干货 | 阿里巴巴机器智能实验室线下智能团队三年工作总结

AI 科技评论按,从 2016 年至今,阿里巴巴机器智能实验室线下智能团队开始涉足线下智能领域。探索至今,算法方面,他们提出了自主研发的模型压缩方法,新型模型结构和目标检测框架;工程方面,他们研发出一套非数据依赖的量化训练工具,并且针对不同硬件平台,研发了高效推理计算库;同时,他们也和服务器研发团队一起抽象出了一套软硬件产品化方案,以服务多样的业务形式,并在真实业务场景中实验落地。
在今天这篇文章中,阿里翎翀将从算法探索、训练工具、推理框架、产品化和业务模式等方面对此前的工作做出总结和分享,正文如下,雷锋网AI 科技评论获其授权转载。
算法探索
基于 ADMM 的低比特量化
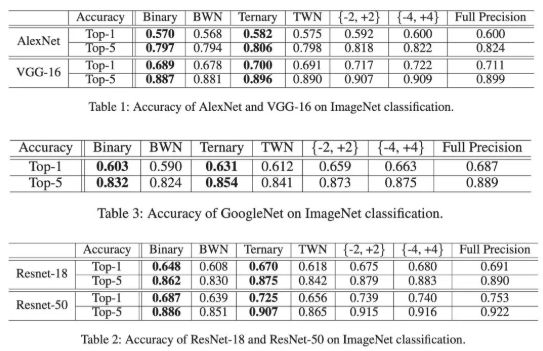
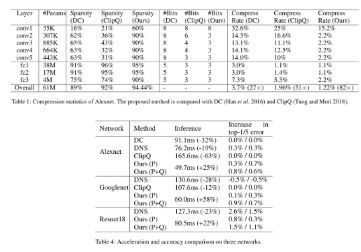
低比特量化是模型压缩( ModelCompression)和推理加速(Inference Acceleration)中一个核心的问题,目的是将神经网络中原有的浮点型参数量化成 1-8Bits 的定点参数,从而减小模型大小和计算资源消耗。为了解决这个问题,我们提出了基于 ADMM(Alternating Direction Method ofMultipliers)的低比特量化方案。在公开数据集 ImageNet 上,我们在 Alexnet,ResNet-18,Resnet-50 等经典 CNN 网络结构上做了实验,无论是精度上还是速度上均超过了目前已知的算法。我们可以在 3-bit 上面做到几乎无损压缩。目前该方法已经被广泛应用到各种端上目标检测和图像识别的实际项目中。相关成果已经在 AAAI 2018 上发表。
统一量化稀疏框架
量化技术可以通过简化计算单元(浮点计算单元->定点计算单元)提升推理速度。稀疏化( Pruning ) 技术则是通过对神经网络中的通路进行裁剪来减少真实计算量。我们很自然的将这两个技术融合到了一起,来获取极限的理论加速比。在剪枝过程中,我们采用了渐进式的训练方法,并结合梯度信息决定网络中路径的重要程度。在 ResNet 结构上,我们可以做到 90% 稀疏度下的近似无损压缩。
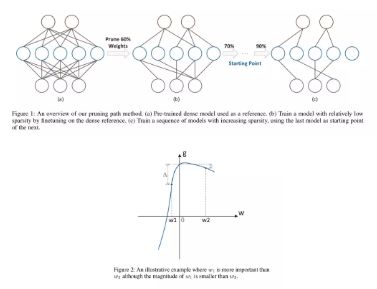
在稀疏化研究过程中,我们发现了一个问题,更细粒度的裁剪往往会获得更高的精度,但是代价是牺牲了硬件友好性,很难在实际应用中获得理论加速比。在后面的章节中,我们会通过两个角度来解决这个问题:
软硬件协同设计,从软硬件角度同时出发解决问题;
新型轻量级网络,从软件角度设计更适合现有硬件的结构。
软硬件协同网络结构
通过量化和稀疏技术,我们可以获得一个理论计算量足够低,所需计算单元足够简单的深度网络模型。下一个要解决的问题就是我们如何将其转换成一个真实推理延时低的算法服务。为了挑战极限的推理加速效果,我们和服务器研发团队一起,从软硬件联合设计出发解决该问题。在该项目中,我们提出了以下几个创新点,其中包括:
