【NeurIPS2022】分布式自适应元强化学习

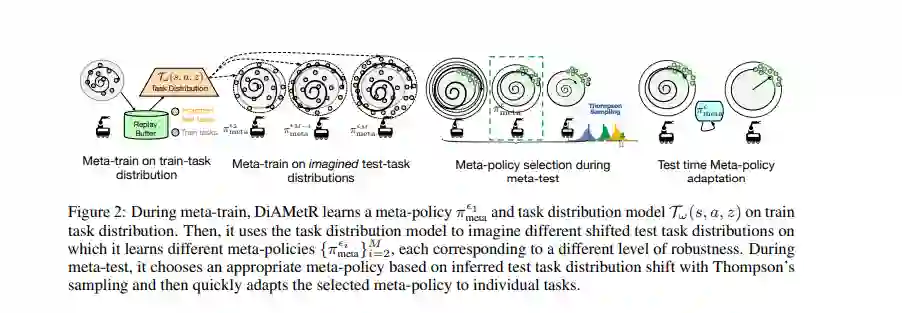
元强化学习算法提供了一种数据驱动的方法来获得快速适应许多具有不同奖励或动态功能的任务的策略。然而,学习到的元策略通常只在它们被训练的确切任务分布上有效,并在测试时间奖励的分布变化或过渡动态的存在下很困难。本文为元强化学习算法开发了一个框架,能够在任务空间的测试时分布变化下表现适当。我们的框架以一种适应分布鲁棒性的方法为中心,它训练一组元策略对不同级别的分布转移具有鲁棒性。当在可能发生变化的任务测试时分布上进行评估时,这使我们能够选择具有最适当鲁棒性水平的元策略,并使用它来执行快速自适应。我们正式地展示了我们的框架如何允许改进分布位移下的遗憾,并实证地展示了它在广泛分布位移下的模拟机器人问题上的有效性。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DAMR” 就可以获取《【NeurIPS2022】分布式自适应元强化学习》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年11月22日
Arxiv
0+阅读 · 2022年11月22日

相关VIP内容
相关资讯