【NeurIPS2022】通过模型转换的可解释强化学习

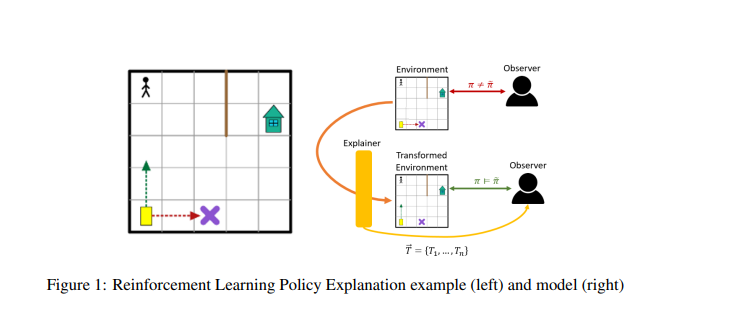
理解强化学习(RL)智能体的新出现行为可能是困难的,因为此类智能体通常在复杂环境中使用高度复杂的决策程序进行训练。这导致了强化学习中各种可解释性方法的产生,这些方法旨在协调智能体的行为和观察者预期的行为之间可能出现的差异。最近的大多数方法都依赖于领域知识(这可能并不总是可用的),依赖于对智能体策略的分析,或者依赖于对底层环境的特定元素的分析(通常建模为马尔可夫决策过程(Markov Decision Process, MDP))。我们的关键主张是,即使底层的MDP不是完全已知的(例如,转移概率没有被准确地学习)或不是由智能体维护的(即,转移概率不是由智能体维护的)。,当使用无模型方法时),它仍然可以被利用来自动生成解释。出于这个目的,我们建议使用正式的MDP抽象和转换(以前在文献中用于加速搜索最优策略)来自动生成解释。由于这种转换通常基于环境的符号表示,它们可以表示预期和实际智能体行为之间差距的有意义的解释。我们正式地定义了这个问题,提出了一类可以用来解释突发行为的变换,并提出了能够有效地寻找解释的方法。我们将在一组标准基准上演示该方法。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TERL” 就可以获取《【NeurIPS2022】通过模型转换的可解释强化学习》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年11月22日
Quasi-stable Coloring for Graph Compression: Approximating Max-Flow, Linear Programs, and Centrality
Arxiv
0+阅读 · 2022年11月21日
Arxiv
0+阅读 · 2022年11月21日
Arxiv
0+阅读 · 2022年11月18日
Arxiv
10+阅读 · 2018年2月16日




相关VIP内容
相关资讯