软硬件协同设计方面,我们针对硬件物理特性提出了异构并行分支结构,最大化并行效率。
算法方面,我们利用量化、稀疏、知识蒸馏等技术,将理论计算量压缩到原始模型的 18%。
硬件方面,我们通过算子填充技术解决稀疏计算带来的带宽问题,利用算子重排技术平衡 PE 负载。
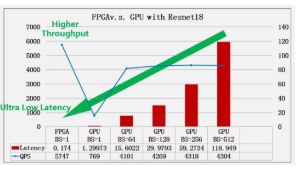
通过上述方案,我们只需要 0.174ms 的 latency 就可以完成 resnet-18 复杂程度的模型推理,达到业内最佳水平。该方案在对 latency 敏感的领域具有极大的优势。相关成果已经在 HotChips 30 上展出。
新型轻量级网络
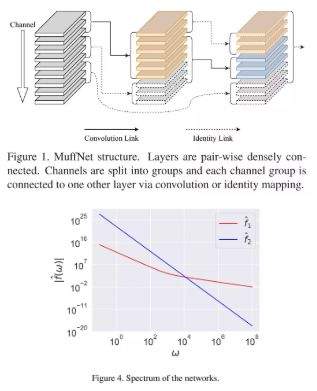
软硬件协同设计是一个非常好的推理解决方案,但是改方案的开发成本和硬件成本都很高。某些特定的场景对于 latency 和 accuracy 的容忍度比较高(例如人脸抓拍)。为了解决这类需求,我们提出了一种多联合复用网络(Multi-Layer Feature Federation Network, MuffNet),该结构同时具有 3 个特点:
稀疏的拓扑结构,同时更容易获取高频响应;
密集的计算节点,保证硬件友好性;
针对低成本硬件充分优化,小计算量下精度提升更明显;
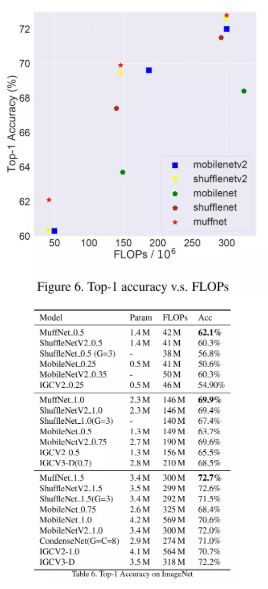
我们提出的新型网络由于每个单元的计算比较密集,并不存在过多的碎片操作,是非常适合在通用硬件上运行的。在公开数据集 ImageNet 上,我们在 40MFLops 计算量上相比目前业内最优的 shufflenet v2 结构,准确度提升了 2%。
端上目标检测框架
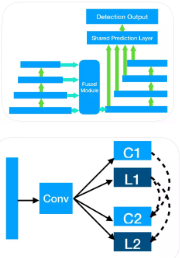
相比图像识别类任务,目标检测类任务的适用场景更广泛。高效的目标检测框架具有很高的研究价值。针对端上场景,我们提出了一个 LRSSD 框架(light refine single short multiboxdetector),该框架包括以下几个特点:
简化 SSD HEAD,采用共享预测层设计特征融合模块;
融合不同尺度下信息级联形式的 bbox 回归;
对检测模型做全量化处理。
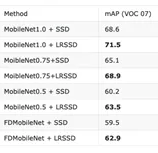
如上表所示,相同 backbone 网络的情况下,我们提出的 LRSSD 在减少 SSD HEAD 计算量的同时,mAP 可以稳定提升3%-4% 。从另一个角度来看,在保证检测精度不变的情况下,我们的方法可以将模型复杂度减少到原来的 50% 左右。如果再考虑到量化带来的速度加成,在相同精度下,相比原有全精度模型,我们可以获得共约 2-3 倍的真实速度提升。
小结
上文给出了我们近 2 年内在线下智能—模型压缩领域所做的一些技术积累。归纳起来如下:
量化方面:我们可以做到 3-bit 量化几乎无损压缩!
