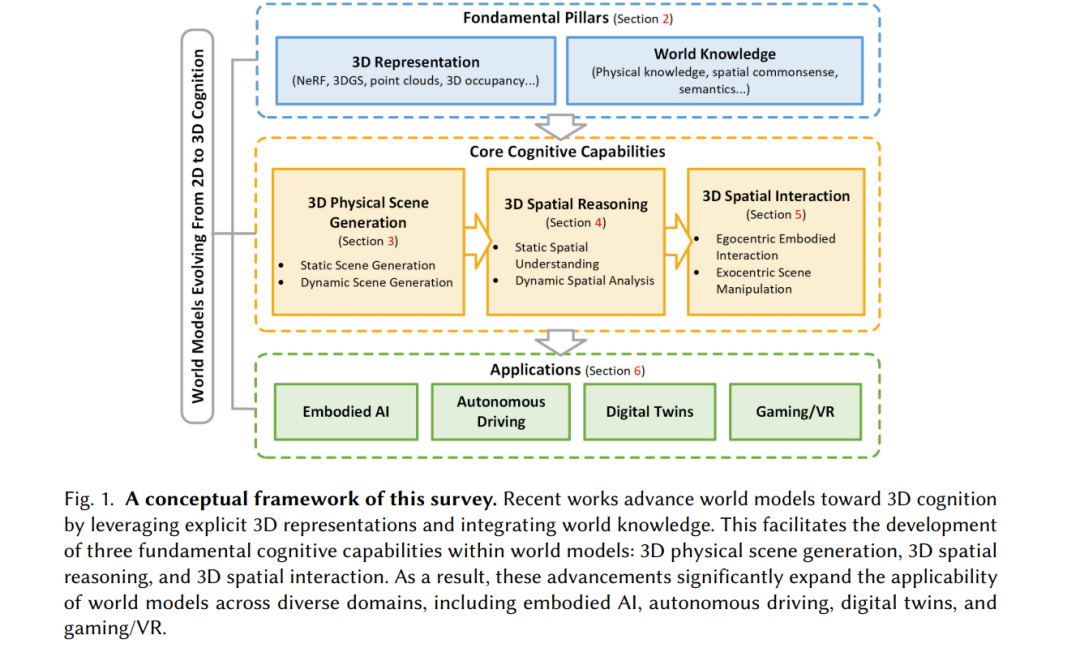
抽象推理与数据驱动生成构成了世界建模的两大主流技术路径,在二维视觉表征与预测方面各有优势。JEPA/V-JEPA 擅长任务分解与逻辑推理,而 Sora 在二维视频拟合与生成多样性方面表现出色。然而,在处理三维环境中的运动模拟、物理交互与因果推理方面,两者均面临瓶颈。JEPA/V-JEPA 的分层编码器舍弃了低层几何细节以提升推理效率,导致在动态遮挡场景中的表现退化 [152];Sora 则仅学习像素级相关性,缺乏显式三维结构,限制了其模拟复杂物理动态或推理空间因果关系的能力。 与此同时,在具身智能体、自动驾驶与数字孪生等应用中,对精确三维场景构建、理解与交互的需求持续增长,推动三维生成建模加速发展。2024 年,World Labs 与 Google 推出从单张图像生成可交互三维场景的模型 [113, 117, 179, 180]。尽管这些模型在几何可行性上取得进展,但仍难以提供物理上合理的语义解释与响应式交互。这一缺口促使学术界与产业界共同迈向基于显式空间表征与认知先验的世界模型,作为下一个关键发展方向。 如图 1 所示,本文提出一个概念框架,围绕两项构建空间认知能力的基础组成展开世界模型的发展路线: * 三维表征的采用:以体积形式捕捉几何结构、辐射信息与空间构型; * 世界知识的引入:包括物理规律、空间常识、语义与结构先验,为世界建模提供上下文语境。
基于上述两个支柱,框架进一步界定了三项构成世界模型认知核心的能力: * 三维物理场景生成:使模型能够重建与合成符合物理可行性的体积环境,保证几何保真与动态真实; * 三维空间推理:在几何计算与语义先验/常识知识的结合下,推理空间关系、对象语义/功能与环境动态,引导规划与决策; * 三维空间交互:使模型具备目标导向、物理一致的交互能力,包括具身智能体行为与用户驱动的编辑,使其从被动观察者转变为三维环境中的主动参与者。
这一能力三元组呼应了智能系统常用的“感知–思维–行动”循环 [136],也为后续在具身智能、数字孪生、自动驾驶与游戏/虚拟现实等四大关键应用领域的调研与评估提供组织原则。
1.3 与现有综述的比较
为突出本文综述的独特视角,表 1 从基础聚焦、能力覆盖与主题强调等方面对比了已有综述工作。现有文献多集中于多模态学习 [102]、物理视频合成 [88] 或生成模型的维度扩展 [58] 等子领域,关注点往往局限于渲染真实感或抽象结构建模。例如 Ding 等(2024)[30] 按照状态表征与未来预测维度对世界模型进行分类,但较少涉及显式体积表征与主动交互等方面。相比之下,本文综述从三维认知视角出发,提供统一且系统的分析框架,从三维表征与世界知识两个支柱出发,系统梳理三项核心空间能力:三维物理场景生成、三维空间推理与三维空间交互。
1.4 文章结构
为系统探讨上述组成与能力,本文余下部分组织如下: * 第 2 节介绍三维世界建模的两项基本支柱:三维表征与世界知识; * 第 3、4 与 5 节分别深入探讨三项核心认知能力:三维物理生成、三维空间推理与三维空间交互; * 第 6 节展示这些能力在具身智能、自动驾驶、数字孪生与游戏/虚拟现实等关键领域中的应用; * 第 7 节总结当前挑战与未来方向,展望通用三维世界认知的发展路径。