稀疏方面:对于传统网络结构,我们可以做到 90% 稀疏度下的几乎无损压缩!
软硬件协同设计方面:我们联合服务器研发团队,达到 0.174ms/张的 resnet18 极限推理速度,目前已知业内最佳效果!
轻量级网络设计方面:我们在 40MFlops 计算量下,相对目前业内最好结构,在 ImageNet 数据集上绝对提升 2%!
端上目标检测方面,我们在保证精度不变的情况下,速度提升约 2-3 倍!
在技术探索的同时,我们也在积极的将上述技术应用到实际的业务中。在这一过程中我们发现了下列几个问题:
易用性:业务场景往往需要快速的迭代能力和灵活方便的部署能力,因此非标准化的方案很难被广泛应用。
理论速度 vs 真实速度: 除了算法和硬件以外,真实的模型推理速度是需要一个高效的工程实现作为支撑的。
集成化 :线下智能需要同时考验团队在硬件和软件两方面的实力,这对业务而言往往太过沉重。
在本文后半部分,我们首先会针对上述的几个问题介绍我们已经做过的尝试和沉淀出的解决方案。最后,我们列出了一些实例,展示如何在具体的业务场景中应用线下智能技术,希望可以给各位同学一个更直观的认识。
训练工具
在实际业务推广过程中,我们遇到的第一个问题是易用性问题:
不同业务往往使用的深度学习库多种多样,例如 Caffe, Tensorflow, Mxnet 等等;
不同业务使用的基础技术差异比较大,有分类识别、检测、分割、语音等等;
不同业务的数据安全级别差异比较大,有些可以公开,有些则需要完全物理隔离;
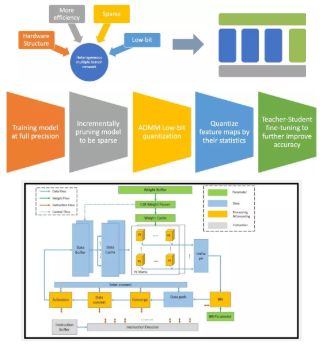
为了让更多的场景都可以用上我们的服务,获得 AI 的红利,我们提出了一套标准化的量化训练工具。
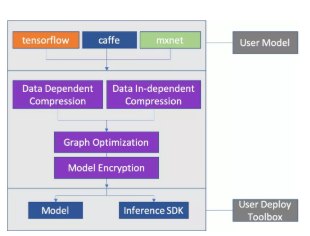
如上图所示,首先,我们的工具输入支持多种模型格式(TensorFlow,Caffe,Mxnet 等)。其次,我们提供了两种不同的模型量化方法,一种是支持不同任务(分类,检测,分割等)的数据依赖型压缩方法(Data Dependent Compression),适用于对数据安全要求不是很高,希望追求精度最大化的业务;另一种是数据非依赖压缩方法(Data Independent Compression),适用于对数据安全要求高,或者业务逻辑不是特别复杂的场景。
最后,在量化工作完成后,我们的工具会自动完成推理图的优化和模型加密,生成可以实际部署的模型文件。配合对应的推理加速库即可在端上运行。从易用性和数据安全性角度出发,我们推荐使用数据非依赖性的压缩方法。
目前,该套工具作为 MNN 推荐的量化工具广泛应用在阿里集团内多个线下业务场景中。
推理框架
实际中遇到的第二个问题就是真实推理速度问题,毕竟光有易用性是不够的,实打实的业务效果才是业务最想要的。这里我们使用阿里集团其他的兄弟团队提供的推理框架:
ARM 架构: 我们采用淘系技术团队研发的 MNN 作为推理框架;
GPU 架构: 我们采用机器智能技术团队研发的 falcon_conv 卷积库作为推理框架;
FPGA 架构:我们采用服务器研发团队研发的推理框架。
MNN
MNN 是一个轻量级的深度学习端侧推理引擎,核心解决深度神经网络模型在端侧推理运行问题,涵盖深度神经网络模型的优化、转换和推理。目前,MNN 已经在手淘、手猫、优酷、聚划算、UC、飞猪、千牛等 20 多个 App 中使用。选用常见的深度神经网络模型 MobileNet V2 和 SqueezeNet V1.1 作为测试样本:Android 方面,以小米 6 为例,MNN 在 CPU 和 GPU 上领先业界至少 30%;iOS 方面,以 iPhone 7 为例,MNN 在 CPU 和 GPU 上领先业界至少 15%。
FPGA
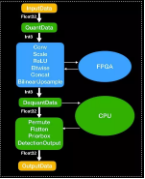
FPGA 上的推理框架由服务器研发团队完成。ResNet18 网络的推理时间只需要 0.174ms,目前已知业内最佳性能。在边缘计算产品 alibabaedge 上,基于硬件实现的高效算子,推理速度为边缘 GPU 的两倍。在后面,我们会结合产品形态整体的介绍这一方案。
GPU
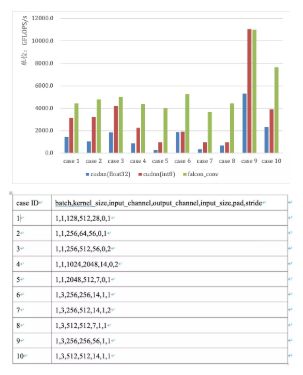
falcon_conv 是机器智能技术团队开发的一款由 CUDA C++编写,在 Nvidia GPU 上运行的低精度卷积库,它接受 2 份低精度(INT8)张量作为输入,将卷积结果以 float/int32 数据输出,同时支持卷积后一些常规操作(scale,batchnorm,relu… )的合并。我们在单张 Tesla P4 GPU 上,对 falcon_conv 的性能与 Nvidia 官方计算库 Cudnn v7.1 做了比较,如图所示。几乎所有情况 falcon_conv 都优于 Cudnn,个别用例有高至 5 倍的提升,用例选自 RESNET 和 VGG 中耗时较多的卷积参数。
产品化
在业务支持过程中我们遇到的第三个问题是集成化,产品化问题。除了手机类场景外,其他线下业务均需要额外的硬件平台作为支撑。在早先时候,我们更多的是依赖第三方提供的硬件设备,这时候成本,稳定性,可扩展性成为制约线下项目拓展的几个主要问题。为了解决这些问题,我们根据以往的项目经验,对硬件设备进行归纳,沉淀出两类比较通用的线下产品化方案:智能盒子和一体化相机。每类产品均包含不同型号,以适应不同需求的场景。
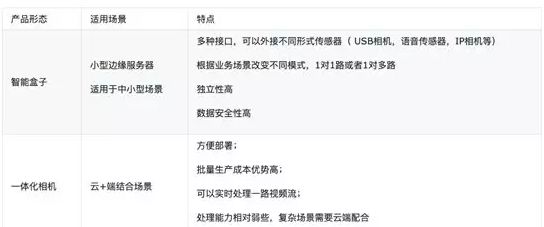
智能盒子
我们提供的第一个方案为智能盒子方案。我们可以简单的把智能盒子当作一个适合于中小型场景的边缘服务器。盒子本身提供了多种接口,可以外接 usb/ip 相机,语音模块等传感器。直接本地部署,数据安全性高。我们针对业务特点提供了高低两个版本的智能盒子。其中,高端版本采用阿里巴巴自研的边缘计算产品 Alibaba Edge。除了完善的硬件设计和高效的推理框架,该盒子还包含完善的编译器支持,具有非常好的易用性。低端版本则为纯 ARM 的盒子。下面表格给出这两种盒子在性能,成本和适用场景的一个对比。
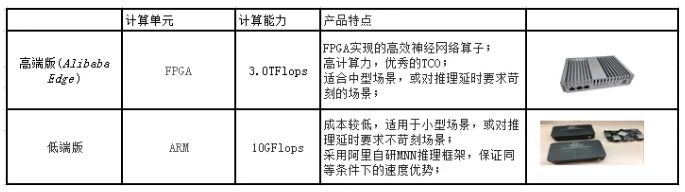
在这里我们着重介绍一下阿里巴巴自研的边缘计算产品 Alibaba Edge,该产品除了具有高达 3TGFlops 的 AI 计算能力外,相对边缘 GPU 方案有大幅的价格优势,同时具有云端一体化部署功能,产品平台化,可快速上线,支持大规模运维。

在下面的表格中,我们对比了 LRSSD300+MobileNetV2 在不同硬件设备上的运行时间,希望可以给大家一个更直观的认识。

一体化相机
我们提供的另一个集成方案为一体化相机。一体化相机特别适合云+端的部署模式:线下做相对比较简单的处理功能,云端则深度处理线下传回的信息,达到节约带宽,降低云成本的作用。同时,一体化相机具有方便部署,批量化生产后成本优势高的特点。目前一体化相机已经作为一个重要的载体形式被应用到我们所承接的对集团外合作项目中。
业务合作
在过去的 2 年间,我们尝试过多种不同的业务模式。在这里我们会列出主要几个不同形式的实例。
菜鸟未来园区
在菜鸟未来园区项目中,我们主要负责基础视觉类算法的输出,由菜鸟智慧园区团队同学负责业务算法和工程服务研发工作。经过半年的共同努力,我们先后完成了离岗睡岗检测,消防通道异常检测,车位占用检测,行人越界检测,入口计数检测等多个功能。

在项目合作的过程中,我们发现计算单元成本高是制约算法大范围推广的一个主要原因。为了解决这个问题,我们联合了服务器研发团队,开发出一版定制化软硬件解决方案:该方案的硬件平台为我们在上文中提到的边缘计算产品 Alibaba Edge,同时配备特别定制的高效模型结构和自研的快速检测算法。新版方案在检测精度几乎无损的情况下,推理速度提升了 4-5 倍,成本相比边缘 GPU 方案下降了 1/2。
模型压缩加速
我们协助阿里集团不同业务同学完成对已有算法模型的量化瘦身与加速工作。例如:手机端 OCR 识别、手机端物体检测、手淘实人认证和刷脸登录/验证、菜鸟自提柜、阿里体育赛事刷脸入场、神州鹰人脸识别云相册等。
总结与展望
经过近两年的努力,机器智能技术实验室线下智能团队深耕线下智能领域。
算法方面:我们在低比特量化、稀疏化、软硬件协同设计、轻量级网络设计、端上目标检测等多个方面取得了一定的积累,多项指标达到了业内最佳水平。
工程方面:我们积累出了一套高灵活性,高数据安全性的训练工具 ; 并在合作伙伴的帮助下,在 ARM,FPGA,GPU 等多个平台下达到了业内最佳的推理性能。
产品化方面:我们与合作伙伴一起,研发出适合于不同业务场景的智能盒子与一体化相机。
最后,我们很幸运可以在集团内外多个不同形式的业务场景内打磨我们的技术。
2019 全球人工智能与机器人峰会
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

点击阅读原文,查看 阿里巴巴开源深度学习框架 X-Deep Learning,引领高维稀疏数据场景的深度学习标准



